
Note: This article makes reference to offerings and licensing information which are now out of date. Please refer to this blog post for the most current information about CockroachDB licenses.
Batch data sucks — it’s slow, manual, cumbersome, and often stale. We know because we’ve dealt with these problems ourselves. Any business needs to track metrics, from customer activity to the internal workings of the company. But how can we keep those metrics up to date to extract maximum business value?
Here at Cockroach Labs we build CockroachDB, a distributed database meant to survive everything and thrive everywhere. CockroachDB is primarily optimized for transactional- “OLTP”- data, and sometimes it is advantageous to stream that data to an analytical warehouse to run frequent, large queries. That’s what we do with our “telemetry data” — the data we collect internally on product usage.
Telemetry data, anonymized and captured only from those users who do not opt-out, helps us track feature usage and make product decisions. Telemetry helped inform the decision to move distributed backup and restore to CockroachDB Core. It has also informed our use of free trial codes for CockroachDB Dedicated dedicated clusters in places like our Cockroach University classes. We’re a fast-moving startup, and having this data up-to-date and easily available to stakeholders is key for us to make the best product decisions for our users. That’s why we moved from batch uploading our telemetry data to streaming this data using changefeeds.
Our original approach: Weekly cron jobs, batch updates, and Snowflake
We host telemetry data in an internal production system that runs on CockroachDB Dedicated, our managed database-as-a-service. To avoid borking the cluster every day by pulling the latest data from multi-TB sized tables, we previously stored an extra copy locally and batch uploaded it to Snowflake weekly.
This approach had many shortcomings. For one, it relied on a weekly cron job or a nudge of “Hey Piyush, can you update the data for me?” to keep the data up to date. This process proved fragile, unreliable, and took more time and energy than it needed to. The data was also not kept as up-to-date as we would have liked. Frustrated with this process, we turned to using one of our native database features to give us faster, easier, and more reliable data updates: changefeeds.
Streaming data out of CockroachDB Dedicated using change data capture (CDC)
CockroachDB’s change data capture (CDC) process watches a table or set of tables, picks up on any changes to the underlying data, and emits those changes via a changefeed. The changefeed streams the updated rows in near real-time out of the database to an external sink (i.e., Kafka or cloud storage).
For example, our product team uses the table FEATURES to keep track of how often features are used. When a row is added to the FEATURES table logging usage of the SQL command INSERT, the changefeed will pick up on the added row and emit it to an external system. The message will look something like this:
{{
"__crdb__":{
"updated":<timestamp 1>
},
"feature":"sql.insert.count.internal",
"internal":false,
"node":1,
"timestamp":<timestamp 2>,
"uptime":2106051,
"uses":100,
"version":"v19.1.2"
}}
This is a simple concept but allows us to build powerful applications. An application can take advantage of the transactional guarantees of CockroachDB while ensuring other applications that rely on the information are kept up-to-date in near real-time. Change data capture can be a key component of microservice architectures; it can also be used to keep auditable data logs.
The changefeeds native in CockroachDB allow us to stream data automagically and in near real-time out of CockroachDB Dedicated to a cloud storage sink and then to Snowflake. By using changefeeds to stream data to analytical tools, we take advantage of purpose-built solutions for internal analytics while maintaining the high performance of the underlying database.
Making the switch to using changefeeds has added robustness and reliability to our process: data streaming isn’t interrupted by vacation days, sick days, or home internet connectivity problems. It has allowed us to go from weekly to daily or near real-time metrics, allowing us to diagnose problems earlier.
For example, on two occasions we noticed dips in our Net Promoter Score (NPS) due to stale versions of CockroachDB being published as the most recent version to tools like Homebrew or Docker. With streaming analytics, we can now alert on our NPS score and see version breakdowns immediately rather than a week later. We can resolve issues like this quickly. Ultimately, this change has freed up time so that we can focus on what really matters: creating value for our users.
How we did it
The journey of our data looks something like this:
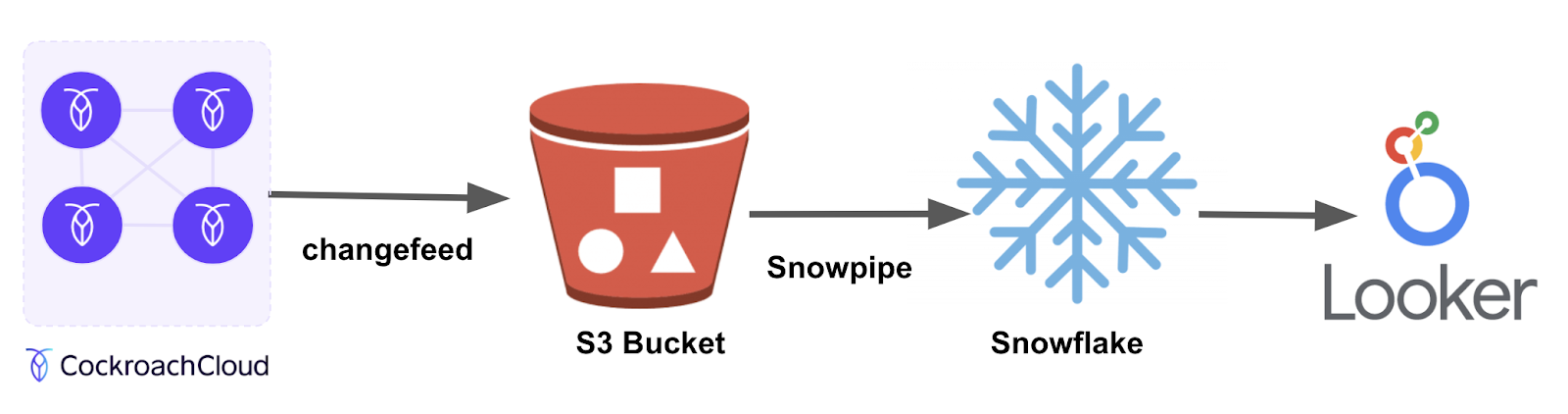
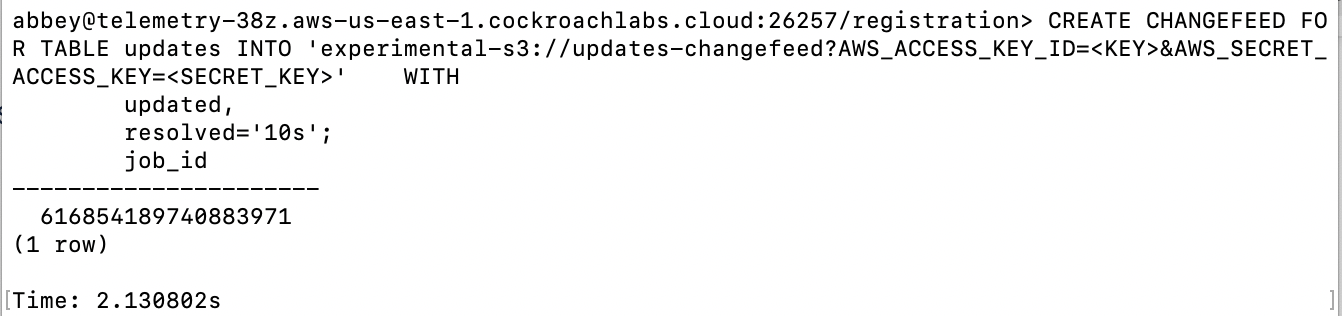
We first use an AWS S3 bucket as a general-purpose data dump. Cockroach supports S3 as a native sink for changefeeds. S3 buckets also support auto-ingesting of data into Snowflake, making S3 an ideal dump for the changefeed data in this case.
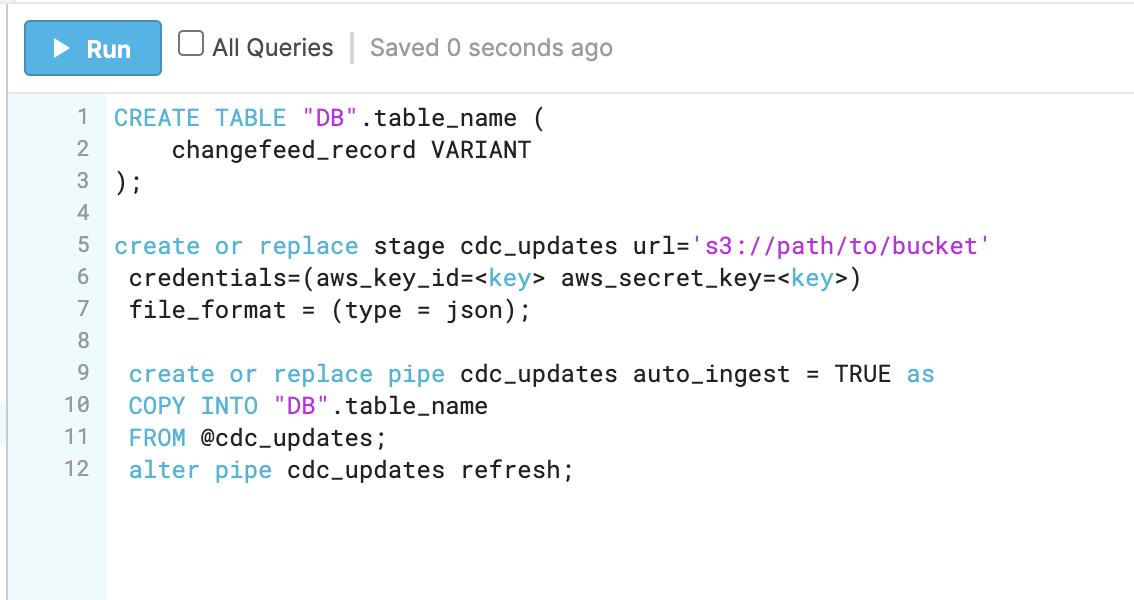
We then load the data into Snowflake, using Snowpipe. Snowflake automatically picks up on the diffs of the data, and auto-ingests the changes. If you have workloads with a large amount of updates (vs append-only) you’ll need to do some preprocessing of the data before sending the data to Snowflake. Though we use Snowflake, you can use the OLAP database of your choice.
Our Looker instance reads from Snowflake as a data source, aggregating the data and displaying it in dashboards. Looker is a purpose-built business intelligence tool that makes it easy to build beautiful dashboards out of complex data queries.

Example Dashboard from Looker docs
Chaining these tools helps us get the best out of each application and makes our overall data stack more powerful. Using changefeeds to stream data updates has led to more granular, up-to-date dashboards that we use to drive product decisions. As a startup, we need data to move fast and innovate. Additionally, the ability to quickly identify and fix problems is invaluable, since negative impressions can deal a fatal blow to a nascent company. When stale versions of CockroachDB were published to package management tools, it gave the impression that our product underperformed and was potentially less stable than expected. Mistakes will happen. Reducing the costs of mistakes like this is key to our long term success.
Tutorials/Resources
The best place to start to explore doing something similar with your CockroachDB cluster is our tutorial on streaming changefeeds to Snowflake. You will be taken step-by-step through the process of auto-ingesting database changes into Snowflake.
From there you can connect Snowflake to Looker, Tableau, or your business intelligence software of choice.
Note: This tutorial uses enterprise changefeeds to stream to a configurable cloud storage sink. Core changefeeds will not be able to natively connect to a cloud storage sink.


