

In August, we published a blog post entitled “Why Can’t I Run a 100-Node CockroachDB Cluster?”. The post outlined difficulties we encountered stabilizing CockroachDB. CockroachDB stability (or the lack of) had become significant enough that we designated it a “code yellow” issue, a concept borrowed from Google that means a problem is so pressing that it merits promotion to a primary concern of the company. For us, the code yellow was more than warranted; a database program isn’t worth the bytes to store its binary if it lacks stability.
In this post, I’ll set the stage with some background, then cover hypotheses for root causes of instability, our communication strategy, some interesting technical details, outcomes for stabilization efforts, and conclusions. It’s a long post, so bear with me!
TL;DR: We achieved most of our stability goal. While we’re still working on some of the chaos scenarios, the system is easily stable at many more than 10 node clusters – we’ve tested it successfully at 100 nodes.
Background
To better set the stage: we announced the CockroachDB Beta release in April, after more than a year of development. Over the five months of progress on the beta, concerns over correctness, performance, and the general push for new features dominated our focus. We incorrectly assumed stability would be an emergent property of forward progress, just as long as everyone was paying some attention to, and fixing stability bugs whenever they were encountered. But by August, despite a team of 20 developers, we couldn’t stand up a 10-node cluster for two weeks without major performance and stability issues.
Nothing could more effectively convey the gulf that had opened up between our stability expectations and reality than the increasingly frequent mentions of instability as a punchline in the office. Despite feeling that we were just one or two pull requests away from stability, the inevitable chuckle nevertheless morphed into a insidious critique. This blog post chronicles our journey to establish a baseline of stability for CockroachDB.
Hypotheses on Root Causes
What caused instability? Obviously there were technical oversights and unexpectedly complex interactions between system components. A better question is: what was preventing us from achieving stability? Perhaps surprisingly, our hypotheses came down to a mix of mostly process and management failures, not engineering. We identified three root causes:
The rapid pace of development was obscuring, or contributing to, instability faster than solutions could be developed. Imagine a delicate surgery with an excessive amount of blood welling up in the incision. You must stop the bleeding first in order to operate. This analogy suggested we’d need to work on stability fixes in isolation from normal development. We accomplished this by splitting our master branch into two branches: the master branch would be dedicated to stability, freezing with the exception of pull requests targeting stability. All other development would continue in a develop branch.
While many engineers were paying attention to stability, there was no focused team and no clear leader. Imagine many cooks in the kitchen working independently on the same dish, without anyone responsible for the result tasting right. To complicate matters, imagine many of the chefs making experimental contributions… Time to designate a head chef. We chose Peter Mattis, one of our co-founders. He leads engineering and is particularly good at diagnosing and fixing complex systems, and so was an obvious choice. Instead of his previously diffuse set of goals to develop myriad functionality and review significant amounts of code, we agreed that he would largely limit his focus to stability and become less available for other duties. The key objective here was to enable focus and establish accountability.
Instability was localized in a core set of components, which were undergoing too many disparate changes for anyone to fully understand and review. Perhaps a smaller team could apply more scrutiny to fewer, careful changes and achieve what had eluded a larger team. We downsized the team working on core components (the transactional, distributed key-value store), composed of five engineers with the most familiarity with that part of the codebase. We even changed seating arrangements, which felt dangerous and counter-cultural, as normally we randomly distribute engineers so that project teams naturally resist balkanization.
Communication
The decision to do something about stability happened quickly. I’d come home from an August vacation blithely assuming instability a solved problem. Unfortunately, new and seemingly worse problems had cropped up. This finally provided enough perspective to galvanize us into action. Our engineering management team discussed the problem in earnest, considered likely causes, and laid out a course of action over the course of a weekend. To proceed, we had to communicate the decisions internally to the team at Cockroach Labs, and after some soul searching, externally to the community at large.
One of our values at Cockroach Labs is transparency. Internally, we are open about our stability goals and our successes or failures to meet them. But just being transparent about a problem isn’t enough; where we fell down was in being honest with ourselves about the magnitude of the problem and what it meant for the company.
Once decided, we drafted a detailed email announcing the code yellow to the team. Where we succeeded was in clearly defining the problem and risks, actions to be taken, and most importantly: code yellow exit criteria. Exit criteria must be measurable and achievable! We decided on “a 10-node cluster running for two weeks under chaos conditions without data loss or unexpected downtime.”
Where we didn’t succeed was in how precipitous the decision and communication seemed to some members of the team. We received feedback that the decision lacked sufficient deliberation and the implementation felt “railroaded”.
We didn’t decide immediately to communicate the code yellow externally, although consensus quickly formed around the necessity. For one thing, we’re building an open source project and we make an effort to use Gitter instead of Slack for engineering discussions, so the community at large can participate. It would be a step backwards to withhold this important change in focus. For another thing, the community surely was aware of our stability problems and this was an opportunity to clarify and set expectations.
Nevertheless, the task of actually writing a blog post to announce the stability code yellow wasn’t easy and wasn’t free of misgivings. Raise your hand if you like airing your problems in public… Unsurprisingly, there was criticism from Hacker News commentators, but there were also supportive voices. In the end, maintaining community transparency was the right decision and we hope established trust.
Technical Details
With changes to process and team structure decided, and the necessary communication undertaken, we embarked on an intense drive to address the factors contributing to instability in priority order. We of course had no idea how long this would take. Anywhere from one to three months was the general consensus. In the end, we achieved our code yellow exit criteria in five weeks.
What did we fix? Well, instability appeared in various guises, including clusters slowing precipitously or deadlocking, out-of-memory panics (OOMs), and data corruption (detected via periodic replica checksum comparisons).
Rebalancing via Snapshots
The generation and communication of replica snapshots, used to rebalance and repair data in a CockroachDB cluster, was our most persistent adversary in the battle for stability. Snapshots use significant disk and network IO, and mechanisms that limit their memory consumption and processing time while holding important locks were originally considered unnecessary for beta stability. Much of the work to tame snapshots occurred during the months leading up to the stability code yellow, which hints at their significance. Over the course of addressing snapshots, we reduced their memory usage with streaming RPCs, and made structural changes to avoid holding important locks during generation. However, the true cause of snapshot instability proved to be a trivial oversight, but it was simply not visible through the fog of cluster stabilization – at least, not until after we’d mostly eliminated the obvious symptoms of snapshot badness.
Snapshots are used by nodes to replicate information to other nodes for repair (if a node is lost), or rebalancing (to spread load evenly between nodes in a cluster). Rebalancing is accomplished with a straightforward algorithm:
1. Nodes periodically advertise the number of range replicas they maintain.
2. Each node computes the mean replica count across all nodes, and decides:
If a node is underfull compared to the mean, it does nothing
If overfull, it rebalances via snapshot to an underfull node
Our error was in making this judgement too literally, without applying enough of a threshold around the mean in order to avoid “thrashing”. See the animated diagram below which shows two scenarios.

Simulation 1. In the left "Exact Mean" simulation, we rebalance to within a replica of the mean; this will never stop rebalancing. Notice that far more RPCs are sent and the simulation never reaches equilibrium.
In the right "Threshold of Mean" simulation, we rebalance to within a threshold of the mean, which quickly reaches equilibrium. In practice, continuously rebalancing crowded out other, more salient, work being done in the cluster.
Lock Refactoring
Tracing tools were invaluable in diagnosing lock-contention as a cause of excessively slow or deadlocked clusters. Most of these symptoms were caused by holding common locks during processing steps which could sometimes take an order of magnitude longer than originally supposed. Pileups over common locks resulted in RPC traffic jams and excessive client latencies. The solution was lock refactoring.
Locks held during Raft processing, in particular, proved problematic as commands for ranges were executed serially, holding a single lock per range. This limited parallelization and caused egregious contention for long-running commands, notably replica snapshot generation. Garbage collection of replica data after rebalancing was previously protected by a common lock in order to avoid tricky consistency issues. Replica GC work is time consuming and impractical to do while holding a per-node lock covering actions on all stores. In both cases, the expedient solution of coarse-grained locking proved inadequate and required refactoring.
Tracing Tools
Ironically, the same tracing tools used to diagnose degenerate locking behavior were themselves stability culprits. Our internal tracing tools were pedantically storing complete dumps of KV and Raft commands while those spans were held in a trace’s ring buffer. This was fine for small commands, but quickly caused Out-of-Memory (OOM) errors for larger commands, especially pre-streaming snapshots. A silver lining to our various OOM-related difficulties was development of fine-grained memory consumption metrics, tight integration with Go and C++ heap profiling tools, and integration with Lightstep, a distributed tracing system inspired by Google’s Dapper.
Corruption!
OOMs and deadlocks are often diagnosed and fixed through honest labor that pays an honest wage. What keeps us up at night are seemingly impossible corruption errors. Some of these occur between replicas (i.e. replicas don’t agree on a common checksum of their contents). Others are visible when system invariants are broken. These kinds of problems have been rare, though we found one during our stability code yellow.
CockroachDB uses a bi-level index to access data in the system. The first level lives on a special bootstrap range, advertised via gossip to all nodes. It contains addressing information for the second level, which lives on an arbitrary number of subsequent ranges. The second level, finally, contains addressing information for the actual system data, which lives on the remaining ranges.
Addressing records are updated when ranges split and are rebalanced or repaired. They are updated like any other data in the system, using distributed transactions, and should always be consistent. However, a second level index addressing record went unexpectedly missing. Luckily, Ben Darnell, our resident coding Sherlock Holmes, was able to theorize a gap in our model which could account for the problem, despite requiring an obscure and unlikely sequence of events, and perfect timing. It’s amazing what a brilliant engineer can intuit from code inspection alone. Also, there ought to be a maxim that in a sufficiently large distributed system, anything that can happen, will happen.
Raft
Last, and certainly not least, we waged an epic struggle to tame Raft, our distributed consensus algorithm. In a resonant theme of these technical explanations, we had originally concluded that improvements to Raft that were on the drawing board could wait until after our general availability release. They were seen as necessary for much larger clusters, while the Raft algorithm’s impedance mismatch with CockroachDB’s architecture could simply be ignored for the time being. This proved a faulty assumption.
Impedance mismatch? Yes, it turns out that Raft is a very busy protocol and typically suited to applications where only a small number of distinct instances, or “Raft groups”, are required. However, CockroachDB maintains a Raft group per range, and a large cluster will have hundreds of thousands or millions of ranges. Each Raft group elects a leader to coordinate updates, and the leader engages in periodic heartbeats to followers. If a heartbeat is missed, followers elect a new leader. For a large CockroachDB cluster, this meant a huge amount of heartbeat traffic, proportional to the total number of ranges in the system, not just ranges being actively read or written, and it was causing massive amounts of network traffic. This, in conjunction with lock contention and snapshots, would cause chain reactions. For example, too many heartbeats would fill network queues causing heartbeats to be missed, leading to reelection storms, thus bringing overall progress to a halt or causing node panics due to unconstrained memory usage. We had to fix this dynamic.
We undertook two significant changes. The first was lazy initialization of Raft groups. Previously, we’d cycle through every replica contained on a node at startup time, causing each to participate in their respective Raft groups as followers. Being lazy dramatically eased communication load on node startup. However, being lazy isn’t free: Raft groups require more time to respond to the first read or write request if they’re still “cold”, leading to higher latency variance. Still, the benefits outweighed that cost.
The success of lazy initialization led to a further insight: if Raft groups didn’t need to be active immediately after startup, why couldn’t they simply be decommissioned after use? We called this process “quiescence”, and applied it to Raft groups where all participants were fully replicated with no pending traffic remaining. The final heartbeat to the Raft group contains a special flag, telling participants to quiesce instead of being ready to campaign for a new leader if the leader fails further heartbeats.
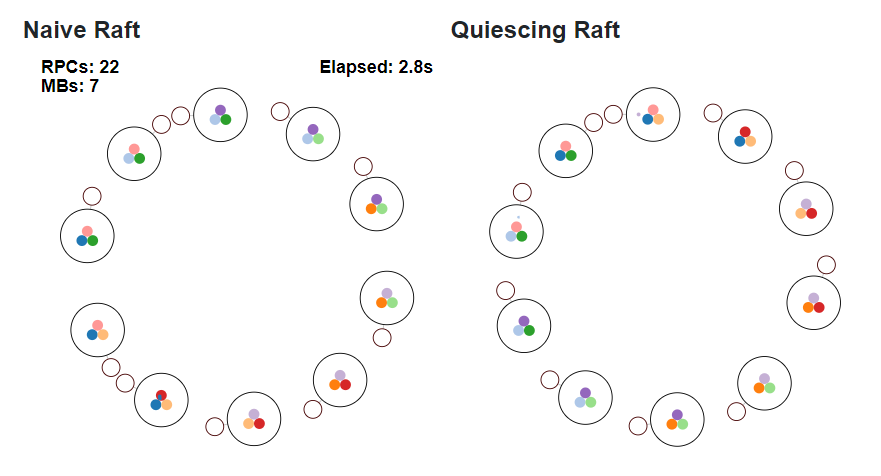
Simulation 2. In the left "Naive Raft" simulation, notice near constant sequence of heartbeats, denoted by the red RPCs between Raft groups. These are constant despite the slow trickle of writes from applications. In the right "Quiescing Raft" simulation, the Raft heartbeats occur only in order to quiesce after write traffic.
In addition to other changes, such as Raft batching, we managed to meaningfully reduce background traffic. By doing so, we also directly contributed to another key product goal, to constrain network, disk, and CPU usage to be directly proportional to the amount of data being read or written, and never proportional to the total size of data stored in the cluster.
Outcomes
How did our process and management initiatives fare in addressing the three hypothesized root causes?
Working With Two Branches
Splitting the master branch was not without costs. It added significant overhead in near-daily merges from the master branch to develop in order to avoid conflicts and maintain compatibility with stability fixes. We effectively excluded changes to “core” packages from the develop branch in order to avoid a massive merge down the road. This held up some developer efforts, refactorings in particular, making it unpopular. In particular, Tamir Duberstein was a martyr for the stability cause, suffering the daily merge from master to develop at first quietly, and then with mounting frustration.
Was the split branch necessary? A look at the data suggests not. There was significant churn in the develop branch, which counted 300 more commits during the split branch epoch. Despite that, there was no regression in stability when the branches were merged. We suspect that the successful merge is more the result of limits on changes to core components than to the split branches. While there is probably a psychological benefit to working in isolation on a stability branch, nobody is now arguing that was a crucial factor.
The CockroachDB Stability Team
Designating a team with stability as the specific focus, and putting a single person in charge, proved invaluable. In our case, we drafted very experienced engineers, which may have led to a productivity hit in other areas. Since this was temporary, it was easy to justify given the severity of the problem.
Relocating team members for closer proximity felt like it meaningfully increased focus and productivity when we started. However, we ended up conducting a natural experiment on the efficacy of proximity. First two, and then three, out of the five stability team members ended up working remotely. Despite the increasing ratio of remote engineers, we did not notice an adverse impact on execution.
What ended up being more important than proximity were daily “stability sync” stand ups. These served as the backbone for coordination, and required only 30 minutes each morning. The agenda is (and remains): 1) status of each test cluster; 2) who’s working on what; 3) group discussion on clearing any blocking issues.
We also held a twice-weekly “stability war room” and pressed any and all interested engineers into the role of “production monkey” each week. A production monkey is an engineer dedicated to overseeing production deployments and monitoring. Many contributions came from beyond the stability team, and the war rooms were a central point of coordination for the larger engineering org. Everyone pitching in with production duties raised awareness and familiarized engineers with deployment and debugging tools.
Fewer People, More Scrutiny
A smaller team with a mandate for greater scrutiny was a crucial success factor. In a testament to that, the structure has become more or less permanent. An analogy for achieving stability and then maintaining it is to imagine swimming in the ocean at night with little sense of what’s below or in which direction the shoreline is. We were pretty sure we weren’t far from a spot we could put our feet down and stop swimming, but every time we tried, we couldn’t touch bottom. Now that we’ve finally found a stable place, we can proceed with confidence; if we step off into nothingness, we can swim back a pace to reassess from a position of safety.
We now merge non-trivial changes to core components one-at-a-time by deploying the immediately-prior SHA, verifying it over the course of several hours of load, and then deploying the non-trivial change to verify expected behavior without regressions. This process works and has proven dramatically effective.
The smaller stability team instituted obsessive review and gatekeeping for changes to core components. In effect, we went from a state of significant concurrency and decentralized review to a smaller number of clearly delineated efforts and centralized review.
Somewhat counter-intuitively, the smaller team saw an increase per engineer in pull request activity (see stream chart below).

From the graph, you can see that stabilization efforts saw a significant tightening in pace of pull request changes near merge time. These effects can be traced to an increase in “embargoed” pull requests affecting core components, mostly refactorings and performance improvements which were considered too risky to merge to the increasingly stable master.
Conclusions on CockroachDB Stability
In hindsight (and in Hacker News commentary), it seems negligent to have allowed stability to become such a pressing concern. Shouldn’t we have realized earlier that the problem wasn’t going away without changing our approach? One explanation is the analogy of the frog in the slowly heating pot of water. Working so closely with the system, day in and day out, we failed to notice how stark the contrast had become between our stability expectations pre-beta and the reality in the months that followed. There were many distractions: rapid churn in the code base, new engineers starting to contribute, and no team with stability as its primary focus. In the end, we jumped out of the pot, but not before the water had gotten pretty damn hot.
Many of us at Cockroach Labs had worked previously on complex systems which took their own sweet time to stabilize. Enough, that we hold a deep-seated belief that such problems are tractable. We posited that if we stopped all other work on the system, a small group of dedicated engineers could fix stability in a matter of weeks. I can’t stress enough how powerful belief in an achievable solution can be.
Could we have avoided instability?
Ah, the big question, and here I’m going to use “I” instead of “we”.
Hacker News commentary on my previous blog post reveals differing viewpoints. What I’m going to say next is simply conjecture as I can’t assert the counterfactual is possible, and nobody can assert that it’s impossible. However, since I’m unaware of any complex, distributed system having avoided a period of instability, I’ll weakly assert that it’s quite unlikely. So, I’ll present an argument from experience, with the clear knowledge that it’s a fallacy. Enough of a disclaimer?
I’ve worked on several systems in the same mold as CockroachDB and none required less than months to stabilize. Chalk one up for personal anecdote. While I didn’t work on Spanner at Google, my understanding is that it took a long time to stabilize. I’ve heard estimates as long as 18 months. Many popular non-distributed databases, both SQL and NoSQL, open source and commercial, took years to stabilize. Chalk several up for anecdotal hearsay.
While proving distributed systems correct is possible, it likely wouldn’t apply to the kinds of stability problems which have plagued CockroachDB. After all, the system worked as designed in most cases; there was emergent behavior as a result of complex interactions.
I’d like to conclude with several practical suggestions for mitigating instability in future efforts.
Define a less ambitious minimally viable product (MVP) and hope to suffer less emergent complexity and a smaller period of instability. Proceed from there in an incremental fashion, preventing further instability with a careful process to catch regressions.
When a system is functionally complete, proceed immediately to a laser focus on stability. Form a team with an experienced technical lead, and make stability its sole focus. Resist having everyone working on stability. Clearly define accountability and ownership.
Systems like CockroachDB must be tested in a real world setting. However, there is significant overhead to debugging a cluster on AWS. The cycle to develop, deploy, and debug using the cloud is very slow. An incredibly helpful intermediate step is to deploy clusters locally as part of every engineer’s normal development cycle (use multiple processes on different ports). See the allocsim and zerosum tools.
Does building a distributed SQL system and untangling all of its parts sound like your ideal Tuesday morning? If so, we're hiring! Check out our open positions here.
![[image] finserv use cases](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2F00voh0j35590%2F61herWHcBa8OEwzsV20Vco%2F5971df8ab1da34f54d551ca1383e10ba%2FFinserv_use_cases_Blog_1920x1080__1_.png&w=3840&q=75)

