
CockroachDB is an excellent system of record, but no technology exists in a vacuum. Some of our users would like to keep their data mirrored in full-text indexes to power natural language search. Others want to use analytics engines and big data pipelines to run huge queries without impacting production traffic. Still others want to send mobile push notifications in response to data changes without doing the bookkeeping themselves.
At CockroachDB we want to make each of those use cases possible while ensuring data consistency and synchronicity.
The industry standard solution for this is Change Data Capture, commonly abbreviated as CDC. Change data capture is the process of capturing changes made at the data source and applying them throughout the entire system.
What is change data capture in ETL?
Each database’s approach to CDC is a little different, but change data capture generally looks like a stream of messages, each one containing information about a data change.
CDC minimizes the resources required for ETL ( extract, transform, load ) processes because it deals *only* with data changes: it provides efficient, distributed, row-level change feeds into a configurable sink for downstream processing such as reporting, caching, or full-text indexing. In CockroachDB, we call our change data capture process a changefeed.
What is change data capture in SQL?
A CockroachDB CHANGEFEED is a real-time stream of the changes happening in a table or tables. As SQL statements execute and alter the stored data, messages are emitted to an external system which we call a “sink”. Executing INSERT INTO users (1, "Carl"), (2, "Petee") might send {"id": 1, "name": "Carl"}` and `{"id": 2, "name": "Petee"}.
We could support emitting directly to everything we want to work with, and that may eventually happen, but this involves a client driver and performance tuning for each one. Instead, we emit to a “message broker”, which is designed to be an intermediary for exactly this sort of thing. User feedback led us to select Kafka as the first to support.
Why do we need change data capture?
The role of change data capture is to ensure data durability and consistency. The biggest challenge in building CDC changefeeds for CockroachDB was clear right from the start. We needed our changefeeds to keep our strong transaction semantics, but we also wanted them to scale out horizontally.
In a single node database, this is conceptually easy. Every database I know of uses a Write Ahead Log (WAL) to handle durability (the D in ACID) in the face of disk failure or power loss. The WAL itself is simply an ordered log on disk of every change, so the work of building a changefeed mostly becomes exposing this log in a sensible way. In fact, Postgres has a plugin system for tailing the WAL and the various changefeed implementations for Postgres are implemented as these plugins. Other databases work similarly.
CockroachDB, however, has a unique distributed architecture. The data it stores is broken up into “ranges” of about 64MB. These ranges are each duplicated into N “replicas” for survivability. A CockroachDB transaction can involve any or all of these ranges, which means it can span any or all of the nodes in the cluster.
This is in contrast to the “sharded” setup used when horizontally scaling other SQL databases, where each shard is a totally independent replicated unit and transactions cannot cross shards. A changefeed over a sharded SQL cluster is then simply a changefeed per shard, typically run by the leader of the shard. Since each transaction happens entirely in a single shard, there’s little benefit to the changefeed worrying about the relative ordering of transactions between shards. It also means the individual shard feeds are perfectly parallelize-able (one Kafka topic or partition per shard is typical).
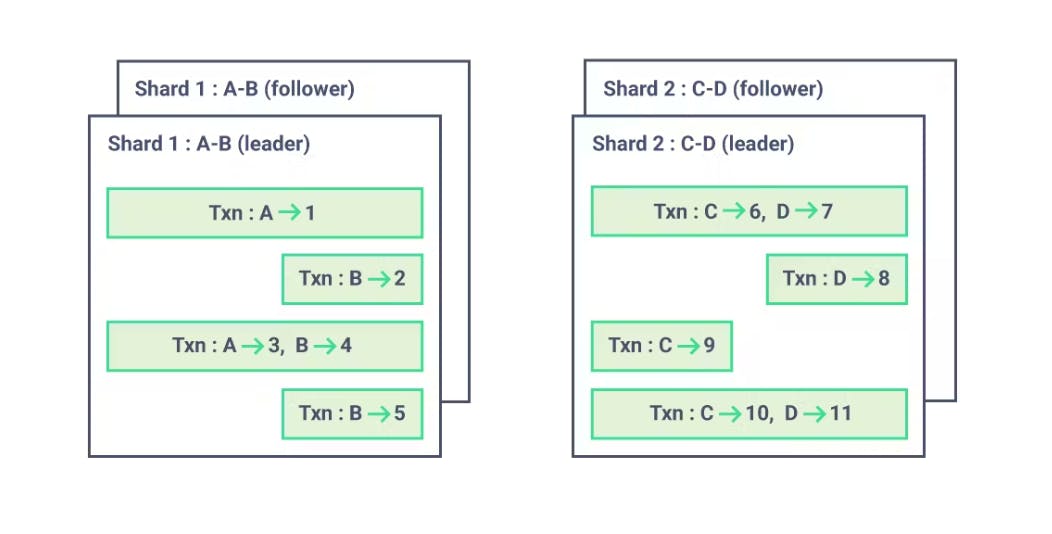
Figure 1: Transactions in a sharded SQL database can’t cross shards. This means it’s easy to form independent streams of ordered transactions; each shard leader’s WAL is already exactly this. (Consider reading: Why sharding is bad for business.)
Since a CockroachDB transaction can use any set of ranges in the cluster (think cross-shard transactions), the transaction ordering is much more complicated. In particular, it’s not always possible to partition the transactions into independent streams. The easy answer here is to put every transaction into a single stream, but we weren’t happy with that. CockroachDB is designed to scale horizontally to large numbers of nodes, so of course we want our changefeeds to scale horizontally as well.
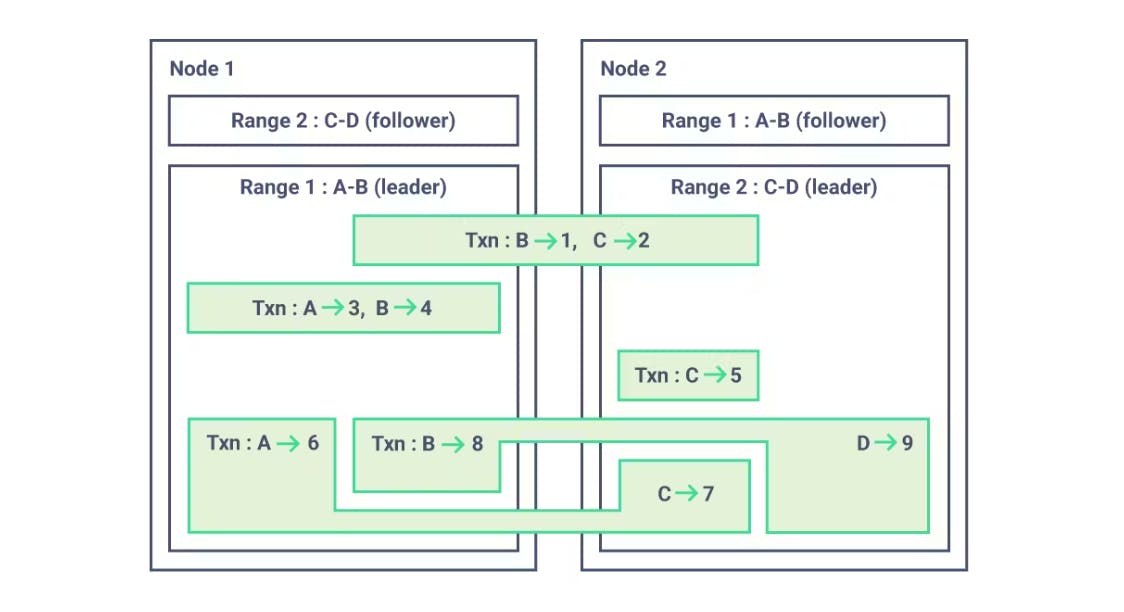
Figure 2: Transactions in CockroachDB can cross nodes. The (A->6,C->7) and (B->8,D->9) transactions are not possible in a sharded SQL database. This means the only way to have a fully ordered stream of transactions is to have a single stream, which would limit horizontal scalability. Note that the (A->3,B->4) and (C->5) transactions are independent, but both overlap the other transactions, so even these can’t be partitioned.
CDC and changefeeds and RangeFeeds
A SQL table in CockroachDB can span many ranges, but each row in that table is always contained by a single range. (The row can move when a range gets big and the system splits it into two as well as when the range gets small and the system merges it into a neighboring range, but these can be handled separately.) Further, each range is a single raft consensus group and thus has its own WAL that we can tail. This means that we can produce an ordered stream of changes to each SQL row. To power this, we developed an internal mechanism to push these changes out directly from our raft consensus, instead of polling for them. It’s called RangeFeed. Rangefeeds are a long-lived request which changefeeds can connect to for pushing changes as they happen. This reduces the latency of row changes, as well as reduces transaction restarts on tables being watched by a changefeed for some workloads. (Rangefeeds are a big enough topic for a blog post all their own, so I won’t go into detail here, but there is plenty more information in the CockroachDB docs.
Each of the row streams is independent, which means we can horizontally scale them. Using our distributed SQL framework, we colocate the processor that emits row changes next to the data being watched, which eliminates unnecessary network hops. It also avoids the single point of failure we’d have if one node did all the watching and emitting.
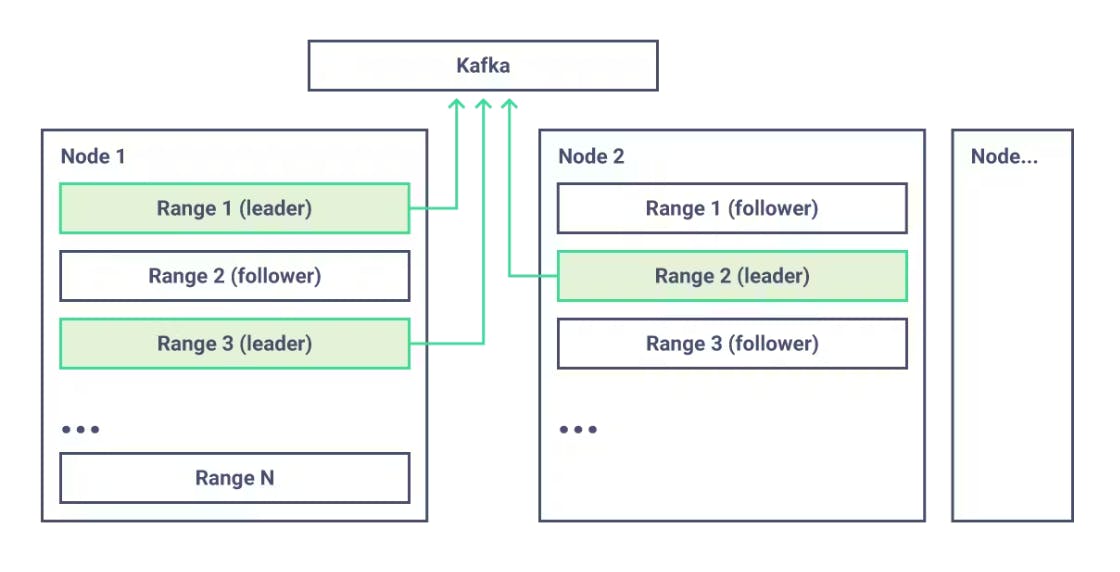
Figure 3: CockroachDB range leaders each emit changes directly to Kafka (or other sink).
For many changefeed uses, this is enough; a mobile push notification can be triggered by each message and some datastores don’t support transactions. Ordered row streams work great for both of these.
For other uses, it’s not enough; a mirror of data into an analytics database certainly doesn’t want to apply partial transactions.
Every CockroachDB transaction already commits each row change with the same HLC timestamp. Exposing this timestamp in each message for a changed row is enough to get transaction information back (group rows by timestamp)[[1]](https://www.cockroachlabs.com/blog/change-data-capture/#footnotes) as well as a total ordering (sort rows by timestamp). Building on top of our existing transaction timestamps means that our changefeeds have the same serializability guarantees as everything else in CockroachDB.
The final piece is knowing when to do this group or sort. If a changed row is emitted with time hlc1 from one CockroachDB node, how long do you have to wait to make sure none of the other nodes have changes at hlc1 before acting on it?
We solve this with a concept we call a “resolved” timestamp message. This is a promise that no new row changes will be emitted with a timestamp less or equal to the one in the resolved timestamp message. This means the above user can act on hlc1 after receiving from each node[[2]](https://www.cockroachlabs.com/blog/change-data-capture/#footnotes) a resolved timestamp >= hlc1.

Figure 4: One possible ordering of the first few messages emitted for the transactions in Figure 3.
In figure 4, imagine that two independent streams have each been read through the X. hlc1 has been resolved on one stream, but not the other, so nothing is resolved yet.
Now imagine that at some later point, messages have been read through Y. Both streams have resolved hlc1, so we know that we have received all changes that have happened up to and including hlc1. If we group the messages by timestamp, we can get the transactions back. In this case, only (B->1,C->2), which committed at hlc1. This transaction could now be sent to an analytics database.
Note that the (A->3) change happened at hlc2 and so is not yet resolved. This means the changefeed user would need to continue buffering it.
We can also reconstruct the state of the database at any time up to and including hlc1 by keeping the latest value seen for each row. This even works across ranges and nodes. In this case, at time hlc1 the database was B=1,C=2.
Finally, imagine some later time when all messages up through Z have been read. Going through the same two processes again gets us the transactions and state of the database. In this case, transaction (A->3,B->4) committed at hlc2 and (C->5) committed at hlc3. At hlc3 the database contained A=3,B=4,C=5. Note that we can also reconstruct the database at hlc2 if necessary.
Whenever I explain this all now, it seems so obvious, but it’s one of those ideas that is only obvious in retrospect. (At least to us.) In fact, the aha! moment came from a discussion with a fellow engineer about a really interesting paper on distributed incremental computation which included the idea of adding data to a system with a certain timestamp and periodically “closing” that timestamp (a promise that you won’t later introduce new data with a timestamp <= the closed timestamp). This allows the incremental computation to finish out everything up to that timestamp and there was no reason we couldn’t use the same idea in CockroachDB. As an aside, one of our engineers was excited enough about this paper that he recently left to co-found materialize.io and build a company around it with one of the paper’s authors.
CDC message broker options
So far we’ve talked about the Kafka message broker, but this is not the only sink we support. Many popular analytics databases, including Google BigQuery, Snowflake, and Amazon Redshift support loading data from cloud storage. If this the only thing a user needs CDC for, there’s no reason they should need to run Kafka in the middle, especially if they weren’t already using it elsewhere.
There are many message broker options beyond Kafka. We’ll add first-class support for them as demand dictates, but in the meantime, we also support HTTP as a sink. HTTP plus JSON (our default format) is the lingua franca of the internet, so this makes it easy to glue CockroachDB changefeeds to anything you can imagine. Some of the ideas we’ve had include message brokers we don’t support yet as well as “serverless” computing, but we’re even more excited about the ones our users will think up.
Finally, for users of CockroachDB Core, we’ve provided a new [CHANGEFEED FOR](https://www.cockroachlabs.com/docs/stable/changefeed-for) statement that streams messages back over a SQL connection. This is similar in spirit to RethinkDB’s changefeeds (which are much beloved by their community). We don’t (yet) let you use them as a source of data in queries like RethinkDB does, but there’s no reason we couldn’t add this in the future.
These three sinks are initially being exposed in our 19.1.0 release as experimental features so we can make sure we get the APIs just right before committing to them.
Does change data capture affect performance?
CockroachDB’s SQL language is one that has decades of history. This means that for most features, we already have strong precedent for what the user-facing external surface area should look like. But occasionally our unique distributed architecture means that we get to blaze a bit of new trail, and our changefeeds are one example of that.
Using change data capture can impact the performance of a CockroachDB cluster. For example, enabling rangefeeds will incur a 5-10% performance cost, on average.However, the highly configurable nature of changefeeds allows you to balance additional performance costs (CPU, disk usage, SQL latency, etc) to achieve the desired changefeed behavior. To help guide you along this new trail, here is a very helpful post about how to customize and fine-tune changefeeds for performance and durability.
We think our approach makes the easy things truly easy (ordered row updates for push notifications and non-transactional datastores) while making hard things possible (horizontal scalability with strong multi-node transaction and ordering guarantees). We hope you agree. We’re actively looking for feedback, so try them out and let us know what you think!
\
More change data capture resources
• Learn when and why to use Change Data Capture
• See 8 different use cases for CDC transformations
• Learn how to send data to Azure Synapse with change data capture
• Tutorial for learning how to use Changefeeds in CockroachDB to track changes to a table and stream the change events to Apache Kafka
Footnotes
1: Well almost. Two transactions that don’t overlap can commit with the same timestamp, but they have nanosecond precision, so this is rare in practice. We also haven’t found anyone that needs more granularity than this, but if someone does we could expose our internal unique transaction IDs.
2: As always, the reality is slightly more complicated than this. A changefeed user doesn’t typically receive data directly from CockroachDB, instead receiving it from a message broker such as Kafka. This means resolved timestamps are actually scoped to Kafka partitions, not CockroachDB nodes.


