
CockroachDB is a Distributed SQL database. That means for the person doing the querying, everything looks like the SQL they’ve known for years. But under the hood, there’s a lot more going on. In order to achieve the bulletproof resiliency and elastic scalability CockroachDB delivers, data is replicated and geographically distributed across nodes of a cluster, and read and write requests are automatically routed between nodes as appropriate. Replication and geo-distribution mean that your nodes have a shape--a topology--and how you design that topology allows you to make important tradeoffs regarding latency and resilience.
In a recent episode of The Cockroach Hour, database experts Tim Veil and Jim Walker met with Jesse Seldess, VP of Education at Cockroach Labs, to walk through why topology patterns matter in CockroachDB, and how to select the one that works best for your use case.
Unlike with many other database platforms, you’re offered a lot of choice with CockroachDB. Do you want to optimize for low latency? Or do you want to optimize for resilience? It's important to review and choose the topology patterns that best meet your latency and resiliency requirements. In this recap of The Cockroach Hour, we’ll cover common topology patterns in CockroachDB, what the default topology pattern is, and how to choose the right one.
What’s a Data Topology Pattern?
Data topology patterns map the shape of your cluster. Are you deployed in a single region across multiple availability zones? Are you deployed across multiple regions? And where is data located across that cluster, across those nodes? Since CockroachDB can control data locality at the database, table, and even row level, you have a lot of options here, depending on how you want your database to perform.
Topology patterns are especially crucial for multi-region deployments. In a single-region cluster, this behavior doesn't affect performance because network latency between nodes is sub-millisecond. But in a cluster spread across multiple geographic regions, the distribution of data can become a key performance bottleneck. For that reason, it’s important to think about the latency requirements of each table and then use the appropriate data topologies to locate data for optimal performance.
When you're ready to run CockroachDB in production in a single region, it's important to deploy at least 3 CockroachDB nodes to take advantage of CockroachDB's automatic replication, distribution, rebalancing, and resiliency capabilities. Here’s what that might look like in a single-region deployment:
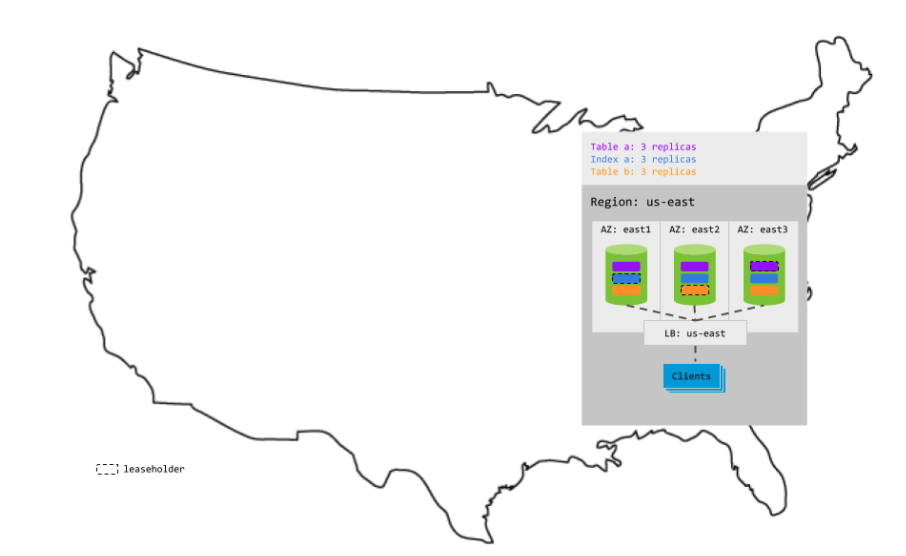
Because each range is balanced across availability zones (AZs), one AZ can fail without interrupting access to any data. However, if an additional AZ fails at the same time, the ranges that lose consensus become unavailable for reads and writes. This is where multi-region topologies can help.
Each multi-region topology assumes the below setup:
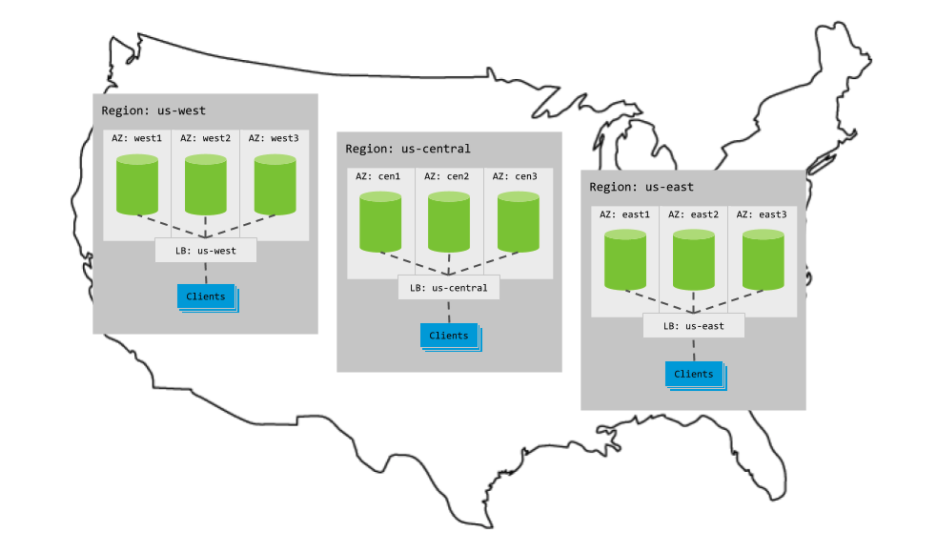
But they’re very customizable from here. Because, as mentioned, CockroachDB can control data location at the database, table, and row level, we have a lot of choice regarding multi-region topologies.
How to Choose a Multi-Region Topology Pattern
In the database topology webinar, CockroachDB expert Tim Veil says there are two questions he asks every customer he works with, when setting up topology patterns:
Latency: How quickly do you want to access the data?
Resilience: What do you want to survive?
Cockroach is a Distributed SQL database. When we say distributed, what we mean is that the database can span a wide physical geography. It can span multiple what we call failure domains, or things that can fail. This is an incredibly important value proposition. And so one of the questions that we have that we can ask that others can't is, when you're building this database topology, when you're building a solution based on Cockroach, is:
What do you want your database to survive? Survival, for CockroachDB, isn't some meager existence. Survival means, what do you want to happen to your database and continue to serve reads and writes without interruption? That's survival, that's real survival for us.
So with that in mind, what are the different ways you can configure Cockroach so that you can continue to serve reads and writes even or while significant failures are occurring, either planned or unplanned? All of our topology patterns are available on our docs, or you can watch the full webinar. In the rest of this blog, we'll dive into three common topology patterns.
Topology Pattern #1: Follow the Workload (Default Pattern)
When there’s high latency between nodes (for example, cross-datacenter deployments), CockroachDB uses locality to move range leases closer to the current workload. This is known as the "follow-the-workload" pattern, and it reduces network round trips and improves read performance.
What can Follow the Workload Patterns Survive?
Because this pattern balances the replicas for the table across regions, one entire region can fail without interrupting access to the table:

Follow-the-workload is the default pattern for tables that use no other pattern. In general, this default pattern is a good choice only for tables with the following requirements:
The table is active mostly in one region at a time, e.g., following the sun.
In the active region, read latency must be low, but write latency can be higher.
In non-active regions, both read and write latency can be higher.
Table data must remain available during a region failure.
Topology Pattern #2: Geo-Partitioned Replicas
Using this pattern, you design your table schema to allow for partitioning, with a column identifying geography as the first column in the table's compound primary key (e.g., city/id). You tell CockroachDB to partition the table and all of its secondary indexes by that geography column, each partition becoming its own range of 3 replicas. You then tell CockroachDB to pin each partition (all of its replicas) to the relevant region (e.g., LA partitions in us-west, NY partitions in us-east). This means that reads and writes in each region will always have access to the relevant replicas and, therefore, will have low, intra-region latencies.
What can Geo-Partitioned Replica Topology Patterns Survive?
This pattern optimizes for low latency over resilience. Because each partition is constrained to the relevant region and balanced across the 3 AZs in the region, one AZ can fail per region without interrupting access to the partitions in that region:
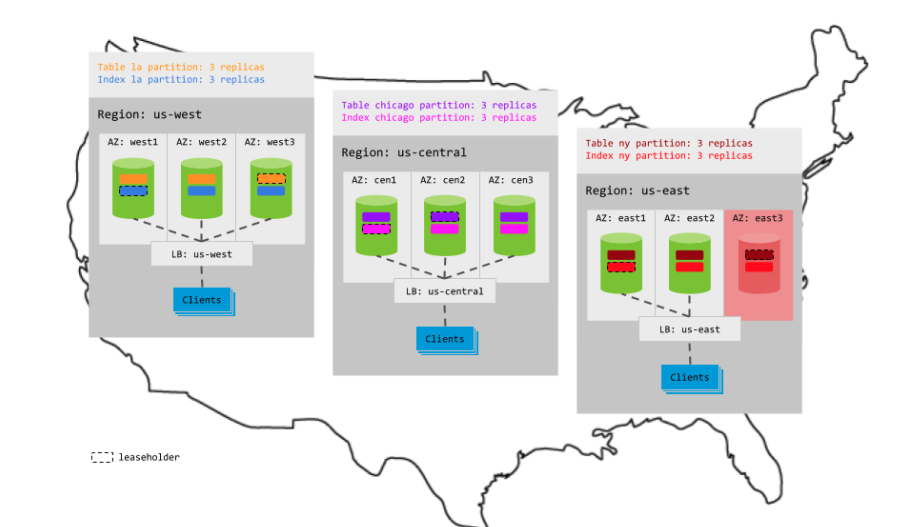
However, if an entire region fails, the partitions in that region become unavailable for reads and writes, even if your load balancer can redirect requests to a different region:
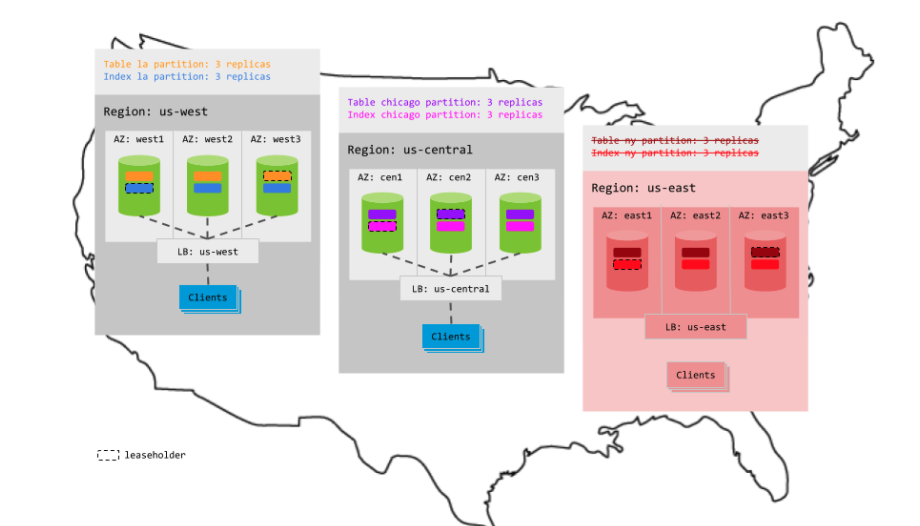
The geo-partitioned replicas topology is a good choice for tables with the following requirements:
Read and write latency must be low.
Rows in the table, and all latency-sensitive queries, can be tied to specific geographies, e.g., city, state, region.
Regional data must remain available during an AZ failure, but it's OK for regional data to become unavailable during a region-wide failure.
See it in action: Read about how an electronic lock manufacturer and multi-national bank are using the Geo-Partitioned Replicas topology in production for improved performance and regulatory compliance.
Topology Pattern #3: Geo-Partitioned Leaseholders
Using this pattern, you design your table schema to allow for partitioning, with a column identifying geography as the first column in the table's compound primary key (e.g., city/id). You tell CockroachDB to partition the table and all of its secondary indexes by that geography column, each partition becoming its own range of 3 replicas. You then tell CockroachDB to put the leaseholder for each partition in the relevant region (e.g., LA partitions in us-west, NY partitions in us-east). The other replicas of a partition remain balanced across the other regions. This means that reads in each region will access local leaseholders and, therefore, will have low, intra-region latencies. Writes, however, will leave the region to get consensus and, therefore, will have higher, cross-region latencies.
What Can Geo-Partitioned Leaseholder Patterns Fail?
Because this pattern balances the replicas for each partition across regions, one entire region can fail without interrupting access to any partitions. In this case, if any range loses its leaseholder in the region-wide outage, CockroachDB makes one of the range's other replicas the leaseholder:

See it in action: Read about how a large telecom provider with millions of customers across the United States is using the Geo-Partitioned Leaseholders topology in production for strong resiliency and performance.
Additional Resources and Next Steps
You can learn more about different topology patterns (like duplicate indexes) in the webinar, or in our docs. For a production checklist and suggested next steps, here’s what Tim tells all CockroachDB customers when selecting a topology pattern:
Review how data is replicated and distributed across a cluster, and how this affects performance. It is especially important to understand the concept of the "leaseholder". For a summary, see Reads and Writes in CockroachDB. For a deeper dive, see the CockroachDB Architecture documentation.
Review the concept of locality, which makes CockroachDB aware of the location of nodes and able to intelligently place and balance data based on how you define replication controls.
Review the recommendations and requirements in our Production Checklist.
These high-level topology overviews don't account for hardware specifications, so be sure to follow our hardware recommendations and perform a POC to size hardware for your use case.
Adopt relevant SQL Best Practices to ensure optimal performance.
Want to learn about all our topology patterns? Watch the webinar -->

![[image] finserv use cases](/_next/image/?url=https%3A%2F%2Fimages.ctfassets.net%2F00voh0j35590%2F61herWHcBa8OEwzsV20Vco%2F5971df8ab1da34f54d551ca1383e10ba%2FFinserv_use_cases_Blog_1920x1080__1_.png&w=3840&q=75)
