


This blog post is co-written by Drew Kimball, Member of Technical Staff, Rachael Harding, Member of Technical Staff, and Dingding Lu, Former Staff Product Manager.
User-defined functions (UDFs) and stored procedures (SPs) allow users to define a set of queries that can be executed at the database by providing only the function or procedure name and any relevant parameters. They provide building blocks for users to compose complex queries, which makes applications less error prone since users don’t need to repeatedly provide the complex query. Another benefit of UDFs/SPs is that they enable better performance by moving more computation closer to the data. There are fewer round trips between the application and database to get the results the user wants.
CockroachDB strives for compatibility with PostgreSQL, and supporting UDFs and SPs has been an interesting technical challenge for our team. So far, CockroachDB supports UDFs and SPs in the SQL and PLpg/SQL languages. PLpg/SQL is a powerful SQL procedural language that adds control structures on top of SQL, allowing even more complex computation such as loops, conditional statements, and exceptions.
A Basic UDF/SP with CockroachDB 
Let’s take a deeper look at user-defined functions, starting with the UDF example_func below:
CREATE TABLE tbl (val INT);
INSERT INTO tbl SELECT generate_series(1,5);
CREATE FUNCTION example_func(n INT) RETURNS INT STABLE AS
$$
SELECT val FROM tbl WHERE val < n;
$$ LANGUAGE SQL;
The UDF example_func has a number of attributes that are parsed and validated when the function is created:
Return type: specified after the
RETURNSkeyword, must match the type that the function body returns.Volatility: this can be
IMMUTABLE,STABLE, orVOLATILE(default), and is also validated against the statement body. Inexample_func, we use theSTABLEvolatility option since the function body references the relationtblbut does not modify any data. If unspecified, functions have a default volatility ofVOLATILE, but this limits some of the optimizations that can be done on the function, so we recommend using the appropriate volatility.Language: currently SQL and PL/pgSQL are supported.
Null input behavior:
STRICTorCALLED ON NULL INPUT(default). By default, functions are executed if input parameters areNULL. IfSTRICTis specified, the function is not executed.
When creating the function, CockroachDB also fully qualifies datasource names to avoid ambiguity with other namespaces. You can see the fully-qualified function with a complete list of attributes, including default values, by using the SHOW CREATE FUNCTION command:
SHOW CREATE FUNCTION example_func;
function_name | create_statement
----------------+---------------------------------------------------------
example_func | CREATE FUNCTION public.example_func(IN n INT8)
| RETURNS INT8
| STABLE
| NOT LEAKPROOF
| CALLED ON NULL INPUT
| LANGUAGE SQL
| AS $$
| SELECT val FROM defaultdb.public.tbl WHERE val < n;
| $$
Once validated, CockroachDB adds an overload for the function/procedure to the schema descriptor, using the name, argument types, and return types to distinguish the function. The body of SQL statements is stored in a schema object, which is cached locally on every node in the cluster for fast access.
When a query calls a UDF or SP, it is rebuilt and re-optimized. Internally, UDFs and SPs are implemented as routines. Routines are a “plan within a plan”. They encapsulate multiple SQL statements and execute them sequentially. In volatile routines, CockroachDB injects transaction sequence points so that if the body has multiple statements, each statement can see the previous statements’ mutations. Routines also allow us to evaluate input parameters before evaluating any statements, in case of STRICT behavior.
There is some overhead to set up routines for execution. In the next section, we’ll explore how we can use inlining in order to remove the routines so we don’t incur this overhead.
Multiple Updates to a Single Table in UDFs
In CockroachDB versions 23.1 and prior, there was a limitation on mutating the same table multiple times in the same statement in order to avoid potential index corruption — a write at the end of the statement may not see earlier writes in the statement. However, this was too restrictive for use cases involving UDFs, since, as mentioned previously, volatile routines have transaction sequence points that allow stepping through the statements in a way that allows each statement to see previous writes. Take the following example:
CREATE FUNCTION ups(a INT, b INT) RETURNS VOID AS $$
UPSERT INTO tbl VALUES (a);
UPSERT INTO tbl VALUES (b);
$$ LANGUAGE SQL;
SELECT ups(1,2), ups(1,1);
Under the old restrictions, the SELECT statement would not have been allowed since tbl is updated in the same statement. To work around this, we track updates in a statement tree and disallow mutations on the same table for ancestors/descendants, but allow them for sibling statements. The example above would generate a tree that looks something like:
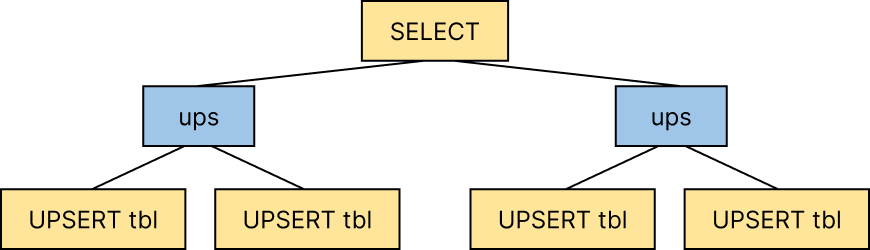
The top-level statement only performs a SELECT, calling the ups(1,2) and ups(1,1) functions, which are sibling statements. The ups(1,2) function in turn calls UPSERT INTO tbl VALUES (1) and UPSERT INTO tbl VALUES (2) which mutate tbl. The UPSERTs are siblings, and therefore are safe mutations. The ups(1,1) function makes two child calls of UPSERT INTO tbl VALUES (1). These are not only at the same level of the tree as each other, but also at the same level as ups(1,2)’s child UPSERTs. All mutations to tbl are at the same level of the tree and not ancestors/descendants of one-another, so the SELECT statement is safe to execute without risking index corruption.
Because of this calculation, we can perform the query:
TRUNCATE TABLE tbl;
SELECT ups(1,2), ups(1,1);
ups | ups
-------+-------
NULL | NULL
SELECT * FROM tbl;
val
-------
1
2
1
1
On the other hand, a query such as:
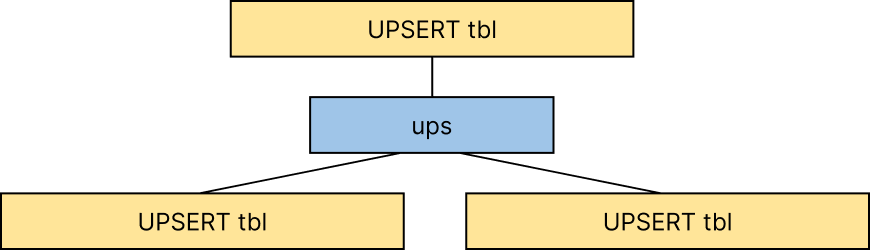
UPSERT INTO tbl VALUES (ups(1,2));
Is not allowed, since the top-level UPSERT on tbl may not be visible to the UPSERTs in the ups function:
Background: SQL vs. PL/pgSQL
SQL is a declarative language. Users specify a desired result through a SQL query, and it’s up to the database to decide how to produce that result. For example, a query that joins two tables could use a hash join or a merge join algorithm. Relation X could be the left input of the join, or it could be the right input. Within a SQL statement, operations may be reordered, duplicated, or pruned away entirely, depending on the optimizer’s ability and cost model.
-- Neither join ordering nor join algorithm is specified below.
SELECT * FROM xy JOIN ab ON x = a;
PL/pgSQL, on the other hand, is a procedural language. The user specifies a series of operations that cannot be reordered, duplicated, or removed by the optimizer. PL/pgSQL routines also carry state in the form of variables, which can be arbitrarily modified and read as long as they are in scope. In particular, a variable assignment (for a predefined variable) in an “inner” scope is still visible after control returns to the “outer” scope:
CREATE FUNCTION f(n INT) RETURNS INT AS $$
DECLARE
i INT := 0;
BEGIN
LOOP
IF i >= n THEN
EXIT;
END IF;
i := i + 1;
END LOOP;
RETURN i;
END
$$ LANGUAGE PLpgSQL;
SELECT f(10);
f
------
10
(1 row)
This behavior is familiar for programmers who have worked with languages like C++ or Go, but integrating it into a declarative SQL execution engine is non-trivial. The following section will provide some details about how CockroachDB solves this problem.
Implementing PL/pgSQL in a SQL Execution Engine
Postgres implements PL/pgSQL via an interpreter, which traverses an instruction tree that was generated from the PL/pgSQL source code. The interpreter calls into the SQL engine to evaluate SQL expressions and statements, with a fast path for simple expressions. By contrast, CockroachDB compiles PL/pgSQL source code directly into expressions that are recognized by the SQL optimizer. This allows various pre-existing optimizations to apply to PL/pgSQL routines, and avoids the need to implement an interpreter. This section will explore how this is accomplished.
PL/pgSQL has various control-flow statements that allow branching: basic/WHILE/FOR loops, IF/ELSE statements, EXIT/CONTINUE etc. When CockroachDB reaches a branching statement in the parsed PL/pgSQL statements, it produces an internal "continuation” routine for each branch. A continuation takes in the current state (variables) as parameters, and produces the side effects and return value that follow from executing that branch. Crucially, any branching within the continuation is simply handled by calling more continuations. For an example, take the function from earlier:
CREATE FUNCTION f(n INT) RETURNS INT AS $$
DECLARE
i INT := 0;
BEGIN
LOOP
IF i >= n THEN
EXIT;
END IF;
i := i + 1;
END LOOP;
RETURN i;
END
$$ LANGUAGE PLpgSQL;
CockroachDB will compile the variable declaration as a column projecting the value 0 and call into the continuation for the LOOP. Conceptually, it is similar to the UDF defined as:
CREATE FUNCTION f_internal(n INT) RETURNS INT AS $$
SELECT loop_body(n, i) FROM (SELECT 0 AS i);
$$ LANGUAGE SQL;
Note: the variable declaration and assignment is propagated to later stages of execution via the i parameter of each continuation.
When CockroachDB compiles the LOOP statement, it will produce two continuations: one for the loop body, and one for the statements to be executed when the loop exits.
CREATE FUNCTION loop_body(n INT, i INT) RETURNS INT AS $$
SELECT CASE WHEN i >= n THEN then_branch(n, i) ELSE else_branch(n, i) END;
$$ LANGUAGE SQL;
CREATE FUNCTION loop_exit(n INT, i INT) RETURNS INT AS $$
SELECT i;
$$ LANGUAGE SQL;
Note: loop_body holds the conditional logic of the IF statement, and calls into its continuations.
Note: loop_exit doesn’t call another continuation. This is because it handles the RETURN statement that follows the loop. RETURN statements don’t branch; they simply evaluate their expression and return it.
The IF statement inside the loop will also produce two continuations that are called from the loop body: one for the THEN branch, and one for the ELSE branch.
CREATE FUNCTION then_branch(n INT, i INT) RETURNS INT AS $$
SELECT loop_exit(n, i);
$$ LANGUAGE SQL;
CREATE FUNCTION else_branch(n INT, i INT) RETURNS INT AS $$
SELECT loop_body(n, i) FROM (SELECT i + 1 AS i);
$$ LANGUAGE SQL;
Note: the else_branch function is responsible for incrementing i, and it propagates that change by passing the updated value to loop_body.
The resulting set of tail-recursive functions captures the control flow of the original PL/pgSQL code. At this point, the optimizer is free to inline and apply other optimizations, so that the final result, expressed as UDFs, would look more like this:
CREATE FUNCTION f_internal(n INT) RETURNS INT AS $$
SELECT loop_body(n, 0);
$$ LANGUAGE SQL;
CREATE FUNCTION loop_body(n INT, i INT) RETURNS INT AS $$
SELECT CASE WHEN i >= n THEN i ELSE loop_body(n, i+1) END;
$$ LANGUAGE SQL;
Note: CRDB does not currently support recursive UDF definitions; only the recursive execution used to implement PL/pgSQL loops.
Side effects are implemented through internal builtin function calls whenever possible. For example, RAISE statements compile to crdb_internal.plpgsql_raise() calls, and FETCH statements likewise compile to crdb_internal.plpgsql_fetch(). Ex:
CREATE FUNCTION f_raise() RETURNS INT AS $$
BEGIN
RAISE NOTICE ‘foo’;
RETURN 0;
END
$$ LANGUAGE PLpgSQL;
=>
CREATE FUNCTION f_raise_internal() RETURNS INT AS $$
SELECT crdb_internal.plpgsql_raise(..., ‘foo’, …);
SELECT 0;
$$ LANGUAGE SQL;
It is important to ensure that side effects happen in the order they were written in the original PL/pgSQL code. CockroachDB guarantees this by encoding the side-effect ordering in the structure of the continuation call graph: if side effect B must occur after side effect A, the routine body statement that produces side effect B is ordered after the statement for side effect A. When a continuation contains a side-effecting expression, CockroachDB marks the continuation as non-inlinable so that optimizations do not interfere with correct ordering.
Inspiration
This design was largely based off of a 2021 SIGMOD paper titled “One WITH RECURSIVE is Worth Many GOTOs”. CockroachDB doesn’t compile PL/pgSQL code all the way into recursive CTE expressions, but it does use “administrative normal form” (tail-recursive functions), which is the preceding step from the paper.
Hirn, Denis, and Torsten Grust. “One WITH RECURSIVE is Worth Many GOTOs.” Sigmod ’21: Proceedings of the 2021 International Conference on Management of Data, 9 June 2021, https://doi.org/10.1145/3448016.3457272.
Future Work
As we continue to support more PL/pgSQL capabilities, our goal is to eventually achieve full compatibility with Postgres. With this goal in mind, we prioritize releasing features that help unblock migrating our customers’ existing code logic with minimum code changes required. Below are several key capabilities recently released in CockroachDB version 24.1.
Support
OUTparameters for UDFs and SPsSupport invoking UDFs/SPs from other UDFs/SPs
Support explicit transactions inside SPs
In the near future, besides providing additional capabilities to continue increasing compatibility between CockroachDB and Postgres, we also plan to invest in optimizing efficiency such as enabling more sophisticated inlining to leverage CockroachDB’s innovative distributed query execution.


