

Familiar, easy to use PostgreSQL interface.
That’s what a recent customer said when asked why they purchased CockroachDB.
When considering the PostgreSQL interface, the common language for describing compatibility is “PostgreSQL compatible.” There are other terms floating around out there, but ultimately it comes down to how you define compatibility and what features matter to you when considering compatibility. The focus on PostgreSQL compatibility is overblown because everyone’s specific needs are different.
CockroachDB delivers a highly compatible PostgreSQL interface that our customers rely on. We’ve re-written the SQL layer for a distributed SQL implementation in order to deliver the best performance, resilience, and technical support possible.
But before getting into too many details, let’s take a step back.
Why build a PostgreSQL compatible database?

Why do we care about compatibility at all?
We care about PostgreSQL compatibility because, if you find that our feature offerings are valuable to you and your organization, and you want to entrust us with your data, we want to make it easier for you to port your applications to CockroachDB. To achieve that goal, we need PostgreSQL compatibility. Full stop.
Firstly however, vendors attempting to achieve PostgreSQL compatibility are, in one way or another, more or less compatible. Said differently, no one (other than PostgreSQL) is 100% compatible. The result is that measuring compatibility is not a binary choice (yes vs. no); it’s contextual. Compatibility depends on your circumstances as much as on the product itself.
You need to decide which specific PostgreSQL features are most important to you and understand if they’re supported. For example, if you need GiST indexing or multicolumn GIN indices, CockroachDB supports both while other distributed SQL databases fall short.
Secondly, when determining compatibility it’s easy to get caught up and measure compatibility as it stands today. But measuring a moment in time is insufficient. You want some sort of understanding as to how, across the arc of future-time, compatibility will be not only maintained, but also enhanced.
PostgreSQL compatibility architectures: To fork or rewrite
As we all know, PostgreSQL is open source, and so developers looking to build a new database with PostgreSQL compatibility in mind had options. It’s a tale of two approaches to turn PostgreSQL into a distributed SQL database solution: forking PostgreSQL or rewriting the SQL layer in a compatible way.
This has resulted in a common talking point:
If a vendor forks PostgreSQL are they inherently more PostgreSQL compatible?
TLDR; No.
Both approaches require writing code…the question is where do you write it?
We’ve re-written from scratch the PostgreSQL layer to maximize compatibility and performance of code when the underlying database is distributed SQL. Others have forked the PostgreSQL libraries and decided to write the code at the layer between the forked code and the storage layer in order to map legacy SQL to their distributed SQL implementation.
Loosely speaking, we can draw the application to database communications as follows:
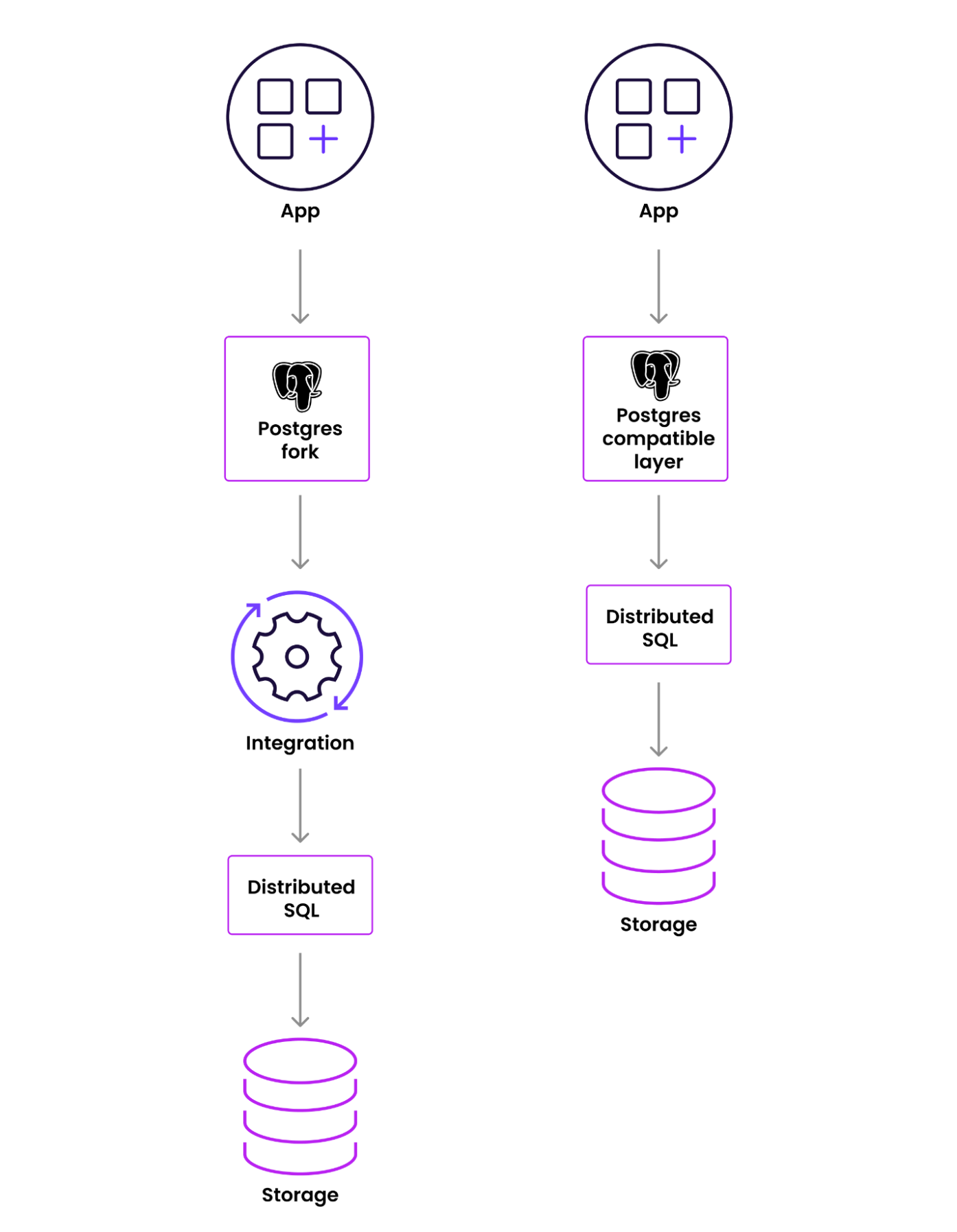
On the surface, it might seem that forking PostgreSQL would make it easier, but in fact that’s not the case.
Forking eliminates the requirement to rewrite the SQL interface, but the SQL layer still needs to be integrated with the distributed SQL layer. And it turns out, that’s a lot of work.
As a customer evaluating PostgreSQL compatibility you need to check core compatibility with commands like GENERATE ALWAYS AS STORED and ALTER TYPE that we support but others don’t. Then you need to check the over 200 PostgreSQL extensions for support and compatibility. Finally, you need to check which version of PostgreSQL the vendor is on since forking the code locks you to a release until the vendor decides to update.
Plus, what happens if the vendor is locked into a release that is no longer supported by PostgreSQL once it becomes too outdated?
We had to write a little more code than they did to create the PostgreSQL interface, but we own the stack. Owning the whole stack enables us to make performance and compatibility improvements where they make sense based on customer demand. And, we’re able to optimize SQL performance continuously with more ownership of the end-to-end experience between the traditional SQL interface and distributed SQL infrastructure.
Owning the stack
In general, owning the whole stack gives us three technical advantages that are rooted deep in the product architecture (meaning, they’re not so easy to overcome once you head down a specific architectural path):
Cockroach Labs has inherently less technical debt than a company forking PostgreSQL
CockroachDB can deliver better distributed-SQL performance
Cockroach Labs can optimize for customer experience
Less technical debt
Owning the stack keeps our technical debt low because we’re not integrating someone else’s code into our solution. And, that gives us more time to work on the features our customers and prospects are demanding.
For example, were we to have forked PostgreSQL at a specific version, and then made changes to it…all of those changes need to be ported over to a later version when updating the PostgreSQL libraries. Because we haven’t forked any code, the PostgreSQL compatibility is native to our implementation and can evolve without “forward porting” any changes we’ve made to earlier PostgreSQL versions.
Another consideration when forking PostgreSQL is support. If the version you’ve forked is old, it might no longer be supported adding further burden to the engineering team who are required to support it.
We continue to introduce distributed SQL and cloud optimizations regularly, such as WAL failover and our cost based optimizer, because of our lack of technical debt.
Better distributed-SQL performance
It makes sense that if you’re taking an old interface and wrapping it around something new the old interface is going to limit how the new stuff gets exposed. You can improve the code you forked, but that just adds to the technical debt when trying to update to recent versions of PostgreSQL.
The fundamental solution we’re trying to provide is a flavor of distributed SQL that improves on the performance and scalability problems native to legacy SQL while also keeping a familiar, easy to use SQL interface.
Specifically, we want to improve resilience in the face of node failures or network partitions while keeping a familiar SQL interface, and we believe we’ve done that better than anyone else. Reach out if you’d like specific benchmarks we’ve produced.
Optimized for your experience
We understand that your experience doesn’t end with performance improvements like the cost-based optimizer and WAL failover. Your experience is about the whole product, and in the case of databases, that includes migrations.
Database migrations are notoriously difficult and error-prone, often resulting in delays or downtime. But, database migrations are where “it all starts.” New applications start with a fresh database, but companies moving to distributed SQL to solve existing application problems are going to have to experience a migration.
Our migration tools, fondly named MOLT (Migrate Off Legacy Technology) tools, are mature, fast, and, importantly, consistent. We have three tools, each addressing different areas of migrations:
MOLT Schema Conversion Tool:. A GUI used to convert a schema from a PostgreSQL, MySQL, Oracle, or Microsoft SQL Server database for use with CockroachDB.
MOLT Fetch: Moves data from a source database into CockroachDB as part of a database migration, supports an initial load test, and continuous data replication.
MOLT Verify: Checks for data discrepancies between a source database and CockroachDB during a database migration.
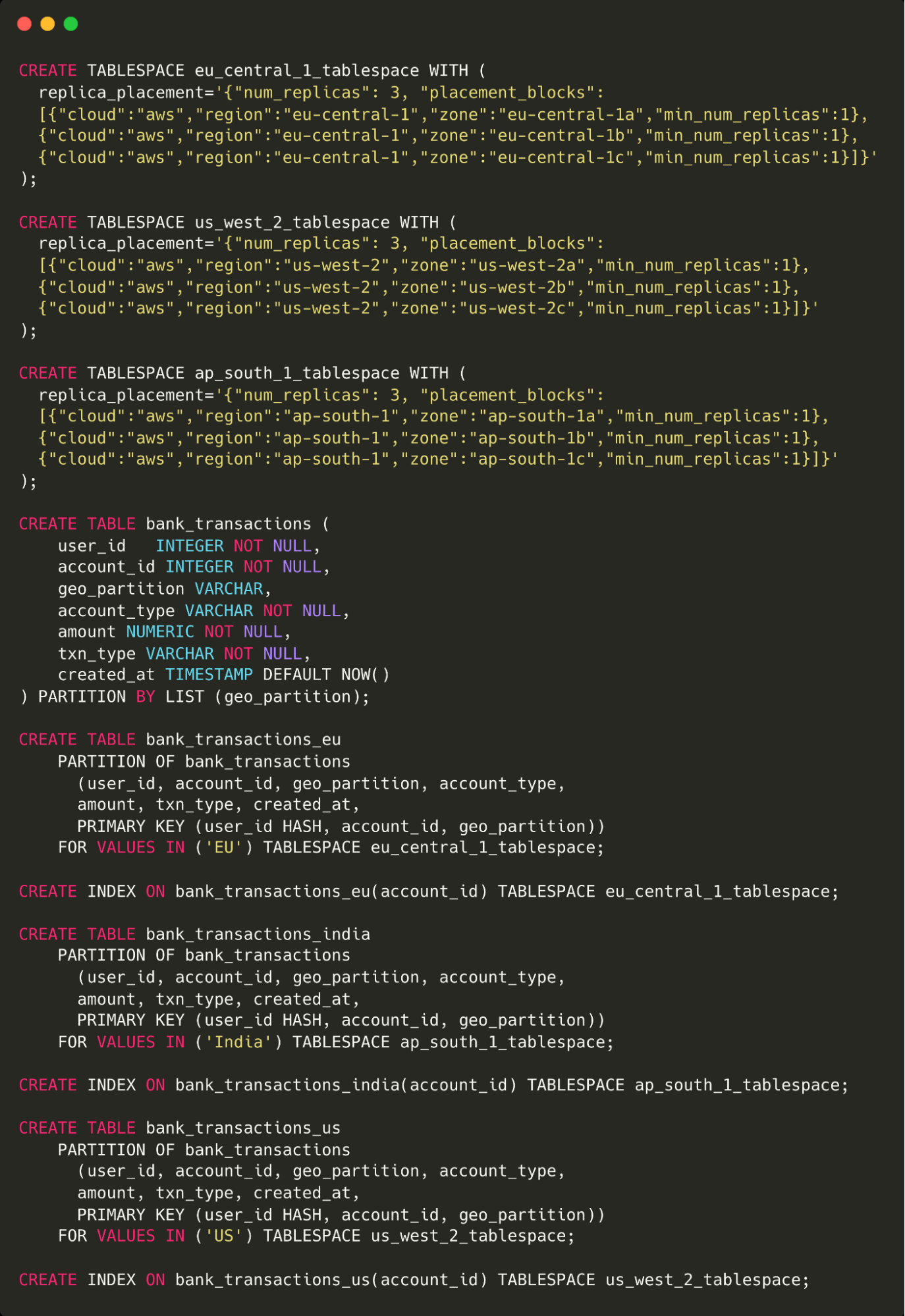
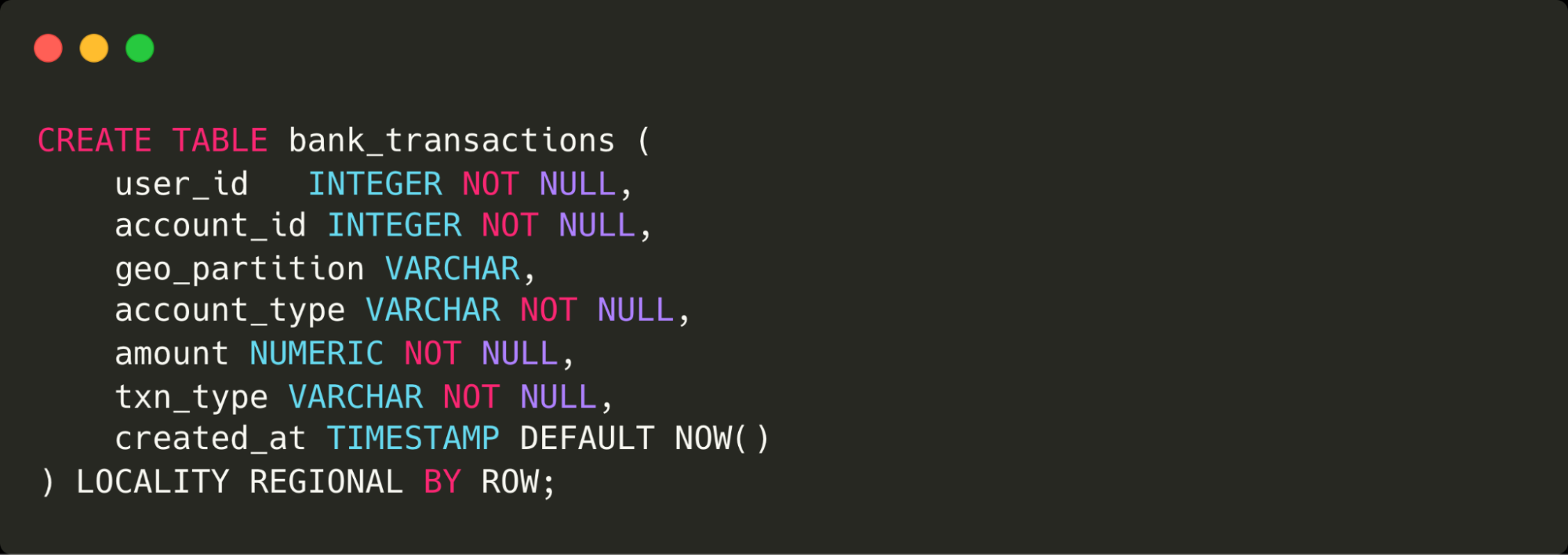
Finally, we’ve dramatically simplified how to set up geo-partitioning for data locality applications. What takes others almost 60 lines of code to do, in regards to configuring tablespaces, replica placements, and table partitioning, we can do in just 9 lines of SQL.
Here’s what it looks like using other solutions:
Here are the 9 lines of SQL needed in CockroachDB to get the same result:
Better performance with a better experience
We’re delivering better performance with a better customer experience, all while continuing to move at the speed of success because we own our whole technology stack. As an organization, we deeply understand the changes demanded and can make them at the layer of the implementation (the SQL layer, the distributed SQL layer, or the storage layer) that makes the most sense.
Compatibility matters, it matters in relationships as well as databases, but like relationships, compatibility is subjective and being 100% compatible is impossible. So when you're looking at a PostgreSQL compatible database make sure you get the features you need for your applications and migrations – without sacrificing the resilience your application demands.
To learn more about how CockroachDB compares with alternative PostgreSQL-compatible databases, visit our documentation.



