

Disasters are expensive. Hilariously expensive. In my career as a software engineer, I’ve employed a bunch of technologies and witnessed most of them - in some way - fail and cause downtime. Downtime (and the thought of downtime), alongside Toilet Time Debugging™, are among the endless reasons a Software Engineer may struggle to switch off.
Why does it have to be like this? Does it have to be like this? And what are the alternatives?
In this article, I’ll demonstrate CockroachDB’s resilience in the event of various disaster scenarios. Here’s a video of these scenarios, if video format works better for you:
Multi-active disaster recovery in CockroachDB
What is disaster recovery?
Simply put, Disaster Recovery (or DR) is something that happens after a disaster takes place. It’s an acknowledgement that not everything will always run smoothly and that once something does go wrong, an effort will need to be made to right it.
I’ve worked in a number of businesses where disaster recovery was the only viable failure strategy. Company-owned (or rented) infrastructure sits idle at another physical site, and team members pay it regular visits to prevent it from getting dusty or lonely. Tests would be performed on it to ensure it could kick into life, should the primary infrastructure fail.
During business as usual (BAU), the primary region would serve customer requests and daily backups would be taken of the database. Figure 1.1 shows a high-level view of the primary and DR site, along with a load balancer (LB) that’s currently routing traffic to the primary site.
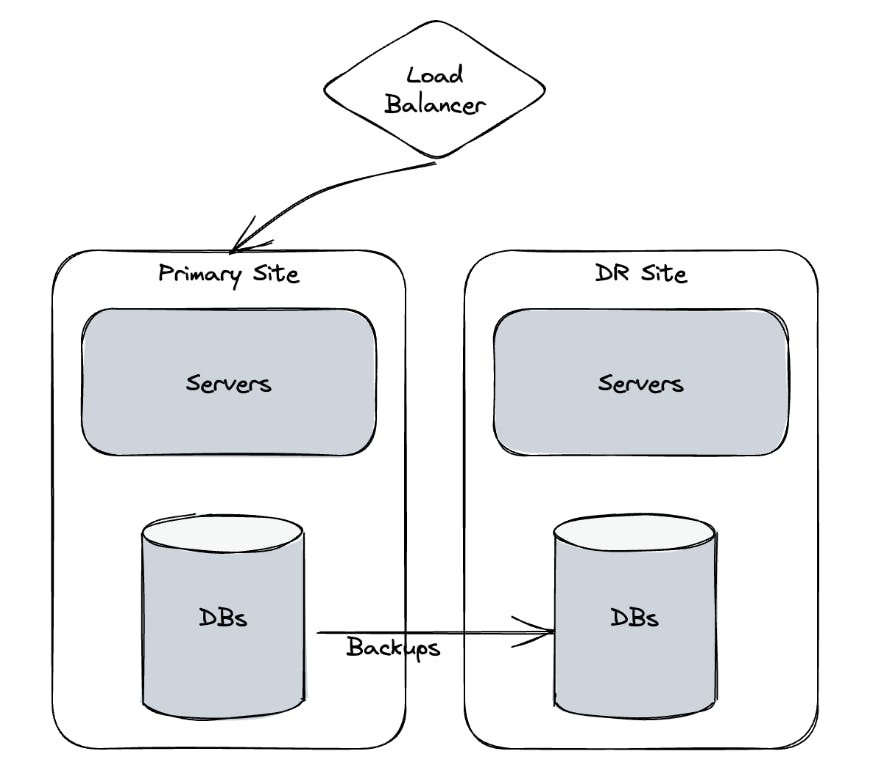
Figure 1.1 - BAU
In the event of a failure, the load balancer switches traffic to the DR site. Figure 1.2 shows a high-level view of a primary site failure and the load balancer rerouting traffic to the DR site.
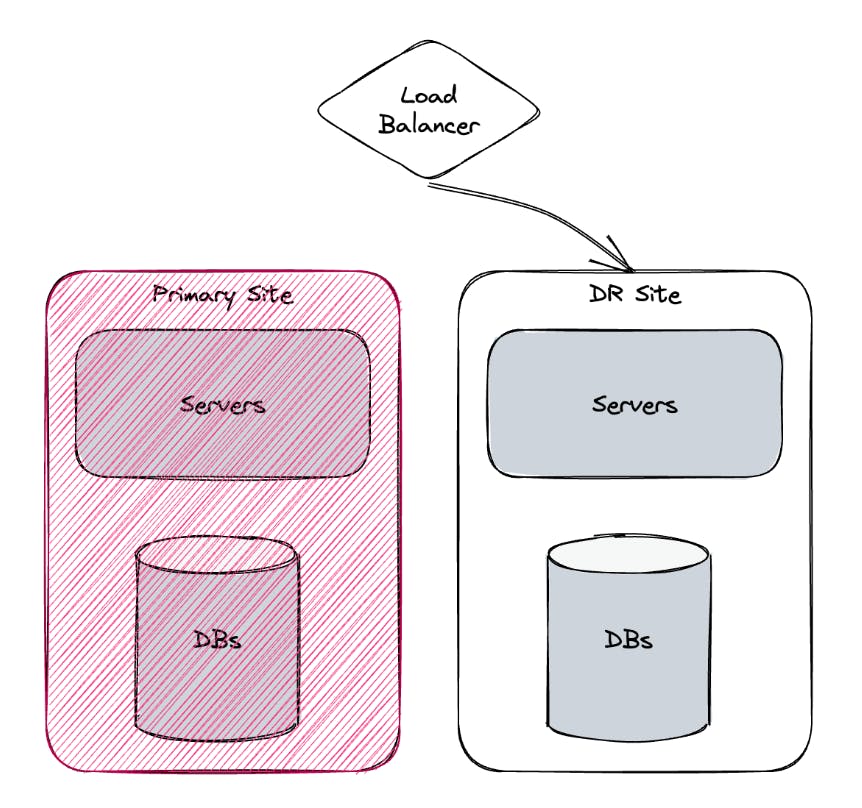
Figure 1.2 - Failure Mode
Once the failure has come to an end, the LB routes traffic back to the primary region and the database in the primary region needs to be informed of any changes. Figure 1.3 shows a high-level view of post-failure state, where the database in the DR site needs to backfill any missing data in the primary site’s database.
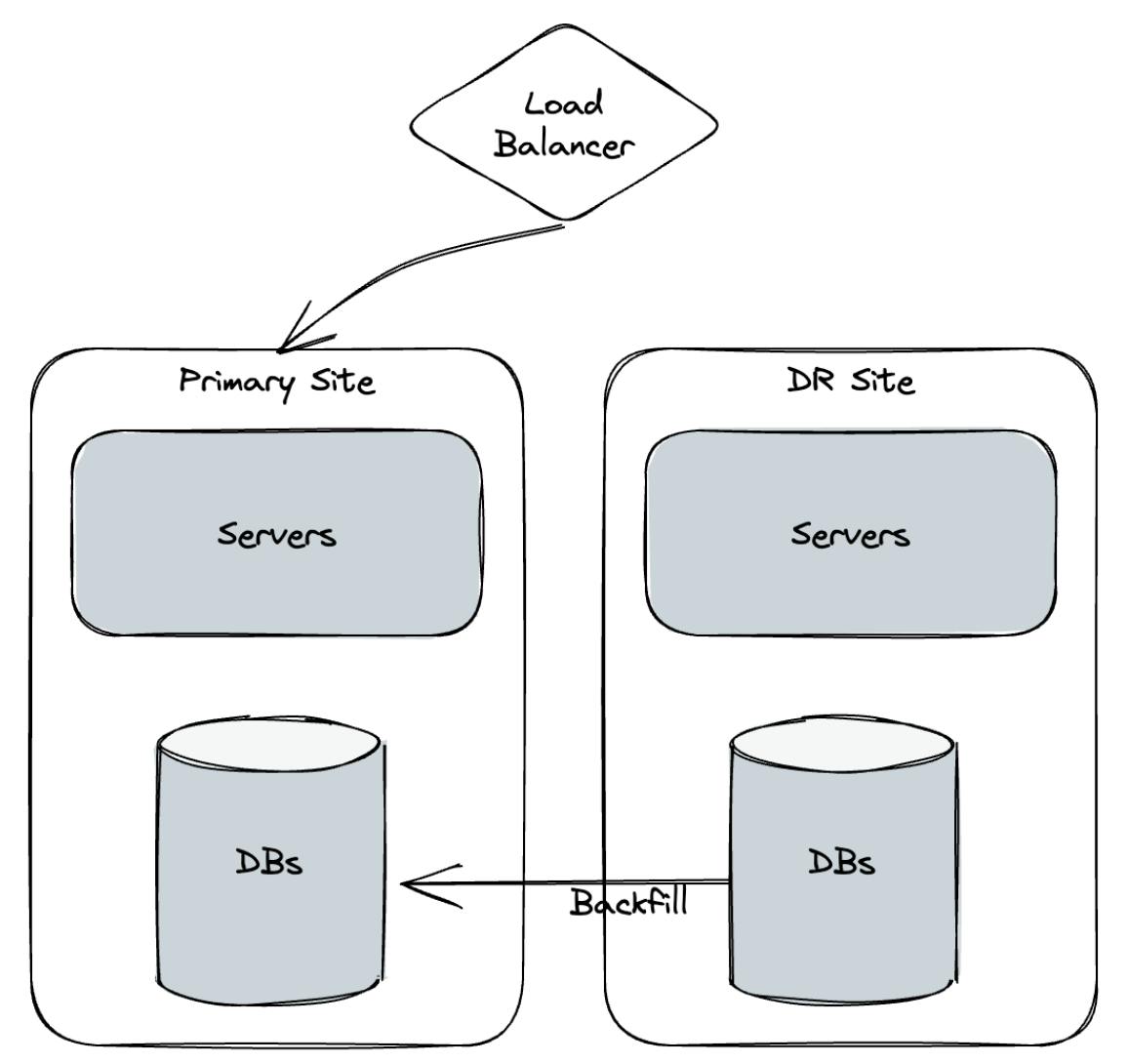
Figure 1.3 - Back to BAU
The DR process relies on a bunch of assumptions, that - if ignored - would only serve to prolong (or exacerbate) the disaster:
The DR site will not be affected by the same outage
The mechanism to switch between the primary and DR sites will work
The switch can happen fast enough to minimize the business impact
The software installed on our DR site is in-sync with our primary site
The difference in application state between the primary and DR site will be tolerable
Once the primary site is available again, everything can continue from where it left off
Assuming that none of the above have worsened the disaster, the very fact that we’re operating in a failure scenario, necessitates a difference between sites; be it that we’re now operating with last night’s database backup, or that we’ll have to reconcile our state once the disaster is over.
RELATED
What is operational resilience and how to achieve it
It would seem that managing more than one multi-million dollar infrastructure site is a very expensive, last-ditch approach to somewhat recovering from a disaster.
What are the disaster recovery alternatives?
The DR failure mode uses terms like “active/passive”, “active/backup”, “primary/secondary” and other terms, which don’t have a place in civilised vernacular.
Modern tools expand our vocabulary with terms like “active/active” and - in CockroachDB’s case - “multi-active”. These paradigm-altering technologies open the door to better approaches to disaster recovery, and, in some cases, prevent disaster altogether.
It’s been a long journey to get to where we are today and has involved many companies, consensus algorithms, and technological feats.
As far as databases are concerned, there are various approaches to disaster prevention. All of which are discussed in more detail in our Brief History of High Availability but I’ll touch on them again briefly here:
Active-Passive - the traditional approach to disaster recovery. One database is active, while the other sits idle until a disaster is encountered.
Active-Active - promotes availability over consistency and will traditionally involve either a single write node and multiple read nodes, or support multiple write nodes, with eventual consistency.
Multi-Active - CockroachDB’s approach to availability. Reads and writes are supported by all nodes, with guaranteed consistency being a priority.
CockroachDB, multi-active availability, and disaster prevention
CockroachDB was built to be a distributed, cloud-native database. The ease at which it can be horizontally scaled, enables its approach to disaster recovery; distribute wide enough, and you’ll survive anything and disaster will be prevented. Figure 2.1 shows a high-level view of a CockroachDB multi-region cluster.

Figure 2.1 - Multi-region CockroachDB cluster
In this configuration, we’ll survive multiple failure scenarios:
Node failure - the failure of a single node will not impact the cluster’s availability, as data will be replicated across other nodes.

Availability Zone (AZ) failure - the failure of a cloud AZ will not impact the cluster’s availability, as data is replicated across other AZs.
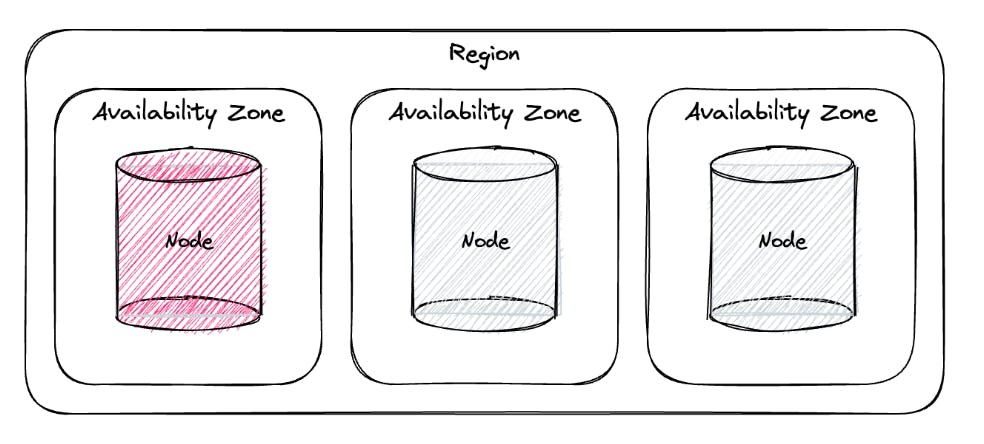
Region failure - the failure of a cloud region will not impact the cluster’s availability, as data is replicated across other regions.

Network partition - in the event of a network partition (where nodes remain online but unable to communicate with one another), CockroachDB will elect a new leaseholder for data on affected nodes based on the node’s ability to communicate with the majority of remaining nodes.

Operating CockroachDB in a disaster recovery model
If your team’s approach to disaster involves a DR site, CockroachDB can be used in a way that compliments this architecture, thanks to its support for SECONDARY REGIONS. In the following scenario, we’ll simulate the creation of a self-hosted, multi-region CockroachDB cluster that sports a PRIMARY and a SECONDARY region; both working together in a multi-active configuration.
First, let’s create a few nodes for our PRIMARY region. Note that I’ve called the regions “london-hq” and “edinburgh-dr” purely for demonstration purposes; you can call these whatever you like:
cockroach start \
--insecure \
--store=node1 \
--listen-addr=localhost:26257 \
--http-addr=localhost:8080 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=london-hq
cockroach start \
--insecure \
--store=node2 \
--listen-addr=localhost:26258 \
--http-addr=localhost:8081 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=london-hq
cockroach start \
--insecure \
--store=node3 \
--listen-addr=localhost:26259 \
--http-addr=localhost:8082 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=london-hq
cockroach start \
--insecure \
--store=node4 \
--listen-addr=localhost:26260 \
--http-addr=localhost:8083 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=edinburgh-dr
cockroach start \
--insecure \
--store=node5 \
--listen-addr=localhost:26261 \
--http-addr=localhost:8084 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=edinburgh-dr
cockroach start \
--insecure \
--store=node6 \
--listen-addr=localhost:26262 \
--http-addr=localhost:8085 \
--join='localhost:26257, localhost:26258, localhost:26259' \
--locality=region=edinburgh-dr
Next, we’ll initialize the cluster and enable an Enterprise License (this will allow us to configure the primary and secondary regions):
cockroach init --host localhost:26257 --insecure
cockroach sql --host localhost:26257 --insecure
SET CLUSTER SETTING cluster.organization = YOUR_ORGANISATION_NAME;
SET CLUSTER SETTING enterprise.license = 'YOUR_LICENSE_KEY';
Next, we’ll make CockroachDB aware of our regions:
ALTER DATABASE defaultdb SET PRIMARY REGION "london-hq";
ALTER DATABASE defaultdb ADD REGION "edinburgh-dr";
ALTER DATABASE defaultdb SET SECONDARY REGION "edinburgh-dr";Finally (and optionally), if you’d like to view these on the cluster map in the CockroachDB Console, add the location of the two regions to the system.locations table:
INSERT into system.locations ("localityKey", "localityValue", "latitude", "longitude") VALUES
('region', 'london-hq', 51.5072, 0.1276),
('region', 'edinburgh-dr', 55.955, -3.186);The next time you open the Node Map in the Console, you’ll see your primary and DR sites, as per Figure 3.1.

Figure 3.1 - Multi-region CockroachDB cluster with primary and DR regions
A wealth of information is available from the CockroachDB SQL Shell. The following queries will help you understand how CockroachDB is managing your regions and data:
SHOW REGIONS FROM DATABASE defaultdb;
region | zones | database_names | primary_region_of | secondary_region_of
---------------+-------+----------------+-------------------+----------------------
edinburgh-dr | {} | {defaultdb} | {} | {defaultdb}
london-hq | {} | {defaultdb} | {defaultdb} | {}As we can see from the above query, london-hq is the primary region for our database, while edinburgh-dr is our secondary region. In the event that our london-hq region becomes unavailable, our edinburgh-dr region will take over. All without human intervention.
Note: In order to truly survive regional failures, you’ll need to install CockroachDB across at least three regions, and set the survival goal for your database accordingly:
ALTER DATABASE defaultdb SURVIVE REGION FAILURE;CockroachDB will prevent you from setting the database survival goal to regional until you have three regions configured.
SELECT raw_config_sql FROM [SHOW ZONE CONFIGURATION FROM DATABASE defaultdb];
raw_config_sql
---------------------------------------------------------------------------
ALTER DATABASE defaultdb CONFIGURE ZONE USING
range_min_bytes = 134217728,
range_max_bytes = 536870912,
gc.ttlseconds = 90000,
num_replicas = 4,
num_voters = 3,
constraints = '{+region=edinburgh-dr: 1, +region=london-hq: 1}',
voter_constraints = '[+region=london-hq]',
lease_preferences = '[[+region=london-hq], [+region=edinburgh-dr]]'CockroachDB will ensure that there are four replicas of each piece of information in our database.
Personally, I would suggest that secondary regions are only really useful if you operate in a primary/DR configuration and need the leaseholder preference to shift from the primary region to the secondary in the event of a primary region outage. Configuring one primary region and multiple non-primary regions, will offer the same level of survivability.
Conclusion
Over the course of my career, I’ve noticed a departure from the mindset of “let’s hope disaster doesn’t happen but if it does, our team knows how to handle it” to the mindset of “we know disaster will happen, and when it does, our tools will know how to handle it”.
In the same way that it’s essential to plan for disaster recovery, it’s essential to understand how the infrastructure that your database depends on might fail, and how to mitigate the effects of those failures.
Install CockroachDB across at least three regions.
Within each region, install CockroachDB across at least three availability zones.
Understand CockroachDB’s survival goals and which one is right for your cluster.
Understand the implications of choosing a small number of large nodes against a large number of small nodes.
To learn more about Disaster Recovery and our approach to mitigating disaster altogether, visit the following documentation pages:
https://www.cockroachlabs.com/docs/stable/recommended-production-settings
https://www.cockroachlabs.com/docs/stable/when-to-use-zone-vs-region-survival-goals
https://www.cockroachlabs.com/docs/stable/multiregion-overview





