

When building database software which will run in some of the world’s most demanding environments, testing it in ways that simulate these customer environments is non-negotiable.
There are several classes of problems which only reveal themselves at a larger scale. For example, importing data may work well for 100 GiBs of data, but may fail to perform for 100 TiBs of data. Similarly, achieving balanced performance across the nodes in a cluster may be straightforward with a three-node cluster, but could encounter problems when the cluster has 30 or 300 nodes - especially if multiple nodes are dropped or added concurrently.
Testing large clusters is critical, but doing so at a scale that matches some of our largest customer environments can get costly. What if a totally different – and highly cost-effective -- approach to large cluster testing revealed itself? At Cockroach Labs we decided to take a non-traditional path, and things got very interesting.
Driving down the costs of testing a distributed database using spot instances
As builders of a distributed database, CockroachDB, many of our customers run clusters that have dozens of nodes, and some of our largest customers run clusters with hundreds of nodes. While scale testing on hundreds of nodes is feasible for short durations, large clusters can get expensive very quickly. For example, here are the costs of a moderately sized 40 node cluster on Google Cloud:
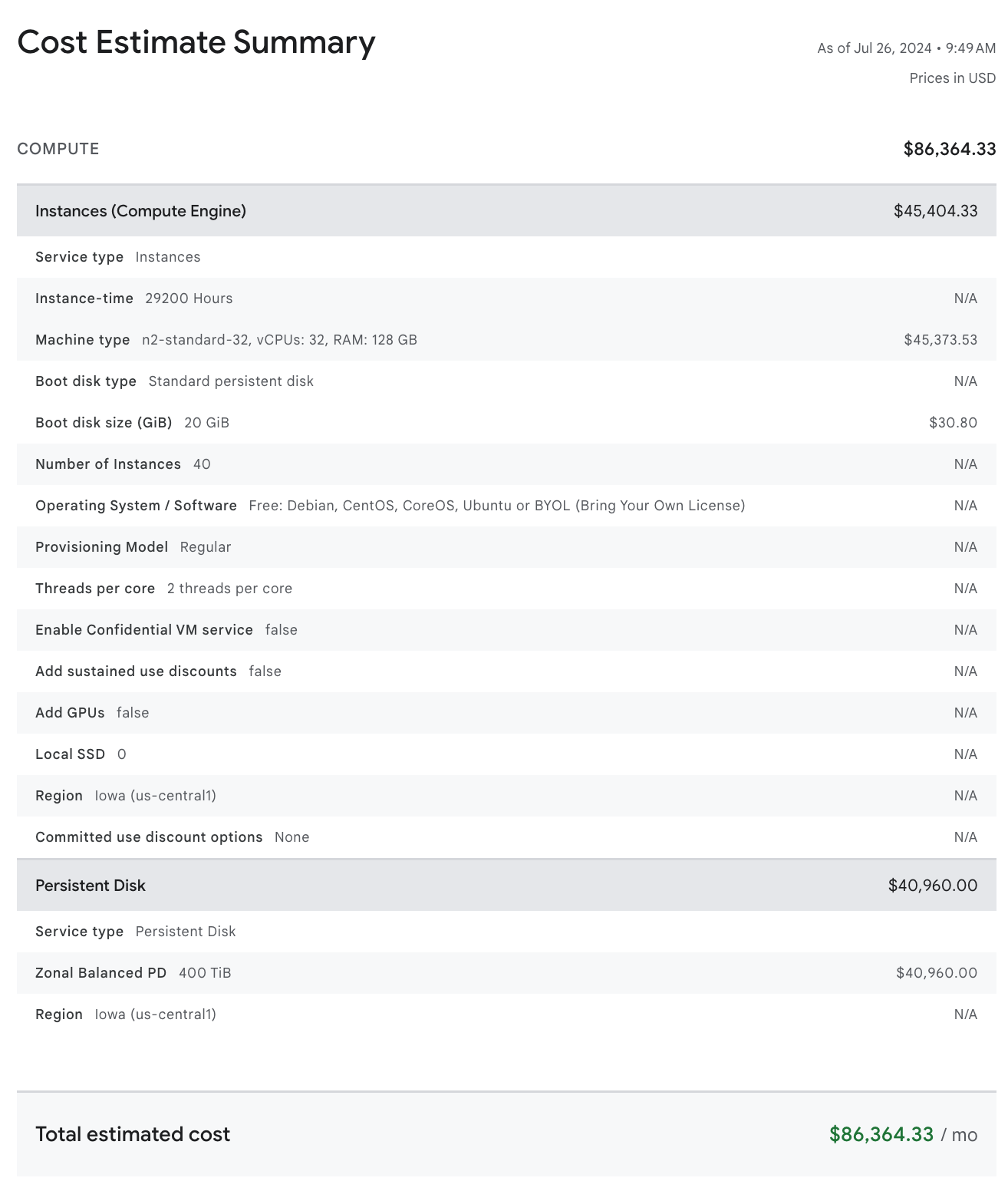
For a cluster with just 40 nodes, each containing 32 vCPU and 10 TiB of attached storage, the on-demand price for the cluster is more than $85,000 a month, or more than a million dollars per year! Seeing as how we test many long-running clusters concurrently, optimizing our testing costs are a going concern.
Over the past year, Cockroach Labs has been working to increase the size and complexity of our long-running clusters, while at the same time containing or driving down our costs. This motivated us to start considering running some of our long-running clusters on spot instances.
What are spot instances?
One of the main promises of cloud computing is the ability to rapidly, and near infinitely, scale your compute resources. The way the cloud service providers allow for near instantaneous provisioning of virtual machines (which must be backed by physical resources) is by maintaining pools of pre-provisioned VMs, which can be rapidly assigned to users when requested.
Doing so however, necessarily implies that there is some amount of “wasted” resources at any given time. To manage this waste, in 2009 Amazon Web Services introduced the concept of “AWS spot instances”. Spot instances are idle compute resources that users can bid on and, if their bid is highest, use until they’re outbid – or until the cloud service provider needs the instance back for an on-demand use case (another form of out-bidding).
As a result of the fact that spot instances are entirely wasted resources if they’re not bid on, they’re often significantly less expensive than on-demand VMs (as much as 90% cheaper). Of course, there’s no such thing as a free lunch, and the big caveat with spot instances is that with a small amount of notice (anywhere from 30 seconds to two minutes), they can be taken from you, and you’re left with nothing. This is colloquially referred to as a spot instance “preemption”.
This makes spot instances particularly useful for workloads which aren’t time sensitive and can be restarted easily, like CI/CD or analytics data pipelines. Today, spot instances in AWS aren’t the only offering – they’re also available for users of Google Cloud and Azure.
We started down the path of leveraging spot instances when the Database Resilience Testing (DRT) team at Cockroach Labs proposed building a moderately sized long-lived testing cluster which validated the higher end of customer-like data density. While many CockroachDB customers run with 2 TiB or less data per node in their clusters, some of our larger customers run clusters with 10 TiB or more per node. Running at higher data densities stresses the system in different ways, which can expose interesting edge cases both for stability and performance.

You did WHAT with the operational database?!
At this point you may be asking yourself: “Why would anyone consider standing up a long-running test cluster for CockroachDB - which is designed for high throughput, low latency, operational workloads - on spot instances?” The simple answer is: because we can.
CockroachDB is a distributed shared nothing database which replicates data at least three ways for availability and durability. Here’s how it works:
Each table in a CockroachDB database is split into shards, called “ranges”.
Each of these ranges are replicated using a configurable replication factor (which defaults to three-way replication) and the specified number of range replicas are placed on different nodes in the cluster.
As CockroachDB employs consensus-based replication using the Raft algorithm, so long as a quorum of replicas for a given range remains available, the data continues to be accessible.
With three-way replication, a three-node cluster can suffer the loss of a single node and continue serving traffic.
With higher replication factors and larger cluster sizes, clusters can be configured to survive a larger number of concurrent node failures, including full data center or region failures.
CockroachDB’s approach to replication sets it apart from single-node databases or even primary-standby database configurations, and makes the use of spot instances possible.That’s because a long-running cluster is able to survive some level of spot instance preemption before the workload becomes unavailable.
Additionally, leveraging spot instances for long-running test clusters not only delivers substantial cost savings, but it also provides randomized chaos testing with no additional effort - In fact, we’ve found that spot instances are an invaluable tool in our testing arsenal.
Our journey to spot instances
We first turned to spot instances as part of a sizing exercise for one of our new “storage-dense” test clusters. The challenge with “storage-dense” clusters, however, is that storage is expensive. When we first sized this testing cluster on Google Cloud, a cluster consisting of 15 nodes (each with 16 vCPUs) and 10 TiB of attached SSD-backed persistent storage was estimated to cost $325,000 a year. When we brought this proposal through to our executive team they were not opposed to the idea of creating the cluster (in fact, they encouraged it), but they asked if the team could investigate ways to drive down the cost. Aside from purchasing hardware to run in our offices (something we briefly considered) the main tool at our disposal was the Google Cloud Platform (GCP) pricing calculator, so we went to work.
The first thing we noticed was that the cost of network-attached persistent storage can dominate, when running a cluster with a large amount of available storage. With this original configuration, more than $215,000 of the $325,000, or approximately 66% of the cost was for the storage.
This first led us to investigate leveraging local solid state drives (SSDs), which at least in Google Cloud, are significantly less expensive than their network-attached counterparts ($0.08 per GB vs $0.17 per GB). This drove the cluster cost down from $325,000 to $200,000, and the storage cost to around 48%.
It was a good start, but we wanted to move the needle on the compute costs as well - enter spot instances.
When we started configuring our spot instance cluster we noticed that it not only drove down the cost of the VMs, but it also dropped the cost of storage. We couldn’t figure out why, until we noticed this line from the GCP docs:
“Spot prices apply to Local SSD disks attached to Spot VMs”
which – after some thought – made sense. If you have idle VMs, and there are local SSDs mounted in close proximity to those VMs, it stands to reason that you’ll also have idle SSDs. Discounting those SSDs to increase utilization is likely to make them less idle.
When we resized the cluster on local SSDs and spot instances, the real savings showed up - we were now down to $89,000 per year from the original estimated cost of $325,000 ( a greater than 72% savings)!
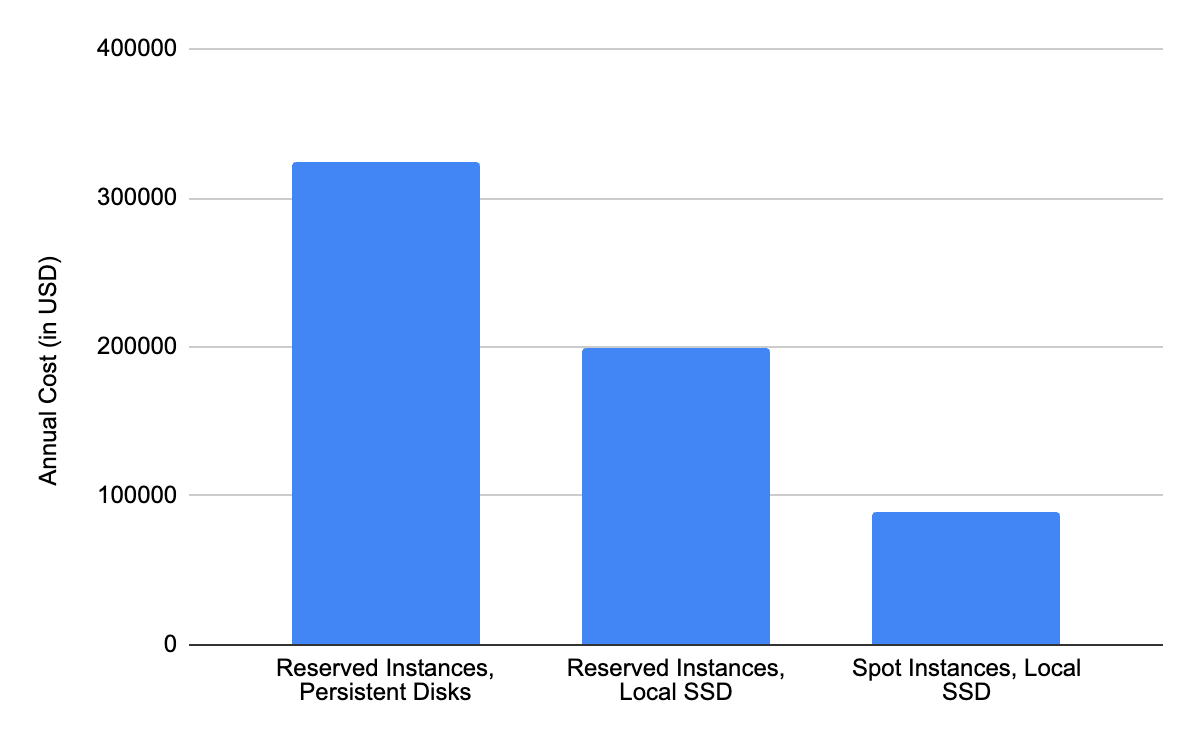
Cluster configurations considered
Configuring the cluster
One of the first things we noticed about spot instances on GCP is that unlike on AWS, their pricing is far more predictable. While AWS updates the prices of their spot instances as frequently as once every five minutes, GCP promises that price changes occur at most once per month.
Furthermore, it was clear that the pricing of spot instances was not uniform across regions. Before setting up the cluster we surveyed people on the CockroachCloud team who, in their past roles, had leveraged spot instances. That survey uncovered that we should expect spot instance preemption to be correlated within zones and regions.
As a result, we set out to create a three-region cluster, configured for region survivability, which places five replicas across the cluster’s regions to ensure that if one region completely fails, the rest can continue unaffected (i.e no more than two replicas in a single region). This is especially important when leveraging spot instances combined with local SSDs.
Since local SSDs are associated with an individual VM, when that VM gets preempted, the disks disappear as well. If you’re leveraging three-way replication and two of your replicas get simultaneously preempted, the affected data is lost forever (i.e. it must be restored from a backup). It’s for this reason that CockroachDB’s region survivability is so helpful: Region survivability increases the replication factor to five and places at most two of those replicas in any single region. So long as we didn’t experience a sequence of preemptions across regions, the database would remain operational.
Setting up the cluster
To test our ability to run with a CockroachDB cluster separated by the Atlantic Ocean, we first chose to set up our spot instances in three GCP regions - northamerica-northeast-1 (Montreal), northamerica-northeast-2 (Toronto), and europe-central-1 (Warsaw). The cluster was 15 n2-standard-16 nodes (five in each region), each with 16, 375GB local SSD drives (6TBs of total storage per node). Further, the cluster was created as part of a GCP Managed Instance Group, which provided us with the added benefit of reclaiming preempted spot instances when additional inventory was made available.
After provisioning the cluster, our first step was to import a sizable amount of data so that we could run a workload against it. To do this we used some internal tooling which can create a TPC-C-like database of any arbitrary size. We started by loading a ~12 TiB data set into the cluster which, using 5x replication, requires nearly 60 TiB of disk space.
We started the import of all 9 TPC-C tables at 4pm ET (9pm UTC) and let it run overnight. When we woke up in the morning, we were greeted by this chart in the CockroachDB Console:
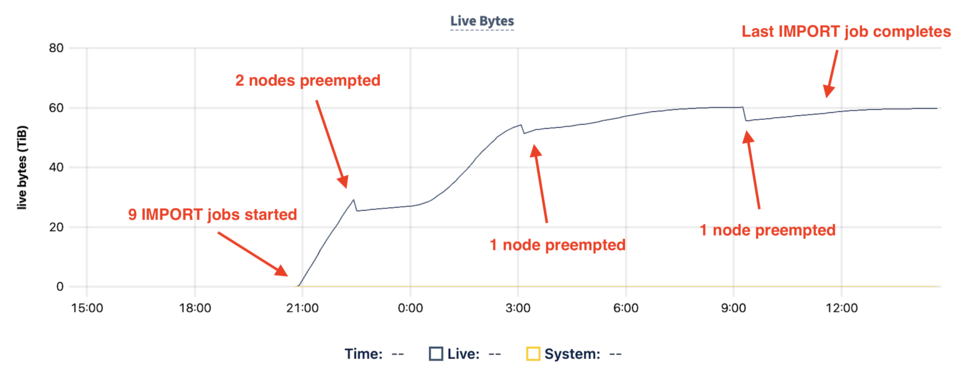
The import ran well until around 22:30 UTC, when we encountered our first preemptions (in this case, two nearly simultaneously). This impacts the import progress because not only did the cluster need to restart the import from where it last checkpointed (done automatically by the import job), but it also needed to up-replicate the data on the two nodes which were stopped and restarted.
The cluster recovered from this state over the next 90 minutes and continued to make rapid progress on the import when again it encountered another preemption. This time the import job was 93% complete which meant two things:
There was only a small amount of data left to import
Our nodes now contained almost 4 TiB of data each, and reseeding – i.e. restarting/resuming the data import – nodes of that size takes time.
The cluster used the next hour to reseed the node and make moderate progress on the import until at 9:00 UTC when the job was 99% complete, the final preemption occurred. This required the reseeding of one last node before the job eventually finished at 11:30 UTC.
With the data set loaded, we started running our TPC-C-like workload, and began studying how preemptions impact a running transactional workload.
Diving deeper - what a preemption looks like
When a preemption occurs on a CockroachDB cluster, there are several phases in the cluster’s recovery . These are illustrated in the following chart of cluster ranges over the course of the preemption.
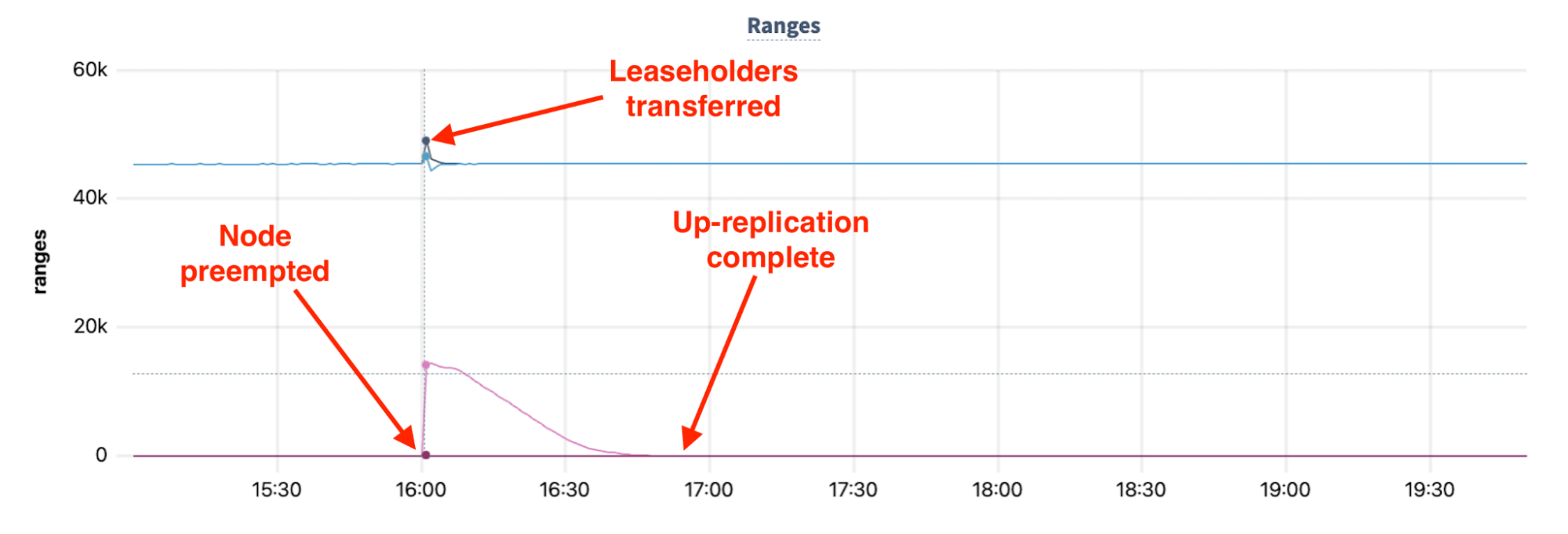
In the first phase, all of the leaseholders on the preempted node must be acquired by other nodes in the cluster before the underlying replicas can be made available again. This leaseholder acquisition typically occurs in a few seconds.
Following the leaseholder acquisition, the cluster is fully available, but is compromised from an availability perspective, as all of the replicas on the preempted node were lost. As a result, the cluster enters a temporary state of “under-replication”. In the case of this cluster, which is replicated with a replication factor equal to five , there are four remaining replicas available for all ranges which resided on the node that was preempted.
The second phase of recovering from the preemption aims to correct the under-replicated state by “up-replicating” the given ranges - bringing their total number across the cluster to the specified replication factor. This up-replication phase utilizes all of the nodes in the CockroachDB cluster (both for reading and writing), with the goal of parallelizing the process so that the cluster is able to exit the compromised state of under-replication as quickly as possible. In the above example, the preempted node’s ranges (more than 1.25 TiBs of data) are fully up-replicated among the cluster’s nodes within 50 minutes of the preemption.
The third phase of preemption recovery is shown in the following chart:
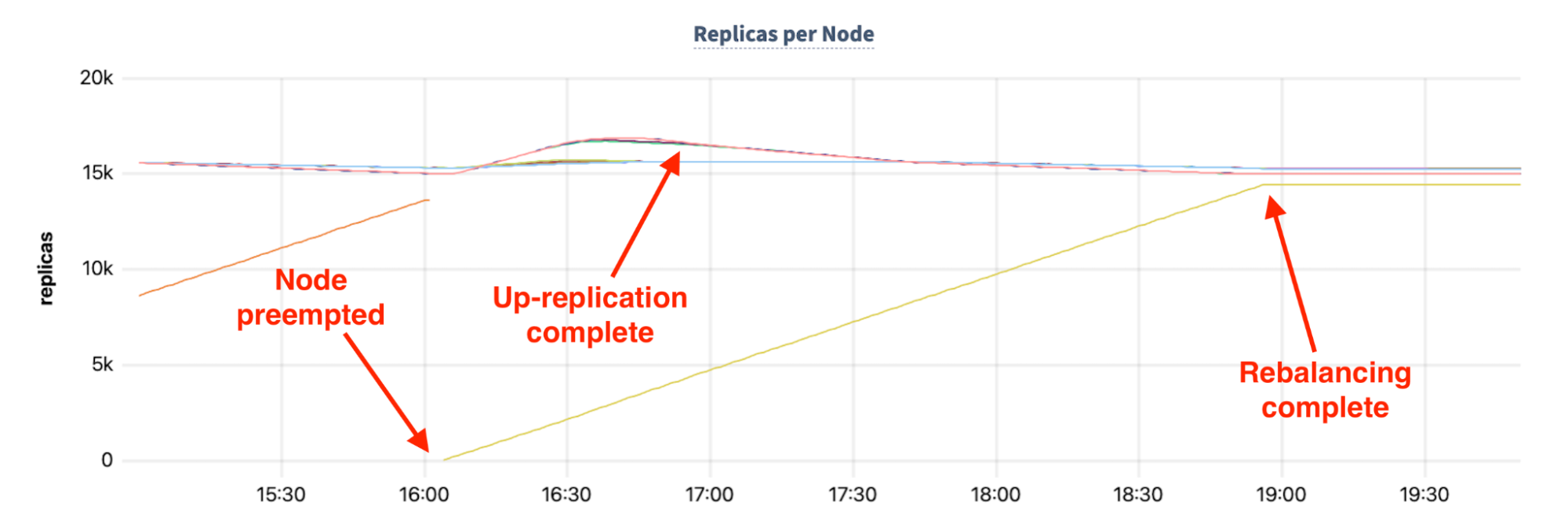
Once the up-replication is complete (shown above through the increase of replicas on the surviving nodes), the cluster works to return the preempted node to full participation. This requires the new node to up-replicate its full share of replicas, and balance the load across the cluster. This process, referred to as “rebalancing”, takes almost three hours, at which point the cluster returns to its full performance capacity.
In the above chart, take note of the orange diagonal line on the left side of the chart: This shows the up-replication of the node that was preempted. In this example, the same node was preempted twice in close succession - before the cluster was fully able to up-replicate the node, it was preempted again.
Speaking of performance, what does the performance of the CockroachDB cluster look like throughout this process? The following chart show the impact on throughput during the preemption:
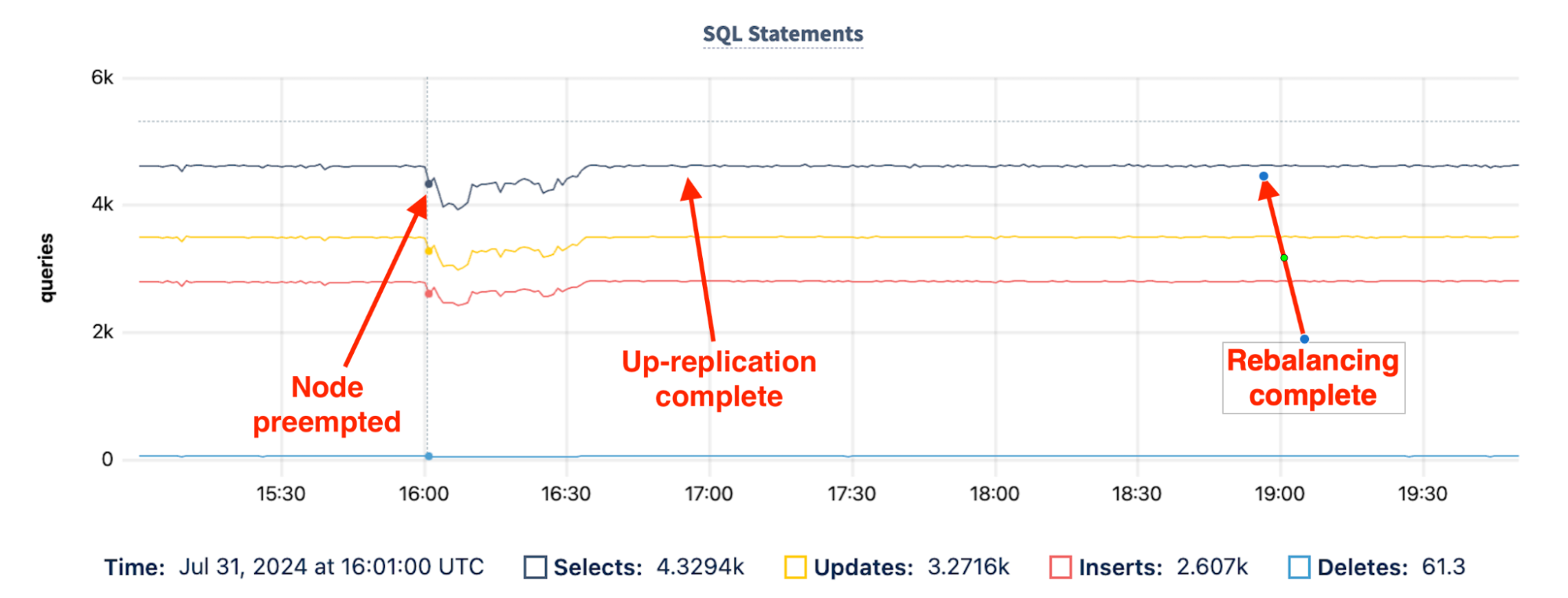
The chart shows that there is a hit to throughput of ~15% shortly after the preemption occurs. This is due in part to the fact that the cluster has lost ~7% of its capacity - the preempted node is still not a fully active participant in the cluster - combined with the impact of the concurrent up-replication. This impact gradually tapers off, and at around 30 minutes after the preemption, the cluster returns to its pre-preemption throughput levels.
A similar impact can be seen with P99 transaction latency:
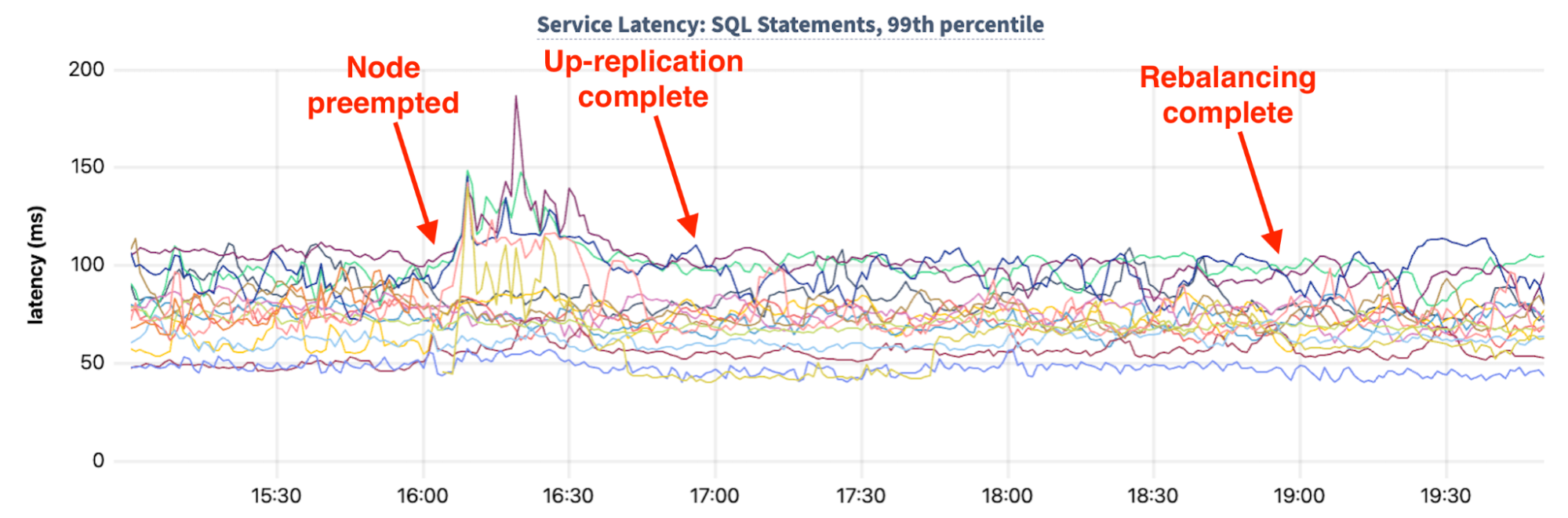
SQL statement P99 latency increases on some of the CockroachDB cluster’s nodes from ~100ms to as high as 186ms and remains in this elevated state for approximately 30 minutes. Once the bulk of the up-replication has completed however, the cluster’s latency returns to pre-preemption levels, well in advance of the completion of up-replication and rebalancing.
What a flurry of preemptions looks like
As mentioned above, preemptions are unpredictable, can often occur in close proximity, and disproportionately impact some nodes and regions over others. While on some days we may see no preemptions at all in our 15-node cluster, on other days we may see 10 or more preemptions. As I was putting together this blog post we encountered a 24-hour period with 12 preemptions, as visible from the Google Cloud console:
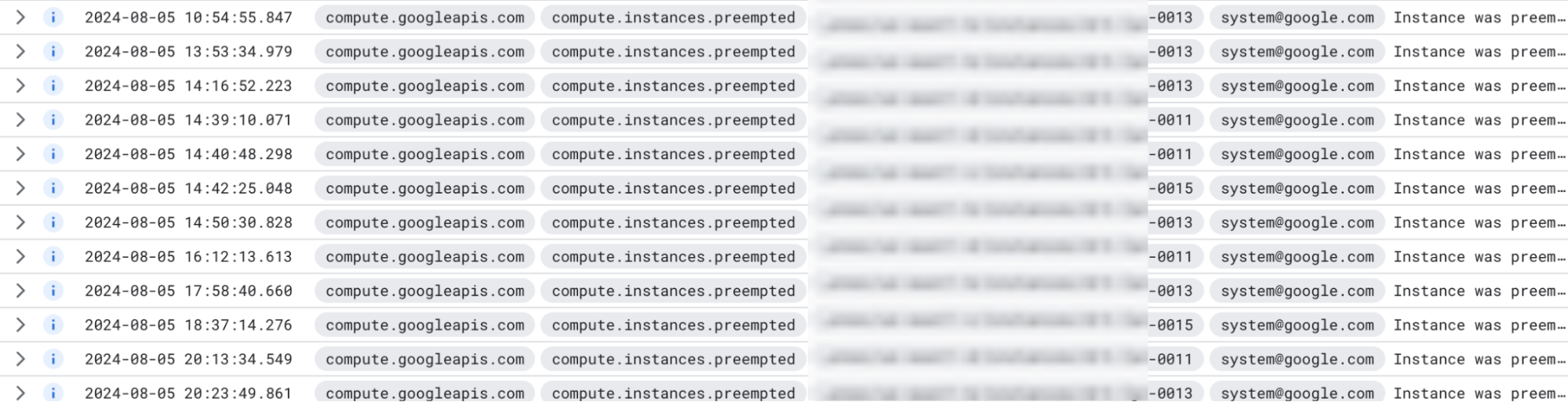
In this period, node 13 was preempted six times, node 11, four times, and node 15 was preempted twice. What does this sequence of preemptions look like from the CockroachDB cluster’s perspective? Below is a chart that shows how the cluster reacts:
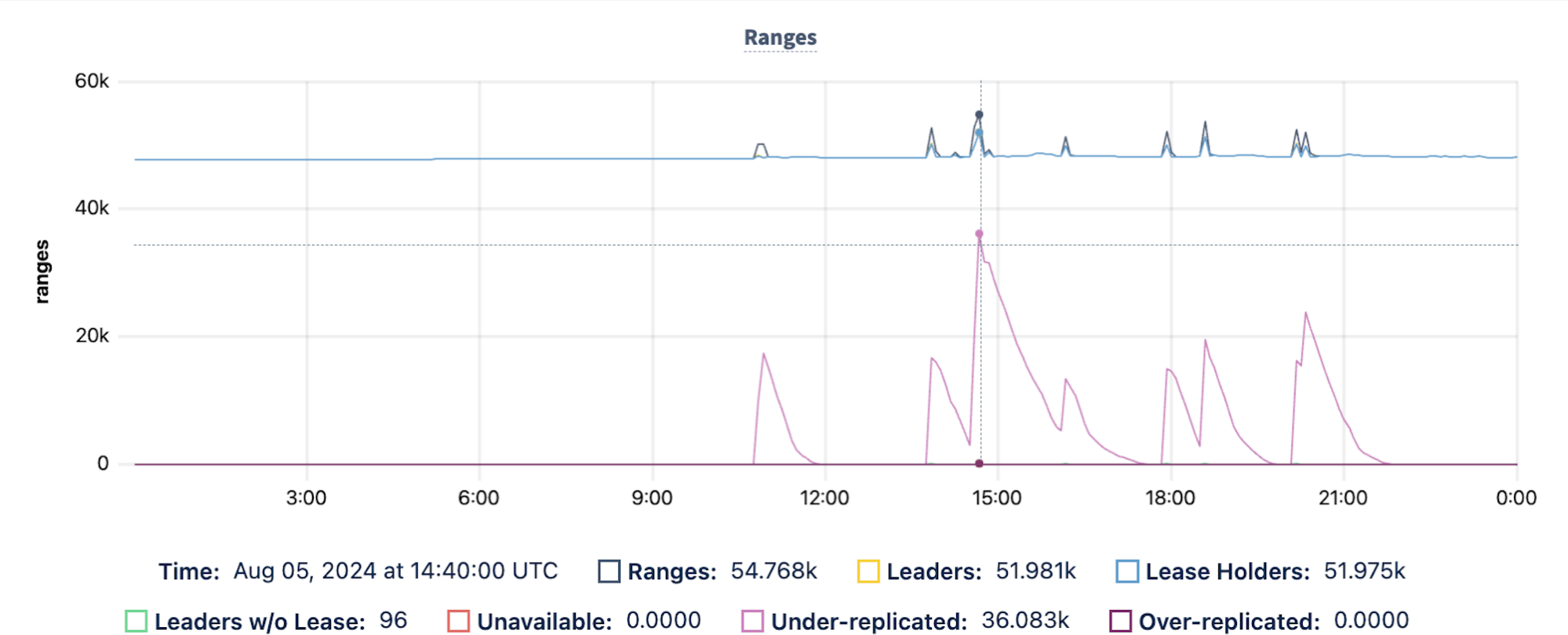
The chart shows the replication characteristics of the cluster during the 24-hour period. For the first 10+ hours, the cluster is operating under normal conditions, with all ranges of data properly replicated five-ways. As the preemptions start at 10:54 however, ranges begin to be under-replicated, and the cluster must resolve this condition by up-replicating the data from the lost ranges to other nodes of the cluster.
This typically completes within an hour of each preemption, but in cases where multiple different nodes are preempted at around the same time (as happens around 14:40 when 3 different nodes are preempted in close succession) the recovery takes longer. In this case, from the peak at 14:40, it takes almost three hours to fully up-replicate all of the data that’s lost in the sequence of preemptions:
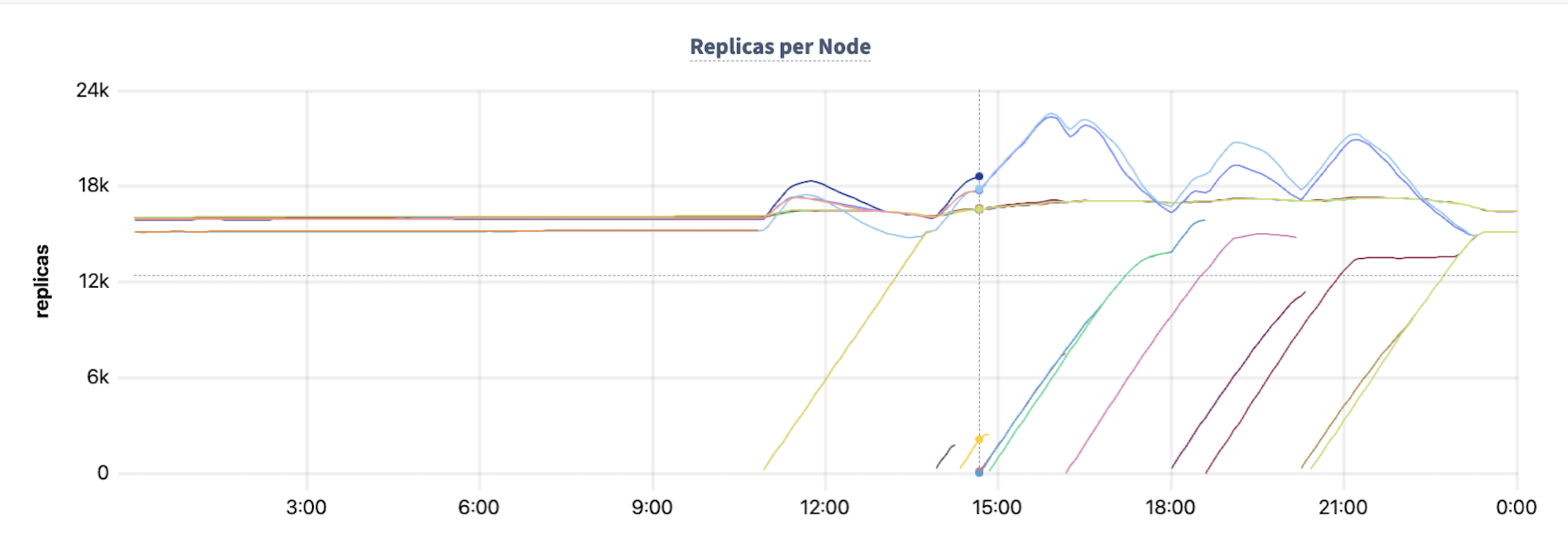
This chart of replica placement shows the population of newly provisioned nodes more starkly. The colored lines rising from the bottom of the chart are nodes being added to the cluster post-preemption. Some of these lines make it to the ~17K mark on the chart (where replicas are approximately balanced across the nodes of the cluster) but others end before that. This premature ending signals the fact that the newly added node was itself preempted. In this period, where multiple nodes were preempted multiple times, we see many of these aborted attempts at repairing the cluster.
While these preemptions are occurring throughout the day, throughput on the cluster is impacted, but only moderately:
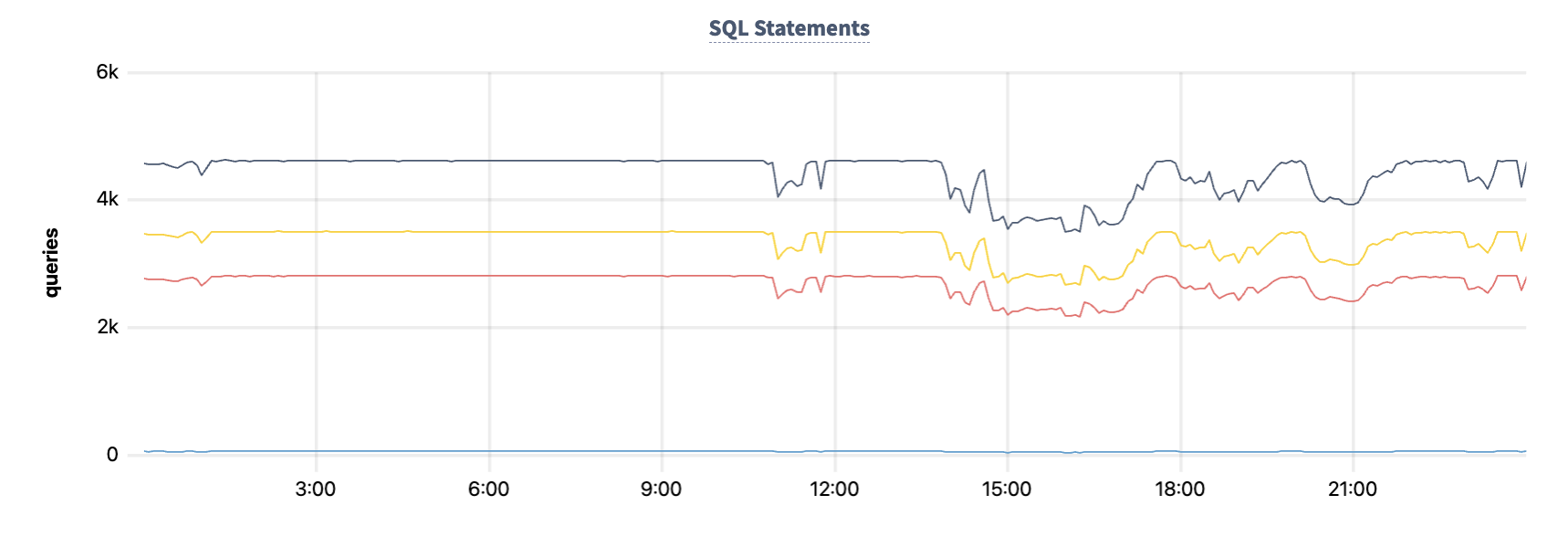
At its worst, the CockroachDB cluster is able to push almost 60% of its original throughput. Considering that it's doing so with only 80% of the nodes available (since some nodes have recently recovered from a preemption and aren’t operating at full capacity yet), it’s an impressive achievement! It’s especially notable considering the fact that the cluster’s nodes were operating at 40-70% utilization before the preemptions began:
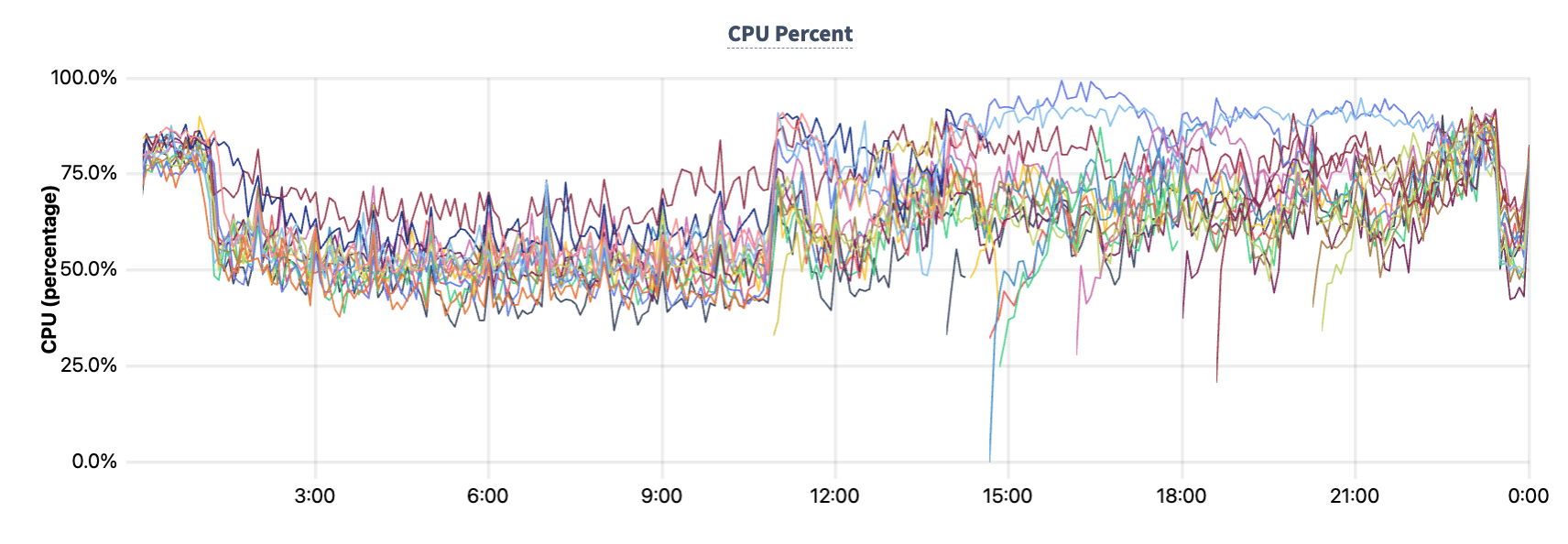
The resultant up-replication activity pushes some of the cluster’s nodes close to 100% utilization, which has some impact on the cluster’s ability to process incoming transactions. Had this cluster had more headroom before the preemptions, or had the preemption load been less significant, we would have seen a less pronounced impact to throughput.
Lessons learned
Over the past three months we’ve continuously run workload on our spot instance cluster and we’ve learned a few things.
Spot instances + local SSDs = 🥵
As mentioned above, using spot instances in partnership with local SSDs amplifies the impact to preemptions, as every preemption also deletes all data from the affected node. This has been a blessing in disguise.
While it drives the system to extremes, it has also helped to uncover issues that can only be found when pushing the system hard. Best of all, we didn’t need to build dedicated automation to drive the chaos in the cluster - our cloud service provider did that for us. As a result, while we’re saving on costs by using discounted hardware and discounted storage, we’re also saving on the need to write chaos testing infrastructure - it’s a win-win. That being said, having to up-replicate a node’s data every time it’s preempted does cause other issues, namely around costs.
Beware the hidden costs - networking
The cost of running a cluster in the cloud isn’t limited to CPU and storage: Specifically, when running a distributed database, you must always be mindful of the cost of moving data between nodes. This is further amplified in cases where you’re running a multi-region distributed database, as is the case here. For reference, the cost of moving data around in Google Cloud has four tiers that are relevant to us:
Moving a small amount of data around is fairly inexpensive, but over time, these charges can add up.
As mentioned above, each preemption results in us losing all local storage attached to a given node. As a result, in reseeding the node post-preemption, we must transfer a set of replicas to the given node approximately equal to 6.7% the size of the total data on the cluster (one node out of 15). For a cluster with 20 TiBs of active data, this results in approximately 1.33 TiB of data being moved around in each preemption. At that scale, preemption costs are non-trivial and must be factored into any cost savings calculation.
Unfortunately, the math is not simple. As mentioned above, when a preemption occurs there are three distinct phases:
leaseholder acquisition
up-replication
rebalancing
Leaseholder acquisition requires a trivial amount of data, and doesn’t meaningfully contribute to the cost calculations. When up-replicating and rebalancing however, the cluster may need to move much more than 1.33TiB of data around for a 15-node, 20TiB cluster. This is because data is moved multiple times, first to ensure that the cluster archives its availability targets as quickly as possible, and then to return the cluster to optimal performance.
There's one other factor that adds to the difficulty in predicting the cost of a preemption: We can’t accurately determine in advance how data will flow through the cluster. This is because during the initial up-replication and subsequent rebalancing, some data will move between VMs in the same zone, some will move cross zones, and some will move cross regions. Each of these transfers are charged differently, which makes it difficult to estimate an accurate transfer cost up front.
How much data is actually moved, and more importantly, the cost of moving that data, was something that we needed to investigate before we could determine if testing on spot instances would be a cost saving endeavor. Since we were unable to predict the cost in advance, however, we had to measure it after the fact.
To illustrate the network transfer costs associated with preemptions, the graph below shows an analysis of the data transfer costs of running the cluster over an 11-day period:
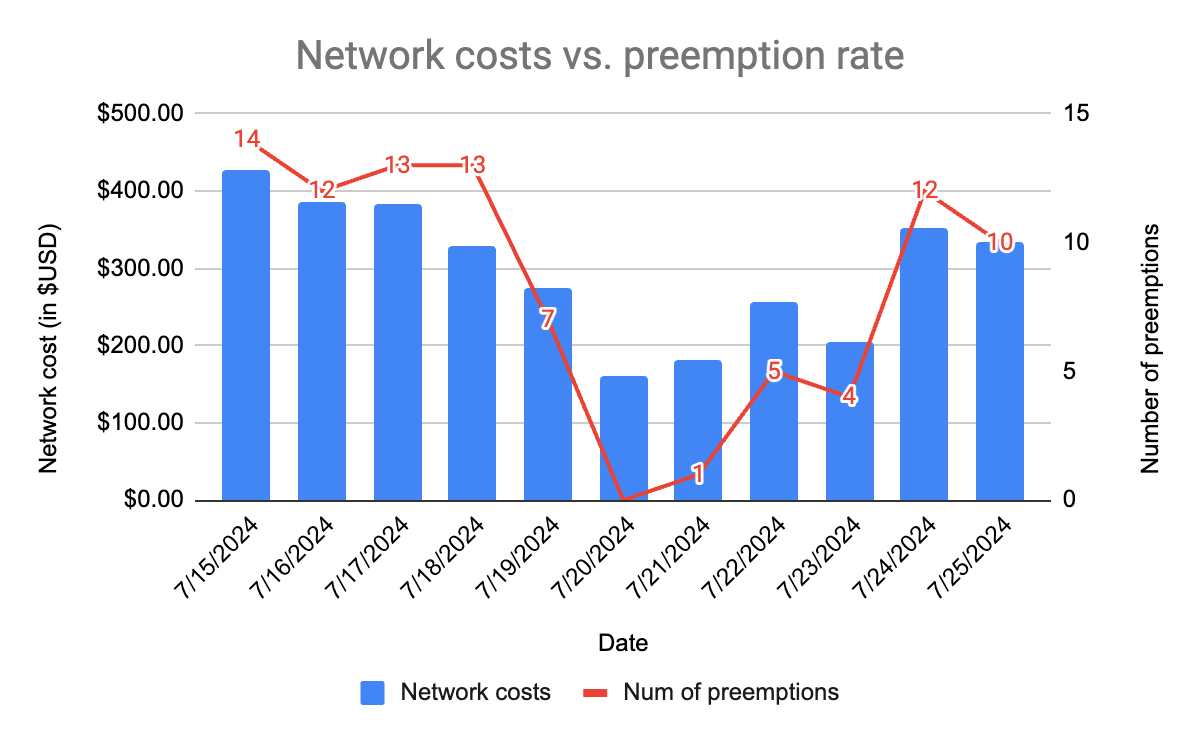
During the time period analyzed the preemption rate per day ranged from 0 (on 7/20), all the way up to 14 (on 7/15). Similarly, we can see that the network transfer costs are roughly correlated to the number of preemptions (something we’d expect).
To determine the actual cost of each preemption, we took the day where there were no preemptions as a transfer cost baseline (the baseline cost of running a distributed database across three regions) and determined how much spend each preemption incurred over and above the baseline. This analysis is shown below:
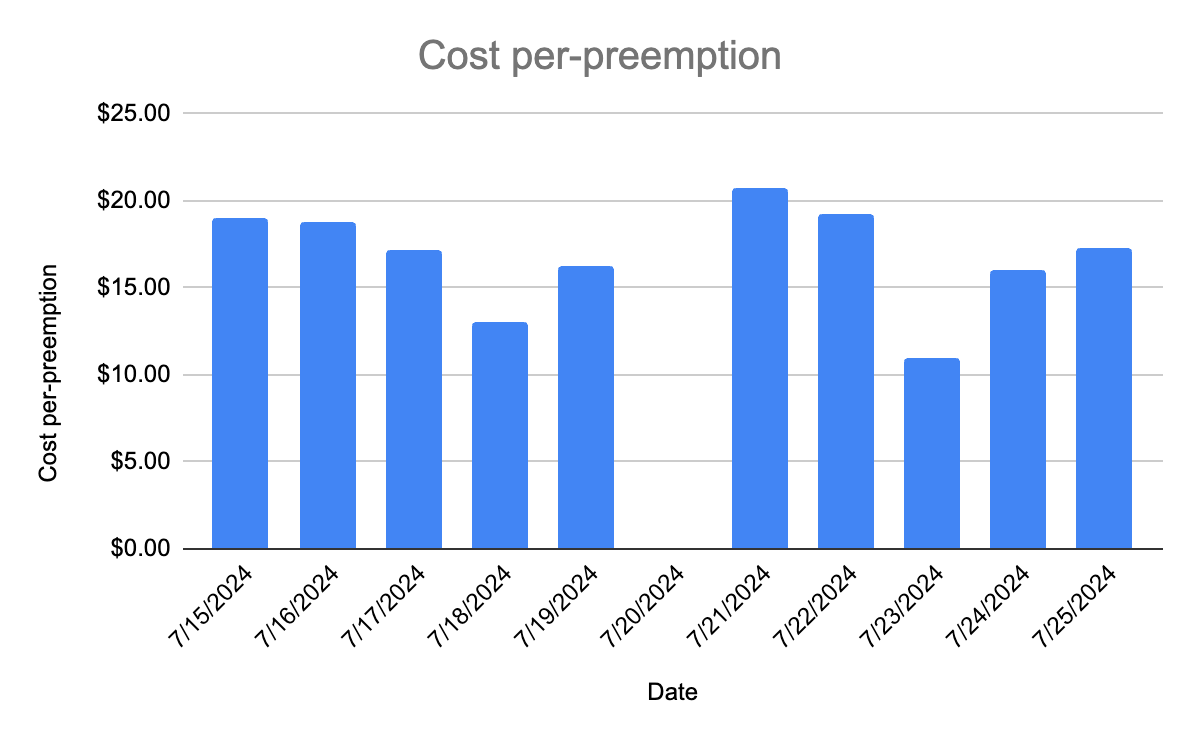
While the cost per preemption is not fixed, we see that the range is between $11 and $21. Why such a stark difference? By looking at the most and least expensive days (on a per-preemption basis) we can see why costs fluctuate so much. On 7/23 we saw four preemptions, at a cost of $11 each. A closer look however, shows this:

During a seven-minute period between 10:24:52 and 10:31:52, node 11 was preempted three times. While the system is able to transfer some amount of data to compensate for the first two preemptions, the bulk of the transferred data occurs after the third preemption. As a result, this cluster of preemptions behaves more closely to a single preemption, than it does three distinct preemptions.
Conversely, the most expensive preemption came on 7/21, when only a single preemption occurred and the cost was $21. This implies that the true cost of an isolated preemption is around $21. In general, we’ve found that as preemptions are often clustered, the average network transfer cost of a preemption hovers around $15.
With the cost of an average preemption calculated, what can we say about the cost savings of running this CockroachDB cluster on spot instances? Let’s take a deeper look.
The 15-node cluster that we’re operating costs $7,413 per month using un-discounted on-demand pricing. An identical cluster with persistent instances is $16,659. The difference is $9,246 a month, which works out to around 616 preemptions at $15 each, or approximately 20 per day. Over the course of July 2024, our cluster’s nodes were preempted 270 times, thereby allowing us to realize more than half of the savings of running on spot instances.
Preemptions are not equally distributed
As hinted at above, preemptions are not uniform across nodes, zones or regions. In fact, a look at the preemptions we experienced throughout July shows an interesting picture:
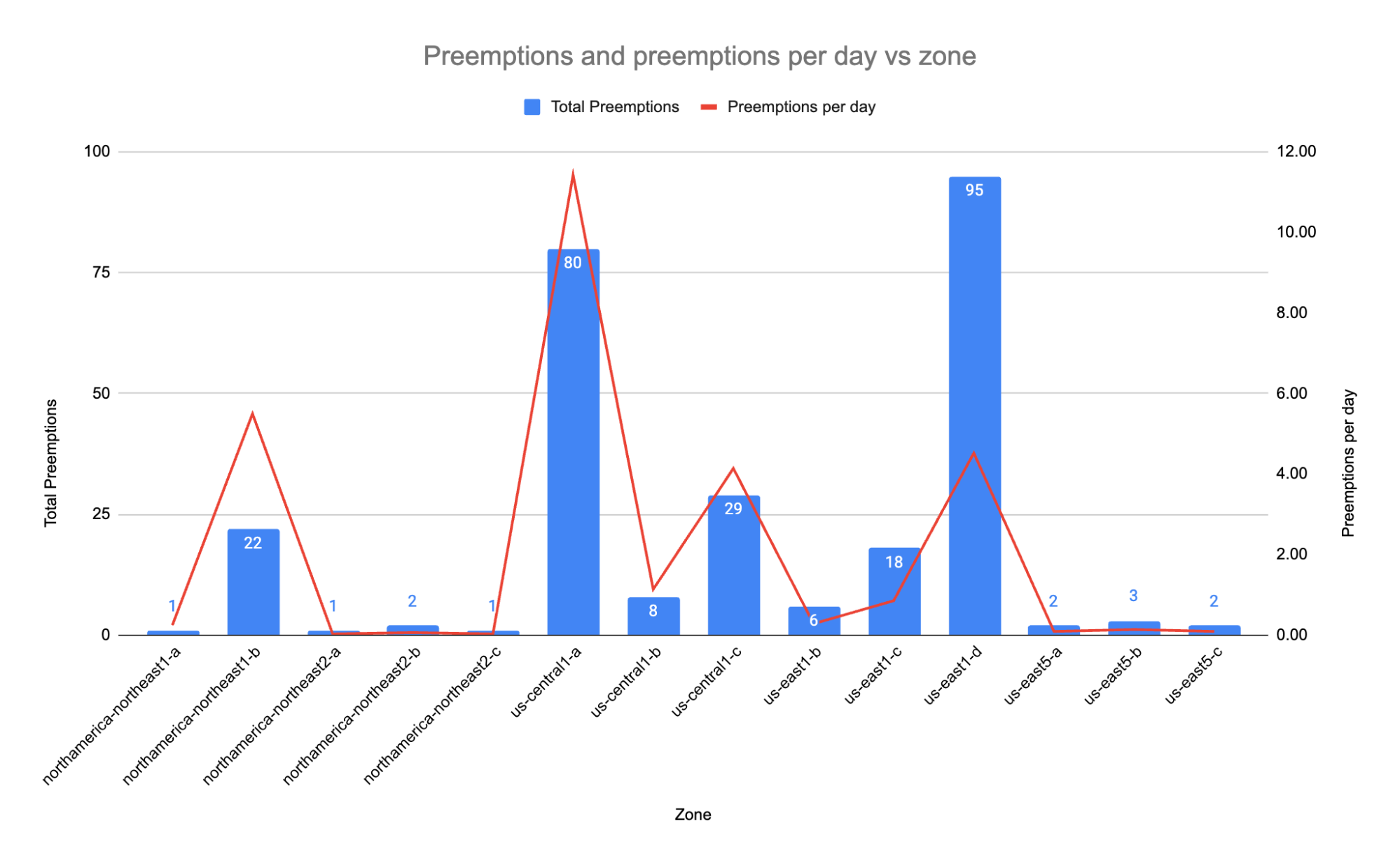
The chart above shows both the total preemptions (in blue - left axis) as well as the preemptions per day (in red - right axis). Over the month we reconfigured the cluster several times and ended up testing in 14 different GCP zones.
In some zones, we saw as few as one preemption, while in other zones, we were preempted as much as 95 times. Similarly, the preemption-per-day metric varied from almost 0 (0.03 to be exact), all the way up to 11.43 (in us-central1-a). While we’d like to have some preemptions to drive fault tolerance testing, more than 11 preemptions every day in a single zone is a lot, and doesn’t drive much testing value above much lower rates.
After some experimentation with various configurations, we landed on a cluster which yields just over six preemptions per day across the 15-node cluster. Amortized out to a 30-day month, this works out to $2,700 per month in pre-emption related data transfer costs. Considering the difference in cost between a spot instance cluster and one running on reserved instances, even with the preemption costs, the use of spot instances is saving us more than $6,500 per month on this single cluster.
Two final notes on cost
A keen observer will have noticed that above we spoke about the desire to run a multi-region cluster across the Atlantic, and then our subsequent zone analysis only included zones in North America. This had to do with a very early cost analysis: After setting up our initial CockroachDB cluster, we determined fairly quickly that the preemption costs of up-replicating and rebalancing between North America and Europe was cost-prohibitive, especially since it wasn’t producing any additional testing value. While our initial cluster was configured in Toronto, Montreal and Warsaw, we quickly abandoned this configuration for a cluster entirely contained in North America, saving us close to 60% on data transfer costs (see table above).
Secondly, it’s worth addressing the fact that each of the cloud service providers provide steep discounting for committed usage. With a one-year commitment, the 15-node cluster mentioned above is 37% cheaper than on-demand pricing, and with a three-year commitment, it’s 55% cheaper.
So why not leverage committed usage discounting for our testing clusters? At CockroachDB, we value test cluster flexibility over cost predictability. While the example above outlines tests we ran on a 15-node cluster, in the past we’ve tested clusters as large as 1000 nodes, and cluster sizes everywhere in between. Additionally, we’ll often reconfigure a cluster several times during testing to validate that adding and removing nodes works as expected. Leveraging on-demand pricing, and optimizing the costs at that tier as much as possible, are paramount to maintaining our testing flexibility.
Cockroach thrives in chaos
Over the past five months of running this cluster on spot instances, we’ve only had to restore from a backup three times due to correlated preemption activity. Each of the three incidents were a result of a flurry of preemptions, across all three regions in which the cluster was running. This is one of those instances:
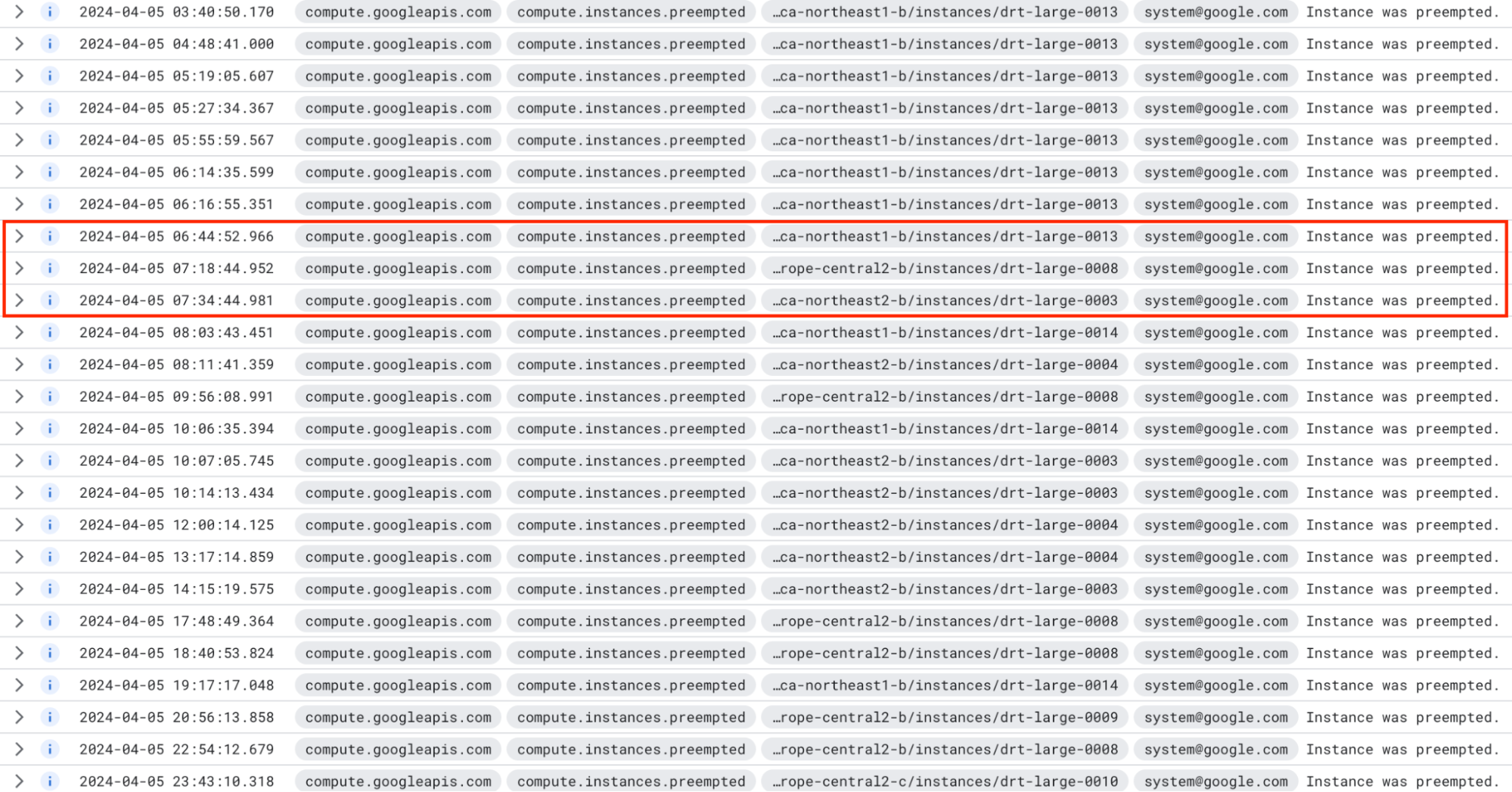
Over a 12-hour period, the cluster incurred 19 preemptions. For the most part, the cluster survived them, but during the period highlighted in red, three separate nodes, across all three regions, were preempted within an hour of each other. While up-replication saved most of the data, 7% of the data in the cluster was lost permanently due to the coordinated preemption activity.
Of note here is that this data loss is a byproduct of the fact that the cluster is running on local SSDs. If the cluster were configured to use network attached storage (Persistent Disks in GCP parlance), when the nodes were returned to the cluster, all of the lost data would have been recovered. This permanent data loss was a direct result of our desire to push this cluster into as cost-effective a form factor as possible, and would never be seen in production environments.
These coordinated preemption events are what caused us to further experiment with the preemption rates across different GCP regions. Since we’ve adopted our new region mix, over the past two months we haven’t had to restore the cluster from a backup once.
In terms of what this means for users of CockroachDB, running clusters on spot instances is supported (as part of our extensive support for self-hosted deployments). That being said, it’s important to consider both their advantages and disadvantages before embarking down the spot instance path. Clearly spot instances bring the promise of significant savings, but in doing so there’s a tradeoff around unexpected unavailability.
While the experiments above show how resilient a CockroachDB cluster can be when running on spot instances, it’s possible that all of a cluster’s spot instances will be preempted at the same time. As a result, any organization deploying a cluster entirely on spot instances must be open to total unavailability (and in the case of local storage - complete data loss) for the promise of cost savings. This makes spot instance clusters most suitable for staging or test clusters, where downtime and data loss may be more tolerable, as opposed to production clusters.
We’re only getting started
While this foray into spot instance testing has been insightful and rewarding, Cockroach Labs is only just getting started.
We have some future work planned to investigate how the use of the different variants of Persistent Disk, and even object storage, will impact test cluster stability and recovery, as well as cost. We’re also looking into how we can leverage reserved instances alongside spot instances to further stabilize the cluster, and allow us to safely run additional chaos operations in the presence of spot instance preemptions. Finally, we plan to reconfigure and extend this cluster regularly, as our testing needs evolve.
Learn more about how CockroachDB innovations help our customers scale.
Thanks to all of those at Cockroach Labs that contributed to the spot instance testing effort: Bilal Akhtar, Herko Lategan, David Taylor, BabuSrithar Muthukrishnan, Bhaskar Bora, Gourav Kumar, Sambhav Jain, Shailendra Patel and Vidit Bhat



![[image] finserv use cases](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2F00voh0j35590%2F61herWHcBa8OEwzsV20Vco%2F5971df8ab1da34f54d551ca1383e10ba%2FFinserv_use_cases_Blog_1920x1080__1_.png&w=3840&q=75)