

It’s 10 o’clock. Do you know where your data is?
Chances are, it’s nestled snugly in its database. But chances are that it’s also less secure than you might think. Even in sophisticated systems with backups and failover plans, data loss is possible. And importantly, it can happen without you realizing it’s even possible – at least, not until it’s too late.
How you might be losing data without knowing it
Every company backs up its mission-critical workloads with some kind of database replication, and failover procedures to ensure that a single machine going down doesn’t knock down the entire database. In well-optimized systems, failover times may be measured in seconds, or even milliseconds. And this, in turn, often gives people – particularly folks in management, on the application team, etc. – the impression that they’re protected from costly outages and data loss.
However, with many such setups, significant data loss is often still possible. And often, that doesn’t become apparent until after it happens for the first time.
Let’s take a closer look at how that happens, and how it can be prevented. To do that, we need to talk about the most common ways that companies replicate their data with legacy SQL databases such as MySQL, Oracle, SQL server, etc: synchronous replication, asynchronous replication and semi-synchronous replication.
What is synchronous replication?
If you think about a distributed database system, the obvious way to prevent data loss is to ensure that data isn’t committed to any node unless it’s been committed to all nodes. This is called synchronous replication.
In a two-node system with synchronous replication, for example, data isn’t fully committed to either node until it has been sent to the replica node and the replica node has send confirmation back to the primary node that it was received:
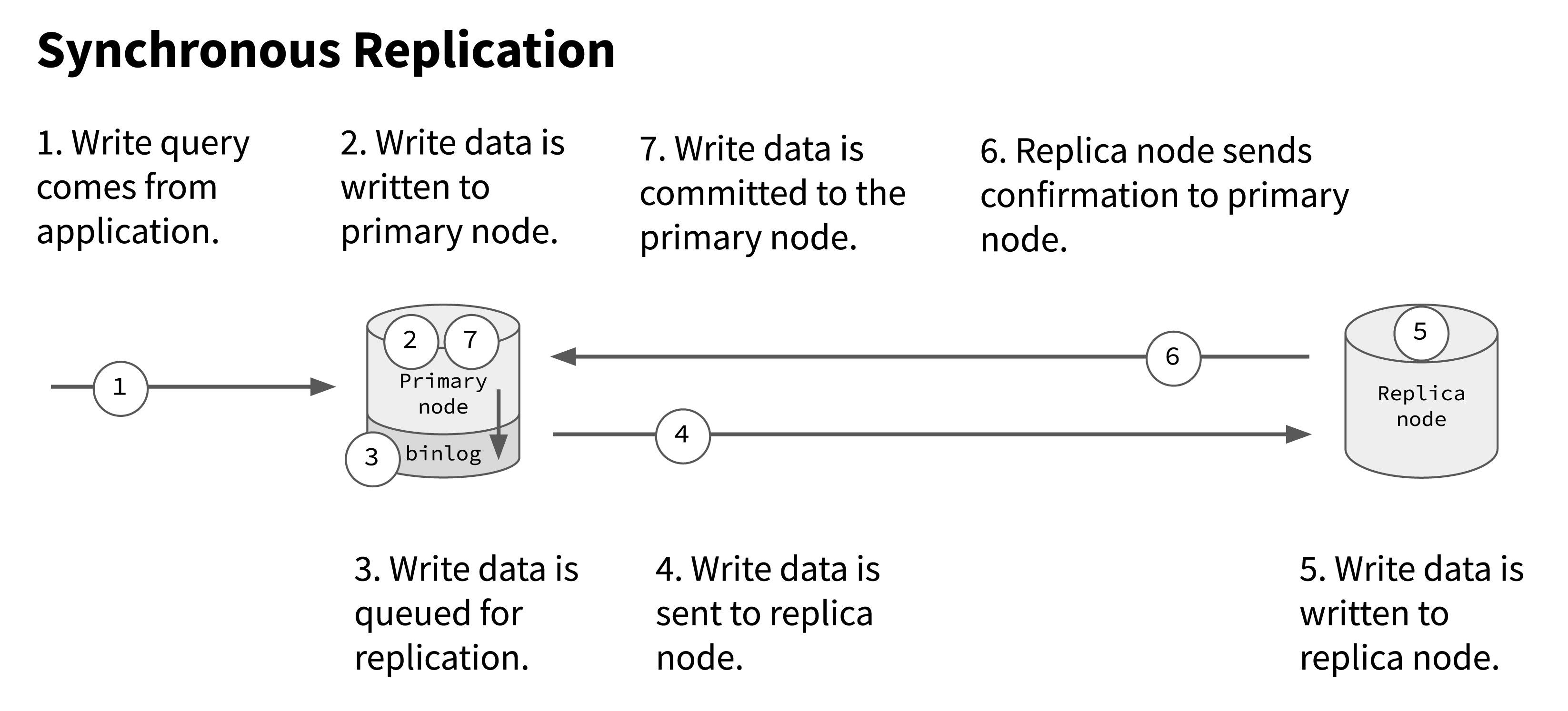
This approach works well to ensure consistency between the nodes. If the primary node were to go offline, no data would be lost, as any data committed to the primary node has also been committed to the replica node.
However, synchronous replication introduces latency into the system, since the primary node has to send the write and then wait for confirmation from the replica node before it can commit.
This additional latency will be minimal if there are only two nodes and they’re deployed relatively close to each other (for example, in the same cloud AZ). But for most production workloads, and especially mission-critical workloads, there are likely to be more than two nodes, and these nodes may be spread across different AZs or different cloud regions to ensure the system is highly available. Each additional node and region increases the latency, since there are more steps required and the data has to travel farther before a write can be fully committed.
Synchronous replication provides robust data protection, but at the cost of very high write latency. This very high write latency can be crippling for many applications, so they look to asynchronous or semi-synchronous solutions, and that’s where the risk of data loss can creep in.
What is asynchronous replication?
In asynchronous replication, you have a “primary” database node that is the only one that accepts writes from the application. When writes are the primary node acknowledges the committed write to the application, and the application moves on assuming that write is permanent. Then the write is synced to a replica node (or nodes), creating an exact copy of the primary node. In the event the primary node goes down, you fail over to a replica node, making that the new primary.
Here’s an illustration of how it works with a single replica node:
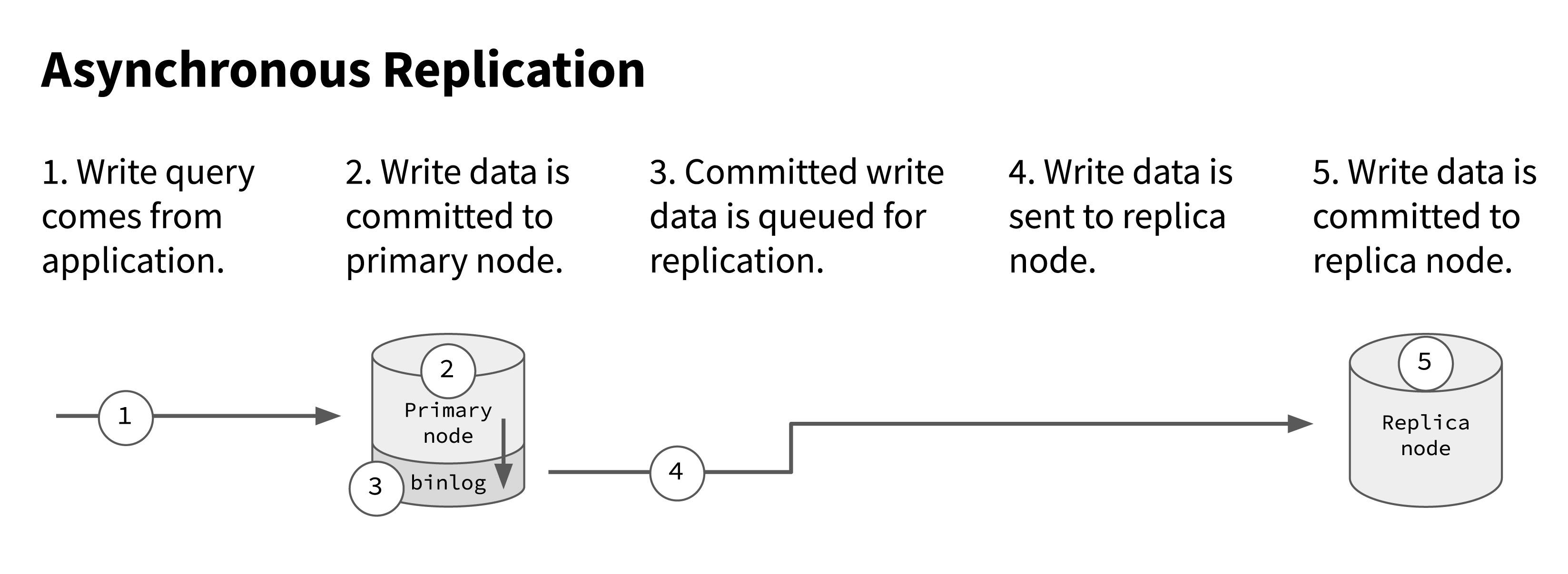
This type of system is called asynchronous replication because the data replication happens after the write has been committed on the primary node. And that’s where the potential for data loss comes in.
How you can lose data with asynchronous replication
Imagine a write comes in, is committed to the primary node, the application receives the acknowledgement that the write succeeded, and then the primary node immediately goes offline. Because the replication is not synchronous, the write wasn’t sent to the replica node before the primary node went down. Thus, when the system fails over to the replica node, that write – and any subsequent writes that have come in while the failover is happening – is lost. It’s still stored on that primary node machine, but by the time that comes online the other node will have committed additional writes, at which point there’s no way to merge back in that initial lost write.
[ GUIDE ]
Migration Guide: Migrating from Oracle to CockroachDB
Under ideal circumstances, very little data is lost in this way. If, for example, the replication process takes only a second and the failover process takes only a second, then you’ve lost – at a maximum – two seconds of data. For some workloads, that’s already unacceptable, but many companies may be willing to accept a few seconds of lost data as their “worst case scenario.”
The problem is that this isn’t actually the worst scenario.
This kind of lighting-fast replication between the primary node and replica node is only possible when both nodes are operating as expected, and neither node is overworked. However, if one or both gets overwhelmed – for example, by an unexpected burst of traffic, a poorly-written query, a system error, etc. – the replication queue can quickly get backed up to the point where minutes or hours worth of updates have been written to the primary node but aren’t yet committed to the replica node.
And unfortunately, those sorts of less-than-optimal circumstances are also the times when it’s mostly likely that a node will go down. If your system is getting overwhelmed by a huge burst of queries, for example, that could knock the primary node offline. But before it does, it’s likely that the struggle to keep up with those queries will have created a backlog of not-yet-synced writes that will then be lost when the primary node goes down and you fail over to the replica node.
Moreover, these kinds of circumstances happen more often than you might think. Outages may be rare, but ask your data team how often replication speed gets backed up into the realm of minutes or hours. It’s common that even systems with sub-second replication times under ideal conditions will have much longer replication delays a few times a month (or more).
It’s possible to go years with a setup like this and not lose data, which is why it’s common for many folks on the team to not be aware there’s even a risk. The fact that the data is replicated and there’s a fast failover plan in place can leave everybody with a false sense of security. But sooner or later, an outage will coincide with a replication backup, and people will be surprised to learn that their sub-second system still ended up with hours of lost data.
What is semi-synchronous replication?
Semi-synchronous replication is essentially the same as synchronous replication, except that a semi-synchronous system will revert to asynchronous replication if the latency between nodes passes a certain threshold.
This removes the “latency penalty” associated with fully synchronous replication, but it also means that anytime the system is stressed, it is likely to revert to asynchronous replication, meaning that it can lose data in the exact same manner as an asynchronous system.
From a data loss perspective, a semi-synchronous system is really the worst of both worlds: you get a lot of the additional latency associated with synchronous replication, but you’re still vulnerable to data loss if the system gets stressed and then a node goes offline.
A better way: zero data loss with consensus-based replication
CockroachDB, a next-generation distributed SQL database, offers a different approach to replication. It combines the best of both synchronous and asynchronous approaches, cutting down on latency while still guaranteeing consistency and preventing data loss.
In CockroachDB, when your application sends a write request, the request goes to a “leader” node which then syncs it to multiple follower nodes. When a majority of these nodes have confirmed receipt, the write is committed.

This is a bit of an oversimplification – here are the full details, if you’re curious – but what’s important is the end result, which is:
Guaranteed data consistency
Zero data loss
Reduced latency (as compared to fully synchronous replication)
To be clear, CockroachDB and other databases that use consensus replication still have more latency than an asynchronous system when it comes to writes, since several nodes still need to communicate before a write can be committed.
However, this latency penalty will be lower than it would for a similarly-deployed synchronous system needed to get zero data loss during a failure. Increasingly, companies are realizing that this latency is a small price to pay for not having to compromise on resilience, data consistency, or data durability. Additionally, CockroachDB’s native support for multi-region deployments down to the row level makes it easy to cut down on latency from another angle, by locating critical data in regions geographically close to the users who most often access it.
Why is data loss prevention important?
Whether it’s fully synchronous replication or consensus replication, ensuring zero data loss does come with at least a small latency penalty. Whether that’s worth paying depends on the workload in question. Losing some data in low priority, non-critical workloads, for example, may be acceptable. Losing data from tier 0 workloads almost never is.
To assess whether it’s worth worrying about data loss for your workload, consider all of the ways in which lost data can end up hurting your bottom line:
Cost in dollars.
For many tier 0 workloads, lost data means lost sales, and those are dollars that may be impossible to get back (as customers may have found what they need from a competitor).
Cost in customer loyalty.
If a customer submits a request (making a purchase, submitting a stock trade, making a deposit in a bank account, etc.) and that data is subsequently lost, there’s a good chance you’ve lost a customer.
Cost in reputation.
Losing significant amounts of customer data, or losing the wrong kind of data (bank deposits, stock trades, etc.) is likely to also quickly become a PR problem that damages the reputation of the company, and it has the potential to become a legal problem or a security problem, too.
(For example: in a system that manages access controls to sensitive data or critical systems, if the lost write was the revocation of access to a terminated employee, when the replica system takes over after a failure, the terminated employee would still have full rights and access. We’ve all seen what happens when sensitive data is stolen through privileges that were not properly revoked after employees leave.)
Cost in lost productivity.
Outages and data loss generally require manual intervention from a number of teams across the company. Engineering, operations, management, customer service, PR/communications, and legal departments may all need to dedicate time and resources to dealing with a data loss incident and the resulting fallout.
As we can see, these cost scale quickly based on a few factors, including but not limited to:
The amount of data lost
The size of the company
The importance of the workload
The sensitivity of the data lost
It stands to reason, then, that many large enterprises are moving their mission-critical transactional workloads onto CockroachDB.
Is your data protected from data loss?




