
Companies are increasingly chasing zero-RPO and zero-RTO solutions to ensure that their applications remain online no matter what. And it’s easy to see why: according to 2020 research from Gartner the average cost of IT downtime is $5,600 per minute.
And that’s just the average! For many enterprises, an hour or two of downtime can mean millions of dollars in lost revenue.
Let’s take a closer look at RPO, RTO, and how new technologies are helping companies get achieve their zero-RPO and RTO goals.
What is RPO?
RPO stands for Recovery Point Objective. A company’s RPO is the maximum amount of data loss it considers acceptable when a failure or outage occurs.
RPO is typically measured in units of time. For example, a company with an RPO of ten minutes has decided that in the event of an outage, it can afford to lose up to ten minutes of data (lost transactions, etc.) before the company is seriously harmed.
Zero RPO is how companies describe a setup in which no data loss is acceptable, even in the event of an outage.
What is RTO?
RTO stands for Recovery Time Objective. A company’s RTO is the maximum amount of application downtime it considers acceptable when a failure or outage occurs.
RTO is also typically measured with units of time. A company with an RTO of ten minutes has decided that it can afford for its application to be offline for up to ten minutes in the event of an outage.
Zero RTO is how companies describe a setup in which application downtime is never acceptable, even when an outage occurs. (Technically speaking, zero RTO may not be possible, but we’ll discuss that in more detail later in this article. For now, let’s say that zero RTO means no perceptible downtime from a user perspective.)
RTO vs. RPO: what’s the difference and how do they interact?
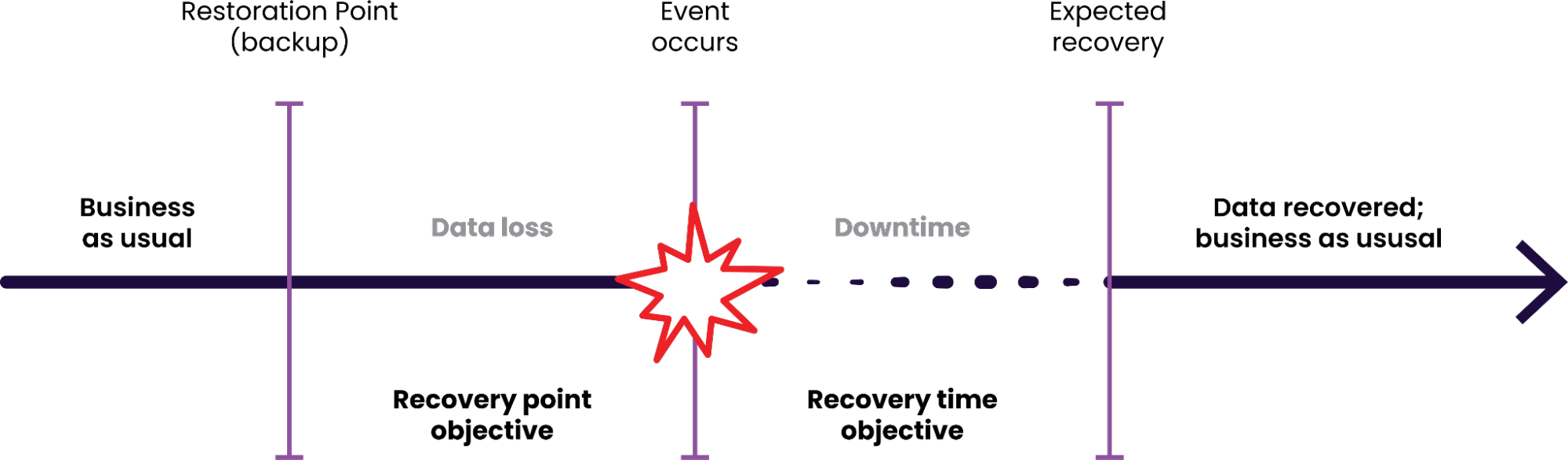
RPO and RTO are related, but not the same.
For example, it is possible for a company to lose no data during an outage, but still have application downtime (zero RPO but non-zero RTO).
On the other hand, a company could also have application architecture that ensures no application downtime but still allows for some data loss during the changeover when one node goes offline and its traffic is re-routed elsewhere (non-zero RPO and zero RTO).
For most companies, low RPO and RTO are both important. Implementing efficient distributed application architecture is the primary method for achiving both. As a result, the two are often discussed together.
Why RPO and RTO are so important to business success
Both RTO and RPO can have a direct impact on revenue (applicaiton downtime and lost data can both lead to lost sales), and they also impact it indirectly in a variety of ways.
For example, if a customer’s order is lost due to an outage, or they try to log in to their banking application but it doesn’t work due to an outage, their trust in the company is going to be reduced, and the likelihood that they churn is increased.
RELATED
How to build a payments system that scales to infinity (with examples)
When outages result in data loss or downtime that must be manually remedied, this also impacts the other work that employees can do. Often, it also impacts work/life balance (outages don’t always happen at convenient times), and thus RTO and RPO can also impact employee productivity, satisfaction, and retention.
None of this is theoretical. Outages happen all the time (here’s a recent example as of this writing) and they can cost companies millions.
Because outages can be so costly, businesses care deeply about ensuring the resiliency and uptime of applications. CEOs, CIOs, and top level technology executives are focused on meeting application uptime goals and minimizing the cost of infrastructure-level failures. For DBA teams, this means defining and meeting recovery point objectives (RPOs) and recovery time objectives (RTOs) for different tiers of applications.
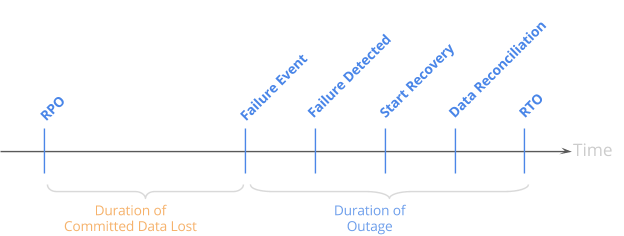
For mission-critical applications, businesses need to get as close to zero RPO and RTO as possible to minimize the overall risk to both the business and their customers. An application that handles financial transactions with a non-zero RPO could lose deposits or transactions. A reservation system could lose customer reservations. Even worse, losing patient data in real-time healthcare systems could directly impact patient safety.
Is zero RPO possible?
Yes. While it was once impossible, it is now possible to architect zero RPO systems.
However, it’s not easy! Building a zero RPO system is complex and requires the right choices at every level of your tech stack. The specific path to achieving zero RPO will vary depending on the application in question, but in general, it will require building distributed, multi-region, self-healing systems to insulate the application from the risks of things like machine failures and cloud AZ or region outages.
Because of this, zero RPO systems can be more costly than less resilient, less available systems. However, for mission critical workloads, the benefits and savings associated with not going offline and not losing data typically outweigh the increased costs that are sometimes associated with distributed systems.
With that said, the cost of embracing distributed architecture can also depend on the tools you use. For example, in the database layer, the cost and ease of running a distributed transactional database changes quite significantly (millions of dollars) depending on the tools you choose:
Is zero RTO possible?
Zero RTO is possible, at least from the perspective of a user or customer.
Imagine, for example, a distributed database with three nodes. If one node goes offline, the database software detects that and re-routes its traffic to another node. From a user perspective, there is no downtime, just a blip of increased latency (a few seconds at most, typically).
Technically, one could argue there is downtime in the time between when the node goes down and when the traffic is re-routed. But this is irrelevant from a user perspective (and thus, from a business perspective). Downtime only matters if it is perceptible to the user. If the application goes “offline” (node 1 down) but returns in a few seconds (queries re-routed to node 2) with no additional action required on the user’s part and no data lost, was it really “down” at all?
Not really. Downtime of minutes or hours can be an expensive disaster, but a few seconds of downtime is a blip that many users won’t even notice, and that virtually none would percieve as the application being unavailable or offline.
For that reason, even in the context of mission-critical workloads, most companies are concerned with minimizing RTO, but not necessarily worried about getting it to absolute zero.
To learn more about RPO, RTO, and operational resiliency, check out this deep dive by technical evangelist, Rob Reid:
What database is best for zero RPO and near-zero RTO?
While RTO and RPO matter at every level of the stack, the database layer is arguably the most critical to look at because of the potential for permanent data loss.
This is particularly true for systems that require strong consistency and durability. Think workloads such as payments, transactions, user accounts, identity and access management (IAM), logistics, etc. These are application systems where correctness, consistency, and availablity are all critical. If your application loses payment data, bad things happen.
These types of workloads typically run on relational databases to take advantage of the strong consistency and ACID transactional guarantees that they can offer. But achieving zero RPO is incredibly difficult if you’re trying to strap distributed functionality onto a relational database that wasn’t originally built with that in mind. For transactional workloads, it is generally both easier and cheaper to achieve zero RPO by migrating to a distributed SQL database such as CockroachDB.
CockroachDB delivers zero RPO while the reducing component complexity of IT resilience by 75% by eliminating the need for separate replication, clustering, and storage solutions in order to achieve fault-tolerance. Instead, everything comes built into the database software. This reduces the cost and complexity associated with purchasing, deploying, and managing multiple solutions from multiple vendors.
Unlike NoSQL, CockroachDB provides ACID guarantees through consensus-based replication, so data is always consistent and committed transactions are guaranteed to persist. CockroachDB can also be deployed on commodity hardware, since it has built-in resiliency for storage-level failures at the software layer. A more detailed description of each of the layers is available here.

Underneath the hood, CockroachDB intelligently replicates data across the cluster, spreading copies out across different availability zones to provide the highest level of fault tolerance based on the available infrastructure.
This means that for any hardware failure ranging from disk to datacenter-level disasters, CockroachDB can continue to serve client traffic while recovery takes place.
CockroachDB is also architected to support an average of 4.5 seconds RTO. This includes both the time it takes to detect a failure as well as the time it takes to recover from it.
Learn more about how CockroachDB can help you get to zero RPO and near-zero RTO.


