
Fintech companies are modernizing how they store and process institutional and retail trades. To understand how, we must first take a quick look at why – what these companies used to do, and why that approach is no longer considered acceptable.
The old way: struggling to achieve resilience at scale
In the past, their trade applications served high-net-worth clients with high-velocity streams of incoming event data such as feeds, trade data, orders, and fulfillment (to name a few). This data arrived across any number of nodes across many locations. Traditionally, finance companies would store data in a RDBMS to leverage the relational and durability benefits of products like Oracle or SQL Server.
However, at scale, a single-instance database struggles to service high volumes of transactions, as it is limited to only scaling vertically. To overcome this, inquiry transactions would be offloaded to an async cluster, such as Cassandra, other distributed NoSQL products, or Hadoop fast layers. Sometimes, this alternative was chosen to offload MIPS costs with trades hosted on Z/OS DB2.
But as time passed, a growing demand to move to more resilient data services has emerged. Fintech companies now want to ensure that node and data center outages will not disrupt services. They want zero downtime and zero data loss in the event of any infrastructure failure.
Legacy products such as DB2, Oracle and SQL Server can be made more resilient, but it requires layering in additional asynchronous technologies, brokers to monitor, and manual intervention during failover and failback processes. At the end of the day, they still can’t offer total resilience, and the complexity inherent in making them more resilient requires sacrificing ACID transactional guarantees for eventual consistency across nodes and data centers.
Below are two examples of approaches that attempt to bolt resiliency onto legacy RDBMS:

These architectures are riddled with cost, operational, and regulatory complexity:
Different databases hold replicas of the same data
These architectures require querying fast-moving data
Regulatory requirements mean having to prove that the different replica databases were all the same, with audited consistency across different data sources
There is a better way.
Reducing risk and complexity without sacrificing consistency at scale
Below, we present a simplified, modern approach to solving this problem for fintech companies. The complexity and risk has been reduced while guaranteeing data consistency across data centers at scale.
CockroachDB’s distributed nature and default multi-active configuration guarantees resiliency and very high availability while reducing the level of complexity required to make this type of system work at scale.

Let’s dive into a final state architecture for order trade executions. Logically, we have incoming data, intraday inquiry and adjustments, publishing data downstream to analytics, ODS, etc. All of the replication and data consistency is managed by the CockroachDB cluster automatically, using the RAFT protocol. The various physical locations of the nodes, starting with a minimum of three, can be scaled up to as many data centers/regions required to co-locate data closer to users while increasing the tolerance for failure.

The order execution end to end flow is as follows:
Order_1_received -> order_2_submit -> order_3_ack -> 2 order_executions
Each of these steps is made up of implicit transactions. For example:

This represents an order received:
WITH cte2 AS (INSERT INTO orders_trail VALUES ($1, $2, __more10__), (__more2__) RETURNING _),
cte1 AS (INSERT INTO orders VALUES ($37, $38, __more10__), (__more2__) RETURNING _)
SELECT
An order execution appears like this:
WITH batch_cte_0 AS (UPDATE orders SET executed_quantity = executed_quantity + $1, status = $2, modified_by = $3, modified_time = $4, trans_cdc_id = $5 WHERE (locality = $6) AND (orderid = $7) RETURNING __), batch_cte_1 AS (UPDATE orders SET executed_quantity = executed_quantity + $8, status = $9, modified_by = $10, modified_time = $11, trans_cdc_id = $12 WHERE (locality = $13) AND (orderid = $14) RETURNING __), batch_cte_2 AS (UPDATE orders SET executed_quantity= executed_quantity + $15, status = $16, modified_by = $17, modified_time = $18, trans_cdc_id = $19 WHERE (locality = $20) AND (orderid = $21) RETURNING __), cte5 AS (INSERT INTO activity VALUES ($22, $23, ____more9___), (____more2_ RETURNING __) SELECT
These transactions can enter at any point in the cluster, as all nodes are equal. Each node can perform SQL transactions, can handle DML, and can inquire to the schema entities across the cluster.
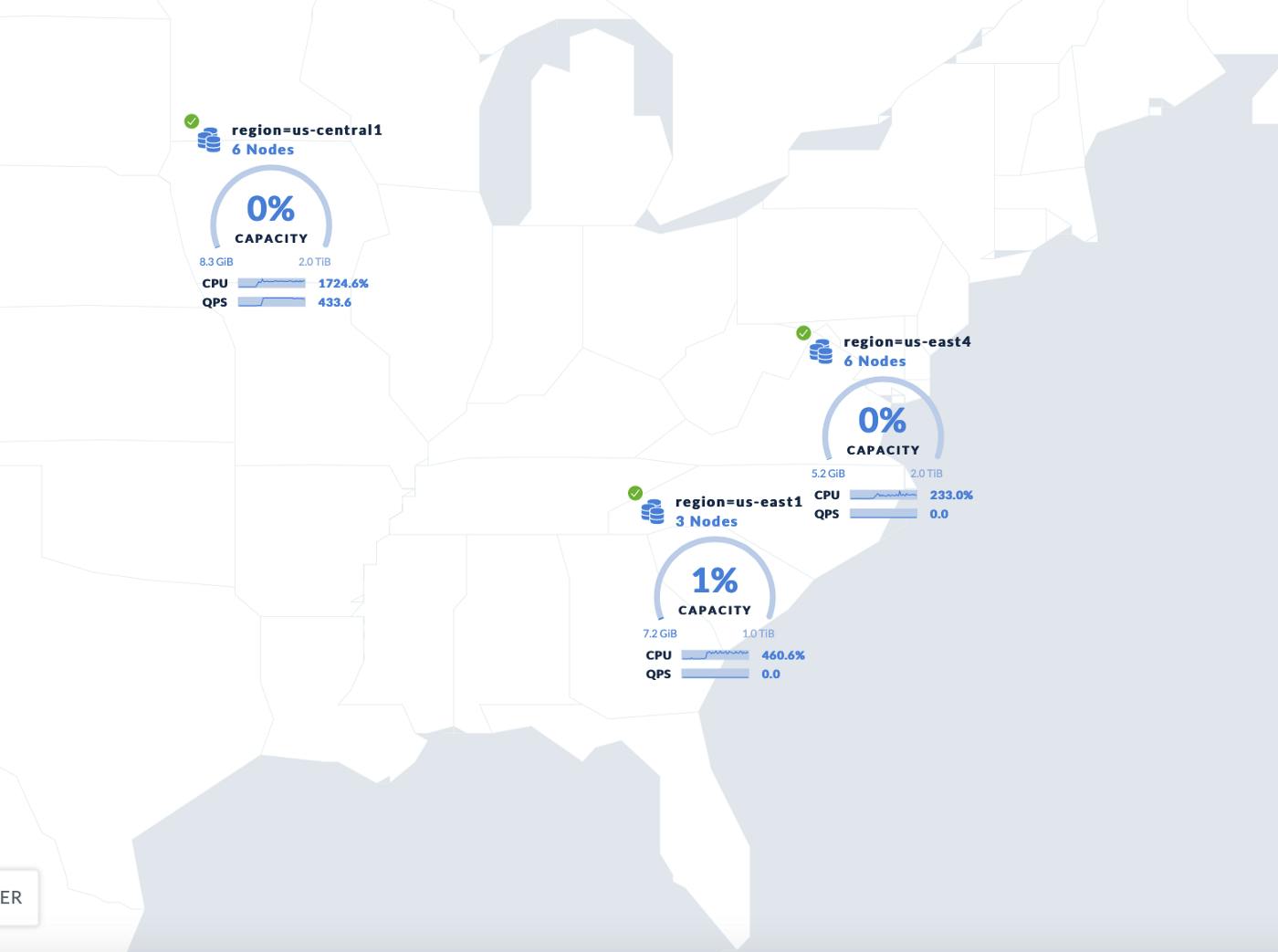
Often, fintech companies also have requirements around data expiration and emitting all appropriate change events to targets, such as an analytics layer and ODS. To handle these requirements, in CockroachDB we can enable TTL on the rows for all schema entities and enable changefeeds.
These changefeeds will publish all change events to an external source, such as Kafka or sink storage, while protecting the data with a closed timestamp before it can be removed.



