

I’ve long extolled the benefits of CockroachDB and its ability to horizontally scale for reads and writes. I’ll frequently contrast it with databases that require their users to manually shard in order to achieve scale. To avoid being disingenuous, I decided to put my money where my mouth is and give it a go myself.
To borrow from a video where I horizontally scale a Postgres database:
"This one broke me."
In this post, I’ll walk you through the steps I used to manually shard, scale, and - in so doing – completely break a Postgres database. If you’d prefer to watch me suffer, here's the video:
What we're going to do
The infrastructure you run after five or ten years in business won't resemble the infrastructure that you started with on Day One. Your assumptions will continually be challenged and need to be re-evaluated as you learn more about your application and its users.
Starting off small is the best way to kickstart your business. After all, you don't know how successful your application will become or how obsessively your users will consume it.
As your business grows, your applications and databases must scale with them to ensure a smooth experience for all users.
I want this scaling exercise to reflect the real world, so I'll start with a single node of Postgres and make no assumptions about the scale that I'll eventually require. I'll simulate a small UK-based business that grows in the UK before gaining US-based customers. I'll scale the database in the following three increments:
Year 1 - Increased demand from UK customers (hash sharding)
Year 2 - Increased demand from UK customers (re-sharding)
Year 5 - The business scales into the US (geo-partitioning and re-sharding)
Here's a diagram of the steps we'll be taking:
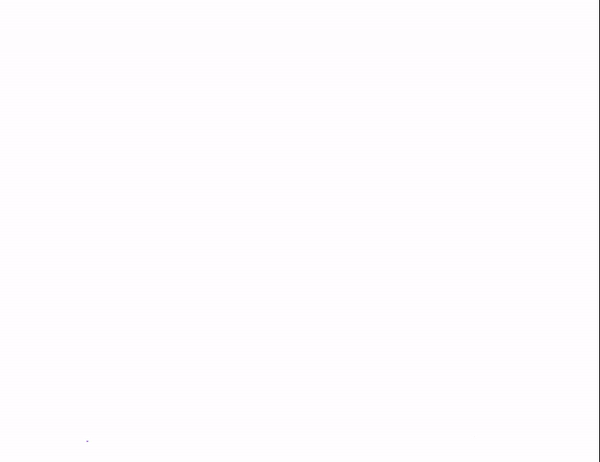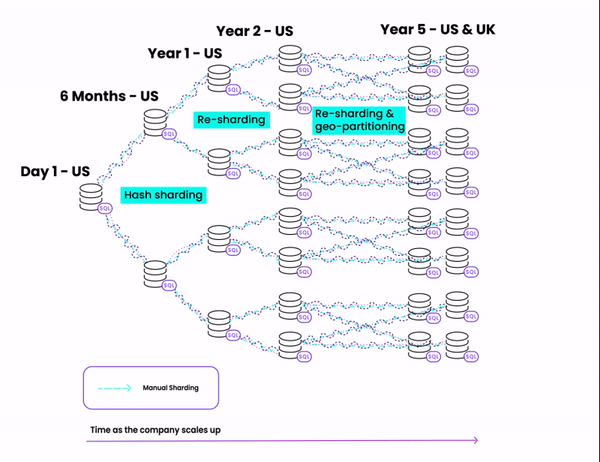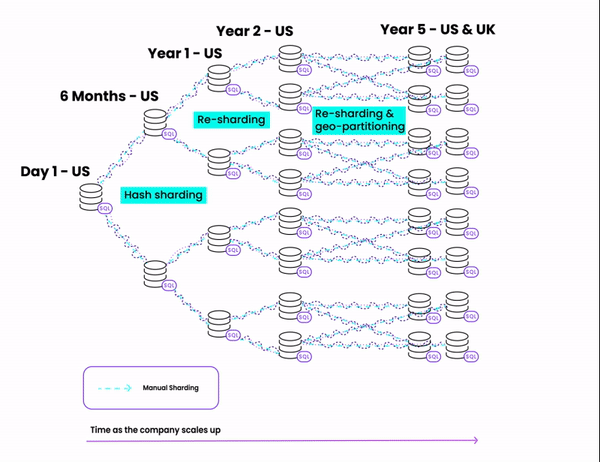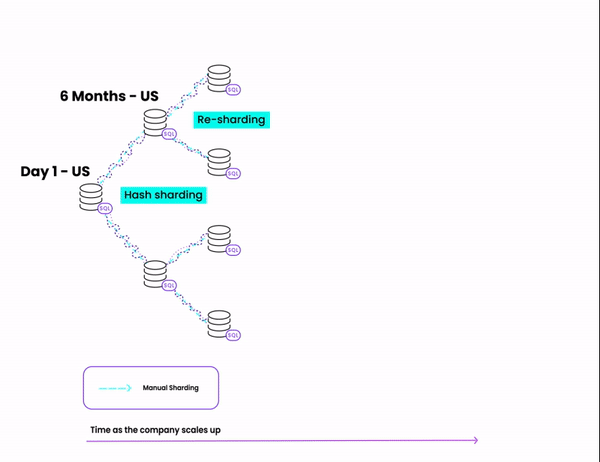
How to [badly] shard a Postgres database
LET'S GO!
First, I'll spin up a Postgres node using Docker and connect to its shell:
docker run -d \
--name eu_db_1 \
--platform linux/amd64 \
-p 5432:5432 \
-v eu_db_1:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
psql "postgres://postgres:password@localhost:5432/?sslmode=disable"
Next, I'll create a table and insert 1,000 rows into it:
CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL
);
INSERT INTO customer (id, email)
SELECT
gen_random_uuid(),
CONCAT(gen_random_uuid(), '@gmail.com')
FROM generate_series(1, 1000);
Year 1 scale-up
Let's now assume that one year has passed, and the demand on our application has increased to a point where we can no longer avoid scaling the database. Let's spin up a second Postgres node:
docker run -d \
--name eu_db_2 \
--platform linux/amd64 \
-p 5433:5432 \
-v eu_db_2:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
These nodes are currently running in isolation, completely unaware of each other. Let's change that by making the first node aware of the second.
First, I'll add the Foreign Data Wrapper (FDW) extension to both the eu_db_1 and eu_db_2 nodes; this will allow the nodes to communicate with each other. Note that because everything is running locally, I don't need to add anything to the pg_hba.conf files on either node:
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
The database won't automatically replicate across nodes. I'll need to duplicate (and maintain) schema objects on all nodes. I'll start by creating the customer table on the eu_db_2 node:
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL
);"
Next, I'll make the eu_db_1 node aware of the eu_db_2 node by creating a SERVER object via the FDW:
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE SERVER eu_db_2 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'host.docker.internal',
port '5433',
dbname 'postgres'
);"
In order to access schema objects on another node, I'll need to map a user from one node to another. In this example, I already have a "postgres" user, so I’ll use that. In the real-world, this is a bad idea because the “postgres” user has root privileges; your user should only have the absolute minimum privileges to allow for multi-node communication.
I'll map the “postgres” user on the eu_db_1 node to the “postgres” user on the eu_db_2 node and grant it access to the foreign server object:
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE USER MAPPING FOR postgres
SERVER eu_db_2
OPTIONS (
user 'postgres',
password 'password'
);
GRANT USAGE ON FOREIGN SERVER eu_db_2 TO postgres;"
Next, I'll partition the table on eu_db_1. As I'll want both nodes to share 50% of the workload, I'm using a simple HASH partition by hashing the id and using the modulo result to determine on which node a row should reside. As the existing customer table isn't partitioned, I'll need to create another table that is partitioned.
CREATE TABLE customer_partitioned
(LIKE customer)
PARTITION BY HASH (id);
CREATE TABLE customer_0 PARTITION OF customer_partitioned
FOR VALUES WITH (MODULUS 2, REMAINDER 0);
CREATE FOREIGN TABLE customer_1
PARTITION OF customer_partitioned
FOR VALUES WITH (MODULUS 2, REMAINDER 1)
SERVER eu_db_2
OPTIONS (
table_name 'customer'
);I'll now populate the partitioned table from the original table. Note that if this table is already large, the eu_db_1 node may need more disk to handle this next operation; this operation will require downtime.
INSERT INTO customer_partitioned
SELECT * FROM customer;
With the data in both tables, we can now drop the original table and rename the partitioned table. This will continue the downtime period, which will only end once this operation completes:
BEGIN;
DROP TABLE customer;
ALTER TABLE customer_partitioned RENAME TO customer;
COMMIT;
To test that the partitioning has worked as expected, I'll insert 1,000 more rows into the table so we can see how it's distributed across both nodes:
INSERT INTO customer (id, email)
SELECT
gen_random_uuid(),
CONCAT(gen_random_uuid(), '@gmail.com')
FROM generate_series(1, 1000);
Selecting the row count from the customer table and its two shards reveals that the table's 2,000 rows have been evenly distributed across both nodes:
SELECT COUNT(*) FROM customer;
count
-------
2000
(1 row)
SELECT COUNT(*) FROM customer_0;
count
-------
1021
(1 row)
SELECT COUNT(*) FROM customer_1;
count
-------
979
(1 row)
Inspecting the underlying table size also reveals how Postgres sees the table and its data:
SELECT
table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))),
pg_relation_size(quote_ident(table_name))
FROM information_schema.tables
WHERE table_schema = 'public'
ORDER BY table_name;
table_name | pg_size_pretty | pg_relation_size
------------+----------------+------------------
customer | 0 bytes | 0
customer_0 | 128 kB | 98304
customer_1 | 0 bytes | 0
(3 rows)
Postgres knows that the customer table is essentially virtual and the customer_0 and customer_1 shards are where the data physically resides. What's interesting is that while the customer_0 shard appears to have data, the customer_1 shard does not. This is simply because the data does not physically exist on the eu_db_1 node, where I'm making the query.
Having reached the end of our first-year's scaling simulation, it's important to stress that this is all being performed locally on my machine, so I haven’t had to configure any firewall rules via the pg_hba.conf files for nodes to become reachable.
Year 2 scale-up
We're another year into our business and the need to scale the database has resurfaced. Let's scale from two nodes to three, to cope with demand from our increasing user base. We'll start by bringing the third node online:
docker run -d \
--name eu_db_3 \
--platform linux/amd64 \
-p 5434:5432 \
-v eu_db_3:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
To participate in the cluster, the eu_db_3 node will need the FDW extension, so we'll start by enabling that:
psql "postgres://postgres:password@localhost:5434/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
As with the eu_db_2 node, we have to manually create and maintain all database objects, which includes the creation of the customer table:
psql "postgres://postgres:password@localhost:5434/?sslmode=disable" \
-c "CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL
);"
Next, we'll make the eu_db_1 aware of the new eu_db_3 node by creating a SERVER object that maps to the new node. We'll also create a user mapping to allow the “postgres” user to access database objects on the new node:
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE SERVER eu_db_3 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'host.docker.internal',
port '5434',
dbname 'postgres'
);"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE USER MAPPING FOR postgres
SERVER eu_db_3
OPTIONS (
user 'postgres',
password 'password'
);
GRANT USAGE ON FOREIGN SERVER eu_db_3 TO postgres;"
Our original assumption – that we'd only need to scale across two nodes – is now incorrect and therefore so is our hash partitioning strategy. We'll need to update it from determining a destination node based on the remainder of MODULUS 2 to work off the remainder of MODULUS 3.
As Postgres doesn't allow us to reshard tables in-place, we'll need to create some new tables. I'll start by creating a customer_new table on eu_db_2 that we'll reshard inline with our new three-way sharding strategy:
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "CREATE TABLE customer_new (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL
);"
Back on eu_db_1, I'll create a new table for our three-way sharding strategy and then create two foreign tables, one for the new customer table on eu_db_3 and another for our customer_new table on eu_db_2:
CREATE TABLE customer_partitioned
(LIKE customer)
PARTITION BY HASH (id);
CREATE TABLE customer_0_new PARTITION OF customer_partitioned
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE FOREIGN TABLE customer_1_new
PARTITION OF customer_partitioned
FOR VALUES WITH (MODULUS 3, REMAINDER 1)
SERVER eu_db_2
OPTIONS (
table_name 'customer_new'
);
CREATE FOREIGN TABLE customer_2_new
PARTITION OF customer_partitioned
FOR VALUES WITH (MODULUS 3, REMAINDER 2)
SERVER eu_db_3
OPTIONS (
table_name 'customer'
);
I'll backfill the new tables with our existing table data (remember that this should be performed during a period of downtime if consistency is required):
INSERT INTO customer_partitioned
SELECT * FROM customer;
Next, I'll rename all of the tables to clean things up. The downtime window will end after the operation completes:
BEGIN;
DROP TABLE customer;
ALTER TABLE customer_partitioned RENAME TO customer;
ALTER TABLE customer_0_new RENAME TO customer_0;
ALTER TABLE customer_1_new RENAME TO customer_1;
ALTER TABLE customer_2_new RENAME TO customer_2;
COMMIT;
I'll insert 1,000 new rows to test the table's new hash sharding strategy:
INSERT INTO customer (id, email)
SELECT
gen_random_uuid(),
CONCAT(gen_random_uuid(), '@gmail.com')
FROM generate_series(1, 1000);
And see how they've been distributed across the nodes:
SELECT COUNT(*) FROM customer;
count
-------
3000
(1 row)
SELECT COUNT(*) FROM customer_0;
count
-------
1015
(1 row)
SELECT COUNT(*) FROM customer_1;
count
-------
993
(1 row)
SELECT COUNT(*) FROM customer_2;
count
-------
992
(1 row)
As expected, the now-3,000 rows are more or less evenly distributed across the three nodes, thanks to our new MODULUS 3 partition strategy. The same goes for the underlying table data; Postgres can see that roughly the same amount of data (~1,000 rows) exists on each of the nodes:
SELECT
table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))),
pg_relation_size(quote_ident(table_name))
FROM information_schema.tables
WHERE table_schema = 'public'
ORDER BY table_name;
table_name | pg_size_pretty | pg_relation_size
------------+----------------+------------------
customer | 0 bytes | 0
customer_0 | 128 kB | 98304
customer_1 | 0 bytes | 0
customer_2 | 0 bytes | 0
As a final tidy-up, we'll want to rename the customer_new table on eu_db_2 back to “customer”, so that it's consistent with the table’s names on the other servers. This will result in another period of downtime, while the foreign table mapping becomes temporarily unavailable:
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "BEGIN;
DROP TABLE customer;
ALTER TABLE customer_new RENAME TO customer;
COMMIT;"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "ALTER FOREIGN TABLE customer_1
OPTIONS (
SET table_name 'customer'
);"
Year 5 scale-up
Our fictional UK-based company is now five fictional years down the road and is steadily building a fictional US-based fanbase! 🎉
To give our US customers (especially those on the West Coast) the best experience of our application, our database will need to be closer to them. Let's spin up three new nodes to simulate nodes in the US:
docker run -d \
--name us_db_1 \
--platform linux/amd64 \
-p 5435:5432 \
-v us_db_1:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
docker run -d \
--name us_db_2 \
--platform linux/amd64 \
-p 5436:5432 \
-v us_db_2:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
docker run -d \
--name us_db_3 \
--platform linux/amd64 \
-p 5437:5432 \
-v us_db_3:/var/lib/postgresql/data \
-e POSTGRES_PASSWORD=password \
postgres:16
Onto these nodes, we'll install the FDW extension:
psql "postgres://postgres:password@localhost:5435/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
psql "postgres://postgres:password@localhost:5436/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
psql "postgres://postgres:password@localhost:5437/?sslmode=disable" \
-c "CREATE EXTENSION IF NOT EXISTS postgres_fdw;"
And on each node, we'll create the customer table:
psql "postgres://postgres:password@localhost:5435/?sslmode=disable" \
-c "CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL
);"
psql "postgres://postgres:password@localhost:5436/?sslmode=disable" \
-c "CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL
);"
psql "postgres://postgres:password@localhost:5437/?sslmode=disable" \
-c "CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL
);"
As the customer table already exists on eu_db_2 and eu_db_3, let's create a customer_new table on each of those so we can repartition without running into issues:
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "CREATE TABLE customer_new (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL
);"
psql "postgres://postgres:password@localhost:5434/?sslmode=disable" \
-c "CREATE TABLE customer_new (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL,
region VARCHAR(255) NOT NULL
);"
Next, we'll make the original eu_db_1 node aware of the three new US-based nodes and map their “postgres” users:
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE SERVER us_db_1 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'host.docker.internal',
port '5435',
dbname 'postgres'
);"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE SERVER us_db_2 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'host.docker.internal',
port '5436',
dbname 'postgres'
);"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE SERVER us_db_3 FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'host.docker.internal',
port '5437',
dbname 'postgres'
);"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE USER MAPPING FOR postgres
SERVER us_db_1
OPTIONS (
user 'postgres',
password 'password'
);
GRANT USAGE ON FOREIGN SERVER us_db_1 TO postgres;"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE USER MAPPING FOR postgres
SERVER us_db_2
OPTIONS (
user 'postgres',
password 'password'
);
GRANT USAGE ON FOREIGN SERVER us_db_2 TO postgres;"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "CREATE USER MAPPING FOR postgres
SERVER us_db_3
OPTIONS (
user 'postgres',
password 'password'
);
GRANT USAGE ON FOREIGN SERVER us_db_3 TO postgres;"
Now we're ready to repartition. This time, hash partitioning alone won't cut it; we'll need a new, hierarchical partitioning strategy. For this, we'll use a combination of List Partitioning and hash partitioning.
This hierarchical partitioning will resemble the following structure, with a list partition comprising the values "uk" and "us", and hash partitions for each of the partitions within the list partition:
customer table
List partition
UK
Hash partitioning (MODULUS 3)
eu_db_1 (remainder 0)
eu_db_2 (remainder 1)
eu_db_3 (remainder 2)
US
Hash partitioning MODULUS 3
eu_db_1 (remainder 0)
eu_db_2 (remainder 1)
eu_db_3 (remainder 2)
First, let's create a new list partitioned customer table (remember we can't repartition the existing customer table):
CREATE TABLE customer_partitioned (
LIKE customer,
region VARCHAR(255) NOT NULL DEFAULT 'uk'
)
PARTITION BY LIST (region);
Next, we'll create a US version of the table, for any values that include "us" as part of their list partition value. I'll also enable hash partitioning, allowing us to distributed US data across multiple nodes:
CREATE TABLE customer_us PARTITION OF customer_partitioned
FOR VALUES IN ('us')
PARTITION BY HASH (id);
CREATE FOREIGN TABLE customer_us_partitioned_0
PARTITION OF customer_us
FOR VALUES WITH (MODULUS 3, REMAINDER 0)
SERVER us_db_1
OPTIONS (
table_name 'customer'
);
CREATE FOREIGN TABLE customer_us_partitioned_1
PARTITION OF customer_us
FOR VALUES WITH (MODULUS 3, REMAINDER 1)
SERVER us_db_2
OPTIONS (
table_name 'customer'
);
CREATE FOREIGN TABLE customer_us_partitioned_2
PARTITION OF customer_us
FOR VALUES WITH (MODULUS 3, REMAINDER 2)
SERVER us_db_3
OPTIONS (
table_name 'customer'
);
I'll do exactly the same again, but this time for "uk" data:
CREATE TABLE customer_uk PARTITION OF customer_partitioned
FOR VALUES IN ('uk')
PARTITION BY HASH (id);
CREATE TABLE customer_uk_partitioned_0 PARTITION OF customer_uk
FOR VALUES WITH (MODULUS 3, REMAINDER 0);
CREATE FOREIGN TABLE customer_uk_partitioned_1
PARTITION OF customer_uk
FOR VALUES WITH (MODULUS 3, REMAINDER 1)
SERVER eu_db_2
OPTIONS (
table_name 'customer_new'
);
CREATE FOREIGN TABLE customer_uk_partitioned_2
PARTITION OF customer_uk
FOR VALUES WITH (MODULUS 3, REMAINDER 2)
SERVER eu_db_3
OPTIONS (
table_name 'customer_new'
);
Then backfill all data from the existing customer table into the newly partitioned customer tables (note the need for downtime if consistency is important):
INSERT INTO customer_partitioned
SELECT * FROM customer;
Then drop the original table and replace it with the partitioned version (as with the previous destructive operations, once complete, our downtime window will end):
BEGIN;
DROP TABLE customer;
ALTER TABLE customer_partitioned RENAME TO customer;
COMMIT;
Finally, we'll insert more test data and run some queries to show that data has been split across regions and nodes:
INSERT INTO customer (id, email, region)
SELECT
gen_random_uuid(),
CONCAT(gen_random_uuid(), '@gmail.com'),
('{uk, us}'::TEXT[])[CEIL(RANDOM()*2)]
FROM generate_series(1, 1000);
Row counts across the tables:
SELECT COUNT(*) FROM customer;
count
-------
4000
(1 row)
SELECT COUNT(*) FROM customer_uk;
count
-------
3513
(1 row)
SELECT COUNT(*) FROM customer_uk_partitioned_0;
count
-------
1144
(1 row)
SELECT COUNT(*) FROM customer_uk_partitioned_1;
count
-------
1246
(1 row)
SELECT COUNT(*) FROM customer_uk_partitioned_2;
count
-------
1123
(1 row)
SELECT COUNT(*) FROM customer_us;
count
-------
487
(1 row)
SELECT COUNT(*) FROM customer_us_partitioned_0;
count
-------
145
(1 row)
SELECT COUNT(*) FROM customer_us_partitioned_1;
count
-------
181
(1 row)
SELECT COUNT(*) FROM customer_us_partitioned_2;
count
-------
161
(1 row)
Looking at the table stats, we see a similar story to the previous queries, in that only the local node appears to have data. We can see from the above queries that this is, of course, not the case:
SELECT
table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))),
pg_relation_size(quote_ident(table_name))
FROM information_schema.tables
WHERE table_schema = 'public'
ORDER BY table_name;
table_name | pg_size_pretty | pg_relation_size
---------------------------+----------------+------------------
customer | 0 bytes | 0
customer_uk | 0 bytes | 0
customer_uk_partitioned_0 | 160 kB | 122880
customer_uk_partitioned_1 | 0 bytes | 0
customer_uk_partitioned_2 | 0 bytes | 0
customer_us | 0 bytes | 0
customer_us_partitioned_0 | 0 bytes | 0
customer_us_partitioned_1 | 0 bytes | 0
customer_us_partitioned_2 | 0 bytes | 0
(9 rows)
As a final cleanup, we'll rename any instances of customer_new back to customer (noting again that this will result in a period of downtime, while the foreign table mapping becomes temporarily invalid):
psql "postgres://postgres:password@localhost:5433/?sslmode=disable" \
-c "BEGIN;
DROP TABLE customer;
ALTER TABLE customer_new RENAME TO customer;
COMMIT;"
psql "postgres://postgres:password@localhost:5434/?sslmode=disable" \
-c "BEGIN;
DROP TABLE customer;
ALTER TABLE customer_new RENAME TO customer;
COMMIT;"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "ALTER FOREIGN TABLE customer_uk_partitioned_1
OPTIONS (
SET table_name 'customer'
);"
psql "postgres://postgres:password@localhost:5432/?sslmode=disable" \
-c "ALTER FOREIGN TABLE customer_uk_partitioned_2
OPTIONS (
SET table_name 'customer'
);"
This is not a working solution!
Before you attempt to recreate what you've seen here, please don't!
It was at this point that I realized why databases like AWS Aurora and GCP Postgres funnel all writes through one node. What I've created, through this process of sharding and resharding, is essentially a database that scales for reads but not writes. Unless all writes go through our first node, eu_db_1 (which has knowledge of all of the other nodes), nothing will work as expected. If I insert data directly against one of the other nodes, all of the rows I insert will end up on that node, with no distribution of data between other nodes.
Even worse? Data is now easily corruptible. I can insert duplicate primary keys into the table, simply because unless all inserts go through the first (or "primary") node, there's no validation. Let me demonstrate with a few simple queries:
First, I'll select a random customer out of the table on node eu_db_1:
SELECT * FROM customer ORDER BY RANDOM() LIMIT 1;
id | email | region
-------------------------------------+------------------------------------------------+--------
c9e35251-02f2-451e-9ee2-0cc8773bf9ef | 2a950743-1aba-431a-b0b9-99a2ba8f1465@gmail.com | uk
(1 row)
Next, I'll show that this row doesn't exist on another (us_db_1):
SELECT * FROM customer WHERE id = 'c9e35251-02f2-451e-9ee2-0cc8773bf9ef';
id | email | region
----+-------+--------
(0 rows)
Now I'll insert that exact same record into the us_db_1 node:
INSERT INTO customer (id, email, region) VALUES ('c9e35251-02f2-451e-9ee2-0cc8773bf9ef', 'duplicate@gmail.com', 'uk');
INSERT 0 1
Back on eu_db_1, I'll run a select for that id and we'll see there is now a duplicate primary key id:
SELECT * FROM customer WHERE id = 'c9e35251-02f2-451e-9ee2-0cc8773bf9ef';
id | email | region
-------------------------------------+------------------------------------------------+--------
c9e35251-02f2-451e-9ee2-0cc8773bf9ef | 2a950743-1aba-431a-b0b9-99a2ba8f1465@gmail.com | uk
c9e35251-02f2-451e-9ee2-0cc8773bf9ef | duplicate@gmail.com | uk
(1 row)
Forcing all updates to go through a single node prevents this kind of issue, but in doing so severely limits your database’s ability to horizontally scale.
Summary
I've just sharded one table in a database that might contain hundreds of tables, each with their own requirements on data locality and backups. I found the process of sharding a single table with zero backups complex enough, without having to think about how multiple tables will further complicate things...
Database sharding is a concern best left to your database. It's not something you should have to spend your time worrying about. If you do, that's time you're not dedicating to making your products better. It slows you down and makes you less agile to changing requirements – allowing time for your competition to beat you to market in other areas.
Another important consideration when it comes to database scaling is elasticity. Your application's workload (and user base) will grow and shrink over time. The cluster we've configured in this post only covers the growth part of that scenario and doesn't factor in how to scale down, following a decrease in demand. Your cluster might therefore be over-provisioned during periods of lower demand, resulting in unnecessary costs.
How CockroachDB takes the pain out of scaling
CockroachDB was designed to make horizontal scaling easy. You simply add nodes to or remove nodes from your cluster and it rebalances data for you. If you need to pin data to different locations, you can harness CockroachDB's built-in topology patterns, which optimize data placement for different use cases and requirements.
Contrast the ease of simply adding a node to a cluster versus repartitioning a database with downtime. The contrast in operational complexity is extreme.
The simplification is immediately apparent when we look at the architecture of the CockroachDB equivalent setup (note that the node count during Year five is arbitrary in this case):

What we've achieved with this partitioning demo is a broken version of what CockroachDB would enable with the following statement:
CREATE TABLE customer (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) NOT NULL
) LOCALITY REGIONAL BY ROW;
Note the only difference between this statement and the Postgres equivalent is the inclusion of the LOCALITY REGIONAL BY ROW statement, which instructs CockroachDB to pin data to different regions and nodes, based on the value of a hidden column called "crdb_region". This column will be added to any table with a locality of REGIONAL BY ROW unless manually specified at CREATE time and can either be populated manually during INSERT/UPDATE, or automatically, based on the locality of the client making the request.
What this demo doesn't achieve is a way to replicate table data around the world for low-latency read access to the same data from anywhere. This can be achieved in CockroachDB with the help of the GLOBAL TABLES topology, which looks like this:
CREATE TABLE product (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name VARCHAR(255) NOT NULL
) LOCALITY GLOBAL;
By sharding a single table, I’ve only scratched the surface of the complexities involved in horizontally scaling a Postgres database. From my still limited exposure, it’s something I would never want to be tasked with, or be responsible for in a production environment; there’s simply too much that can go wrong.
CockroachDB’s built-in horizontal scaling allows me to focus my efforts on providing business value. Scaling is performed automatically for me, in a way that’s safe and consistent – just as it should be with any modern system.


