

Admission control is the system in CockroachDB that prioritizes work during different types of node overload. In a properly sized cluster, where the work does not exceed the resource capacity, all work proceeds uninterrupted and effectively receives equal priority.
However, when individual nodes detect an excessive amount of work, the admission control system prioritizes work into different queues, ensuring that critical operations continue to run unimpeded while lower priority work is throttled. This provides cluster stability during overload – while this process is designed to buffer occasional overload, it is not a replacement for a properly provisioned cluster.
At the highest level, overload typically manifests itself as poor throughput and high query latency. Although these measures are important from a workload perspective, throughput and query latency are highly variable depending on the specific workload. Instead, the admission control system uses indicators of overload that can be generalized for any workload. There are three types of overload that the admission control system actively manages:
CPU
Storage
Replication
Let’s take a detailed look at each of these overload types, and how admission control minimizes the risk of them occurring.
CPU Overload
The admission control system considers two indicators of CPU overload: runnable goroutines per CPU and goroutine scheduling latency.
The Go language, in which CockroachDB is written, uses light-weight thread-like objects called goroutines to run operations in the Go runtime. An internal scheduler ensures that goroutines are run efficiently on the available CPU cores. When the number of runnable goroutines – those available to run on the CPU – exceeds 32 per CPU, the CPU is effectively saturated which leads to queuing within the Go scheduler.
If runnable goroutines per CPU is below 32, the admission control system remains inactive. However, above that threshold admission control starts queueing work by priority. Higher priority work gets processed at a higher rate than lower priority, and all work is subject to an internal queueing system to prevent CPU overload.
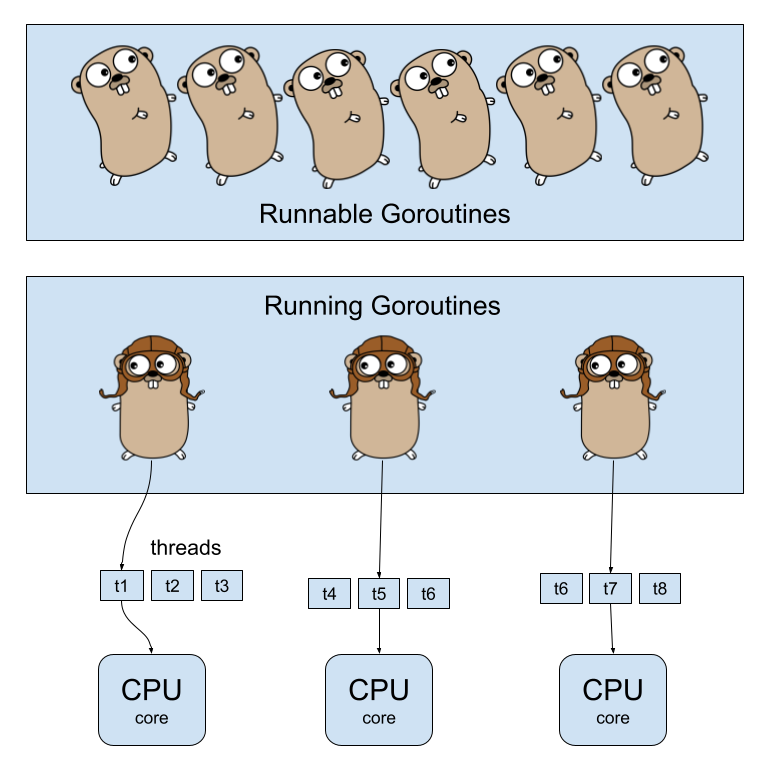
In Go, goroutines are queued in a “runnable” state prior to running on a CPU thread. The number of goroutines per CPU is an indicator of CPU overload used by admission control. (photo credit: https://github.com/keygx/Go-gopher-Vector)
CPU can also be overloaded even when the runnable goroutine per CPU count is low. How is this possible? This occurs when there is long-running work that is only using a small number of goroutines. Because it is long-running, it effectively prevents other goroutines from getting access to the CPU. Various background operations, such as backups, changefeeds and row-level Time to Live (TTL) can have this negative effect on CPU availability.
Instead of runnable goroutines per CPU, CPU utilization from long-running operations is better measured using goroutine scheduling latency. Goroutine scheduling latency is a measure of how long it takes for a goroutine to access the CPU when it is in a runnable state. There are two mechanisms that the admission control system uses to protect from this type of CPU overload:
First, it provides slices of CPU time to these processes and requires them to request additional slices as they run.
Second, it limits the % of CPU that background processes can access and lowers that limit when the CPU is overloaded with high scheduling latency.
The combination of these two approaches minimizes impact on foreground workload.

Long-running operations with no particular core affinity, lead to higher scheduling latency (source: https://www.cockroachlabs.com/blog/rubbing-control-theory/)
Storage Overload
When folks think about storage overload, they often picture metrics such as disk throughput in megabytes per second (Mbps), operations per second (OPS) or disk queue lengths. However, these metrics can vary widely based on the disk types and configurations that are used. From the CockroachDB perspective, storage overload can be detected more generally by the health of the log structured merge tree (LSM) which is the structure used by the Pebble storage system.
The underlying storage is an LSM that is represented by a structure with multiple levels. In-memory data is initially written to the first level, called L0, then gets compacted, or merged, down to lower levels. L0 is unique in that data can have overlapping spans, which makes it more efficient for writes. However, it can become inefficient for reads if too much data accumulates in L0 prior to getting compacted to the lower levels.
L0 can have sub-levels – when a new file is created that overlaps with the spans of files in existing sub-levels, a new sub-level is created. Because L0 and L0 file counts and sub-levels, along with the flush throughput from memory to L0, are a good proxy for LSM health, the admission control system uses these indicators to determine when storage is overloaded.

Storage health is determined by the number of files and sub-levels in L0 of Pebble’s log structured merge tree.
During storage overload, the admission control system queues writes based on priority, similar to queuing of operations during CPU overload: Higher priority work runs before lower priority work. This ensures that the LSM remains healthy and the node does not experience performance degradation due to read amplification associated with high L0 file and sub-level counts.
Replication Overload
Most parts of the admission control system work strictly at the local node level. However, CockroachDB is a distributed system where activity on one node may impact other nodes. Although local node admission control is sufficient for most situations, replicated writes can have a negative impact on followers if they are not handled differently.
To understand replication overload, it is first necessary to understand how writes are replicated in CockroachDB. CockroachDB uses the raft protocol for distributed consensus. Each range, which is a contiguous chunk of data, has a raft group composed of a single leader and multiple followers. The leader is typically also the leaseholder for the range, which is responsible for coordinating writes. For a write to be considered durable, it must be replicated to a quorum of followers. Each follower then writes the changed data locally before acknowledging the write to the leaseholder.
Prior to the release of CockroachDB 23.2, it was possible for replicated writes to overload the follower node in a way that admission control did not handle well. Admission control queues work based on priority, but there are certain operations that count against the rate budget but are not subject to throttling.
Replication writes was one of those areas: When a replicated write was received from a follower, it counted against the write budget and could starve out other writes. For example, a node often has follower replicas for many ranges but also is a leaseholder for other ranges. In some situations, the follower writes would consume the write budget and cause excessive queueing of the leaseholder writes.
To handle this situation, a replication flow control mechanism was introduced. The flow control mechanism dynamically adjusts the rate of flow tokens based on a fixed amount of tokens. When a follower falls behind and the flow tokens are exhausted, writes are throttled on the leaseholder to prevent overload on the follower. Like the other admission control mechanisms, this is designed to buffer unexpected overload in a sufficiently provisioned cluster. It is also effective during expensive background tasks, such as schema changes, that can produce significant resource usage. During this type of overload, admission control preserves normal throughput and latency for foreground workload by throttling the background work. If replication overload is encountered frequently during normal operation, it may be an indicator that additional resources should be provisioned for the cluster.
Conclusion
The admission control system in CockroachDB provides protection during node overload in three key areas: CPU, Storage and Replication. However, it is designed to provide temporary protection, ensuring that critical cluster operations continue while other work is properly paced. It also minimizes the impact of lower priority work, such as backups, changefeeds, and row-level TTL, when a node is under heavy load.
Further Reading
This article provides a high-level overview of the types of protections that the admission control system provides. There are additional resources that provide further details about the admission control system, including how it works, what specific metrics to monitor, what operations are subject to admission control, and what to do if admission control is frequently throttling workload.
For a deeper technical understanding, the following blog posts were written by engineers that designed and developed the CockroachDB Admission Control system:
“Here's how CockroachDB keeps your database from collapsing under load” (Sumeer Bhola, June 6 2022)
“Rubbing control theory on the Go scheduler” (Irfan Sharif, December 15 2022)
The official CockroachDB documentation is a valuable resource, as well:


