

There are occasions in which businesses need their database to fit into unusual production environments for specific use cases. In this blog, we’ll push the boundaries and test whether CockroachDB can work and thrive in new and unusual places, such as:
• On an IBM Mainframe • On an ARM64 CPU
Most of you are probably familiar with the ARM CPUs in phones and even now Apple Macs, but ARM CPU’s are a new thing that a number of cloud providers are now offering.
The IBM CPU, which goes by a number of marketing names such as the S/390X or the z/Architecture, traces its lineage back to the IBM System/360 Mainframe computers. All the way back to the 1960’s. We will be using the 64-Bit version of the S/390, the S/390X, which is the default standard CPU to be used on an IBM Mainframe nowadays.
The plan here is to build a twelve node CockroachDB cluster, with three regions. In each region we are going to use a different CPU architecture, a different cloud provider, and a different variation of the Linux operating system. We will hook them all together with some interesting network glue and make all twelve machines act as a single database. This sort of design is an extreme case of what you could do, but not necessarily what you should do for your production deployments. For a typical production environment, we would want a more homogeneous cluster to avoid possible complexities or oddities in performance or operation, but in this case we are going to demonstrate that it will all still work.
We’re also not pushing for performance, more so for interoperability. An example use case for this sort of configuration might be for data migration or data pipeline processing. For example, we might generate the data on an IBM Mainframe, but then want to start moving those records into a data processing stream.
We will need to compile CockroachDB from source to get the ARM64 and S/390X binaries.
The easiest way to do a build is to pull the source code for CockroachDB from Github. Execute a “./dev doctor” to test our ability to do a build. Next, make sure we have Docker installed for the build process. Then execute the build:
Intel/AMD64 Build:
./build/builder.sh mkrelease linux-gnu
[cockroach@crdb1 ~]$ cockroach version
Build Tag: v22.1.4
Build Time: 2022/07/21 18:06:04
Distribution: CCL
Platform: linux amd64 (x86_64-unknown-linux-gnu)
Go Version: go1.17.11
C Compiler: gcc 6.5.0
Build Commit ID: 3c6c8933f578a7fd140e24a603d6ec64c6b7a834
Build Type: release
[cockroach@crdb1 ~]$ more /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 15
model : 6
model name : Common KVM processor
stepping : 1
microcode : 0x1
cpu MHz : 4007.996
cache size : 16384 KB
physical id : 0
siblings : 4
core id : 0
cpu cores : 4
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx lm constant_tsc nopl xtopology cpu
id tsc_known_freq pni cx16 x2apic hypervisor lahf_lm cpuid_fault pti
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs itlb_multihit
bogomips : 8015.99
clflush size : 64
cache_alignment : 128
address sizes : 40 bits physical, 48 bits virtual
power management:
IBM S/390X ZLinux Build:
./build/builder.sh mkrelease s390x-linux-gnu
cockroach@ibm-crdb1:~$ cockroach version
Build Tag: v22.1.4
Build Time: 2022/07/21 17:24:18
Distribution: CCL
Platform: linux s390x (s390x-ibm-linux-gnu)
Go Version: go1.17.11
C Compiler: gcc 6.5.0
Build Commit ID: 3c6c8933f578a7fd140e24a603d6ec64c6b7a834
Build Type: release
cockroach@ibm-crdb1:~$ more /proc/cpuinfo
vendor_id : IBM/S390
# processors : 4
bogomips per cpu: 1167.00
max thread id : 0
features : esan3 zarch stfle msa ldisp eimm dfp edat etf3eh highgprs te vx vxd vxe gs vxe2 vxp sort dflt sie
facilities : 0 1 2 3 4 6 7 8 9 10 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 30 31 32 33 34 35 36 37 38 40 41 42 43 44 45 47 48 49 50 51 52 53 54 57 58
59 60 61 64 65 69 71 73 74 75 76 77 78 80 81 82 129 130 131 133 134 135 138 139 146 147 148 150 151 152 155 156 161
cache0 : level=1 type=Data scope=Private size=128K line_size=256 associativity=8
cache1 : level=1 type=Instruction scope=Private size=128K line_size=256 associativity=8
cache2 : level=2 type=Data scope=Private size=4096K line_size=256 associativity=8
cache3 : level=2 type=Instruction scope=Private size=4096K line_size=256 associativity=8
cache4 : level=3 type=Unified scope=Shared size=262144K line_size=256 associativity=32
cache5 : level=4 type=Unified scope=Shared size=983040K line_size=256 associativity=60
processor 0: version = FF, identification = 04AB38, machine = 8562
processor 1: version = FF, identification = 04AB38, machine = 8562
processor 2: version = FF, identification = 04AB38, machine = 8562
processor 3: version = FF, identification = 04AB38, machine = 8562
ARM64 Build:
./build/builder.sh mkrelease arm64-linux-gnu
[cockroach@oc-crdb1 ~]$ cockroach version
Build Tag: v22.1.4
Build Time: 2022/07/21 18:46:47
Distribution: CCL
Platform: linux arm64 (aarch64-unknown-linux-gnu)
Go Version: go1.17.11
C Compiler: gcc 6.5.0
Build Commit ID: 3c6c8933f578a7fd140e24a603d6ec64c6b7a834
Build Type: release
[cockroach@oc-crdb1 ~]$ more /proc/cpuinfo
processor : 0
BogoMIPS : 50.00
Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop asimddp ssbs
CPU implementer : 0x41
CPU architecture: 8
CPU variant : 0x3
CPU part : 0xd0c
CPU revision : 1
12 node CockroachDB cluster
To start building our cluster we first need a platform. We will start in the basement lab, initially with the Intel nodes. We will run these four instances on an open source virtualization platform called Proxmox. Proxmox gives us a number of nice features and a nice price for doing testing. We will stand up virtual machines with four Intel cores and 16GB of assigned RAM on four different physical Proxmox nodes. Hooked together with a 1Gbps Ethernet switch and local SSD storage for each Proxmox server for the VMs. The operating system in the home lab is Centos 8.
The location of the home lab is in the Midwest and the WAN is not too slow, but not that fast on the uplink, which is probably going to impact performance between the regions.
For the IBM z/Architecture machines, we will be using IBM Cloud. IBM hosts Linux z/Architecture S390X on an IBM LinuxOne platform. From the IBM Cloud console we will launch four z/Architecture machines, each with four CPUs (sometimes called engines in the mainframe world) and 16GB of RAM. For these machines we will be running Ubuntu Linux 22.04. (As a side note, we had to start with Ubuntu 18.04 and upgrade twice to 20.04 and then to 22.04.)
Next, we will set up four ARM64 virtual machines in Oracle Cloud. Again each virtual machine will have four CPUs and 16GB of RAM. The ARM64 CPUs are made by Ampere Computing.
To glue all of these nodes together, we will be using a virtual software-defined network from Zerotier.
Zerotier gives us a pretty simple to setup, secure and flat network between all of the nodes. It will look like they are all on the same LAN. While intra-node communication is usually configured to be encrypted in CockroachDB (as it is in this test), we will also get encrypted transport with Zerotier. We will also get NAT traversal, which we will need for our home lab systems. Once Zerotier is up and running, all of the nodes see each other on a virtual Ethernet interface.
Joining all twelve nodes together, we get a CockroachDB cluster looking like this in the CockroachDB console (image split in half for clarity):


The latency map between nodes also looks good:

Benchmark testing
Next, we set up a load balancer in IBM Cloud and run some benchmark tests. To run the tests, we will start up a X86 VM in IBM Cloud, just to run the benchmarks against the load balancer. If we were testing for a performance level, more sizing and optimization of the storage, network, CPU and memory would be required. In our case, we’re just testing to see if everything works adequately well.
root@crdb-test:~# date; ./cockroach workload run bank --duration=10m 'postgresql://root@crdb.uniblab.xyz:26257?sslcert=certs%2F/client.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt'
Sun Aug 14 19:57:58 UTC 2022
I220814 19:57:58.574983 1 workload/cli/run.go:414 [-] 1 creating load generator...
I220814 19:57:58.591594 1 workload/cli/run.go:445 [-] 2 creating load generator... done (took 16.611008ms)
_elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)
1.0s 0 252.7 256.9 14.7 24.1 32.5 92.3 transfer
2.0s 0 256.1 256.5 14.7 26.2 30.4 39.8 transfer
3.0s 0 265.8 259.6 14.7 22.0 31.5 50.3 transfer
4.0s 0 268.1 261.7 14.7 23.1 31.5 35.7 transfer
5.0s 0 265.8 262.6 15.2 21.0 26.2 31.5 transfer
6.0s 0 271.2 264.0 14.7 22.0 25.2 29.4 transfer
7.0s 0 268.8 264.7 14.2 22.0 27.3 35.7 transfer
8.0s 0 270.1 265.4 14.2 22.0 29.4 33.6 transfer
9.0s 0 263.0 265.1 15.2 22.0 25.2 33.6 transfer
10.0s 0 280.9 266.7 14.2 21.0 25.2 27.3 transfer
….
593.0s 0 281.9 273.4 14.2 21.0 24.1 30.4 transfer
594.0s 0 297.2 273.5 13.6 18.9 21.0 25.2 transfer
595.0s 0 288.0 273.5 13.6 19.9 22.0 25.2 transfer
596.0s 0 254.0 273.4 13.6 44.0 50.3 56.6 transfer
597.0s 0 286.0 273.5 13.1 23.1 28.3 39.8 transfer
598.0s 0 281.0 273.5 14.2 21.0 27.3 35.7 transfer
599.0s 0 286.8 273.5 14.2 21.0 24.1 29.4 transfer
600.0s 0 281.0 273.5 13.6 22.0 27.3 31.5 transfer
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__total
600.0s 0 164111 273.5 14.6 14.2 21.0 29.4 218.1 transfer
_elapsed___errors___**ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result
600.0s 0 164111 273.5 14.6 14.2 21.0 29.4 218.1
The CPU Workload on one of the IBM ZLinux CRDB nodes looks good:

And across the entire cluster:

We will see lower utilization as the follow-the-workload model in CockroachDB means that most of the workload was handled by the nodes in IBM Cloud, the closest set of nodes to the load generator.
And next, we’ll give the YCSB benchmark a run:
root@crdb-test:~# ./cockroach workload init ycsb 'postgresql://root@crdb.uniblab.xyz:26257?sslcert=certs%2F/client.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt'
I220814 20:13:56.670291 1 workload/workloadsql/dataload.go:146 [-] 1 imported usertable (4s, 10000 rows)
root@crdb-test:~# ./cockroach workload run ycsb --duration=1m 'postgresql://root@crdb.uniblab.xyz:26257?sslcert=certs%2F/client.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt'
I220814 20:14:17.026607 1 workload/cli/run.go:414 [-] 1 creating load generator...
I220814 20:14:17.067951 1 workload/cli/run.go:445 [-] 2 creating load generator... done (took 41.343524ms)
_elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)
1.0s 0 664.9 692.5 5.0 7.3 11.0 31.5 read
1.0s 0 33.6 35.0 11.5 16.8 19.9 19.9 update
2.0s 0 680.1 686.3 5.2 7.6 8.9 15.2 read
2.0s 0 29.0 32.0 12.1 18.9 19.9 19.9 update
3.0s 0 627.1 666.6 5.8 8.1 12.1 18.9 read
3.0s 0 36.0 33.3 12.1 14.2 16.3 16.3 update
4.0s 0 644.2 661.0 5.2 7.9 21.0 24.1 read
4.0s 0 39.0 34.7 11.0 15.2 21.0 21.0 update
5.0s 0 684.6 665.7 5.2 7.6 11.0 19.9 read
5.0s 0 33.0 34.4 11.0 13.6 19.9 19.9 update
6.0s 0 711.1 673.3 5.0 7.1 8.9 14.7 read
6.0s 0 38.0 35.0 10.5 13.6 14.2 14.2 update
7.0s 0 675.2 673.5 5.5 7.3 8.9 11.5 read
7.0s 0 32.0 34.6 11.5 13.1 15.7 15.7 update
8.0s 0 666.9 672.7 5.2 7.6 12.1 22.0 read
8.0s 0 35.0 34.6 12.1 14.7 18.9 18.9 update
9.0s 0 674.3 672.9 5.2 7.9 14.2 22.0 read
9.0s 0 29.0 34.0 11.5 14.2 14.7 14.7 update
10.0s 0 657.4 671.3 5.2 7.6 16.3 22.0 read
10.0s 0 40.0 34.6 11.0 13.6 27.3 27.3 update
….
57.0s 0 676.0 687.6 5.5 7.6 9.4 14.7 read
57.0s 0 30.0 34.8 11.0 15.2 16.3 16.3 update
58.0s 0 658.3 687.1 5.2 7.9 14.7 23.1 read
58.0s 0 38.0 34.8 10.5 18.9 23.1 23.1 update
59.0s 0 670.9 686.8 5.0 8.4 14.2 30.4 read
59.0s 0 36.0 34.8 11.5 15.2 15.2 15.2 update
60.0s 0 662.5 686.4 5.5 8.4 10.5 19.9 read
60.0s 0 26.0 34.7 10.5 14.7 15.2 15.2 update
_elapsed__errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__total
60.0s 0 41183 686.4 5.3 5.2 7.6 12.1 31.5 read
_elapsed__rrors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__total
60.0s 0 2082 34.7 11.3 11.0 15.2 21.0 29.4 update
_elapsed__errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result
60.0s 0 43265 721.1 5.5 5.2 10.0 14.2 31.5
Alter survival goals
Now let’s do something interesting. Let’s make the bank database we previously ran a benchmark against and alter its survivability goals. We want that database to survive a regional failure.
root@crdb-test:~# ./cockroach sql --host=crdb.uniblab.xyz
#
# Welcome to the CockroachDB SQL shell.
# All statements must be terminated by a semicolon.
# To exit, type: \q.
#
# Server version: CockroachDB CCL v22.1.4 (s390x-ibm-linux-gnu, built 2022/07/21 17:24:18, go1.17.11) (same version as client)
# Cluster ID: ec960c5b-807b-41c6-924a-bd481f3a6755
# Organization: jeffreyw test
No entry for terminal type "xterm-256color";
using dumb terminal settings.
#
# Enter \? for a brief introduction.
#
root@crdb.uniblab.xyz:26257/defaultdb> show databases;
| database_name | owner | primary_region | regions | survival_goal |
| ------------- | ----- | -------------- | ------- | ------------- |
| bank | root | NULL | {} | NULL |
| defaultdb | root | NULL | {} | NULL |
| postgres | root | NULL | {} | NULL |
| system | node | NULL | {} | NULL |
| ycsb | root | NULL | {} | NULL |
(5 rows)
Now we need to tell CockroachDB bank’s primary region is the wa region, or IBM Cloud. And then we need to add the other two regions to the survivability goal of the database.
root@crdb.uniblab.xyz:26257/defaultdb> alter database bank set primary region wa;
ALTER DATABASE PRIMARY REGION
Time: 1.603s total (execution 1.602s / network 0.001s)
root@crdb.uniblab.xyz:26257/defaultdb> alter database bank add region mn;
ALTER DATABASE ADD REGION
Time: 1.531s total (execution 1.530s / network 0.001s)
root@crdb.uniblab.xyz:26257/defaultdb> alter database bank add region iad;
ALTER DATABASE ADD REGION
Time: 1.583s total (execution 1.582s / network 0.001s)
root@crdb.uniblab.xyz:26257/defaultdb> show databases;
database_name | owner | primary_region | regions | survival_goal
----------------+-------+----------------+-------------+----------------
bank | root | wa | {iad,mn,wa} | zone
defaultdb | root | NULL | {} | NULL
postgres | root | NULL | {} | NULL
system | node | NULL | {} | NULL
ycsb | root | NULL | {} | NULL
(5 rows)
Time: 53ms total (execution 52ms / network 1ms)
The next step is the magical bit. In most other SQL databases, this part is not easy. It can require a significant amount of engineering and cost to make work. With CockroachDB, we do it with one command.
root@crdb.uniblab.xyz:26257/defaultdb> alter database bank survive region failure;
ALTER DATABASE SURVIVE
Time: 1.207s total (execution 1.206s / network 0.001s)
root@crdb.uniblab.xyz:26257/defaultdb> show databases;
database_name | owner | primary_region | regions | survival_goal
----------------+-------+----------------+-------------+----------------
bank | root | wa | {iad,mn,wa} | region
defaultdb | root | NULL | {} | NULL
postgres | root | NULL | {} | NULL
system | node | NULL | {} | NULL
ycsb | root | NULL | {} | NULL
(5 rows)
Time: 51ms total (execution 50ms / network 1ms)
Now, let’s re-run our bank benchmark we ran above.
root@crdb-test:~# date; ./cockroach workload run bank --duration=10m 'postgresql://root@crdb.uniblab.xyz:26257?sslcert=certs%2F/client.root.crt&sslkey=certs%2Fclient.root.key&sslmode=verify-full&sslrootcert=certs%2Fca.crt'
Sun Aug 14 20:32:30 UTC 2022
I220814 20:32:30.567191 1 workload/cli/run.go:414 [-] 1 creating load generator...
I220814 20:32:30.581819 1 workload/cli/run.go:445 [-] 2 creating load generator... done (took 14.628169ms)
_elapsed___errors__ops/sec(inst)___ops/sec(cum)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)
1.0s 0 126.0 127.9 13.6 192.9 469.8 469.8 transfer
2.0s 0 262.2 195.0 14.7 22.0 37.7 50.3 transfer
3.0s 0 257.9 216.0 15.2 22.0 29.4 37.7 transfer
4.0s 0 261.0 227.2 15.2 22.0 26.2 35.7 transfer
5.0s 0 265.2 234.8 14.7 22.0 26.2 28.3 transfer
6.0s 0 253.0 237.8 15.2 23.1 26.2 39.8 transfer
7.0s 0 266.0 241.8 14.7 24.1 29.4 52.4 transfer
8.0s 0 271.0 245.5 14.7 19.9 24.1 35.7 transfer
9.0s 0 264.0 247.5 14.7 22.0 26.2 28.3 transfer
10.0s 0 270.9 249.9 15.2 21.0 25.2 29.4 transfer
….
593.0s 0 270.2 265.6 14.7 22.0 24.1 27.3 transfer
594.0s 0 271.0 265.6 14.7 22.0 25.2 35.7 transfer
595.0s 0 263.9 265.6 14.7 22.0 25.2 30.4 transfer
596.0s 0 269.2 265.6 14.7 22.0 24.1 26.2 transfer
597.0s 0 262.9 265.6 14.7 24.1 27.3 31.5 transfer
598.0s 0 285.0 265.7 13.6 21.0 27.3 30.4 transfer
599.0s 0 272.0 265.7 14.2 23.1 28.3 31.5 transfer
600.0s 0 266.8 265.7 14.7 22.0 26.2 32.5 transfer
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__total
600.0s 0 159412 265.7 15.1 14.7 22.0 29.4 469.8 transfer
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result
600.0s 0 159412 265.7 15.1 14.7 22.0 29.4 469.8
It’s slower, but not significantly slower. The workload looks similar to the first run.
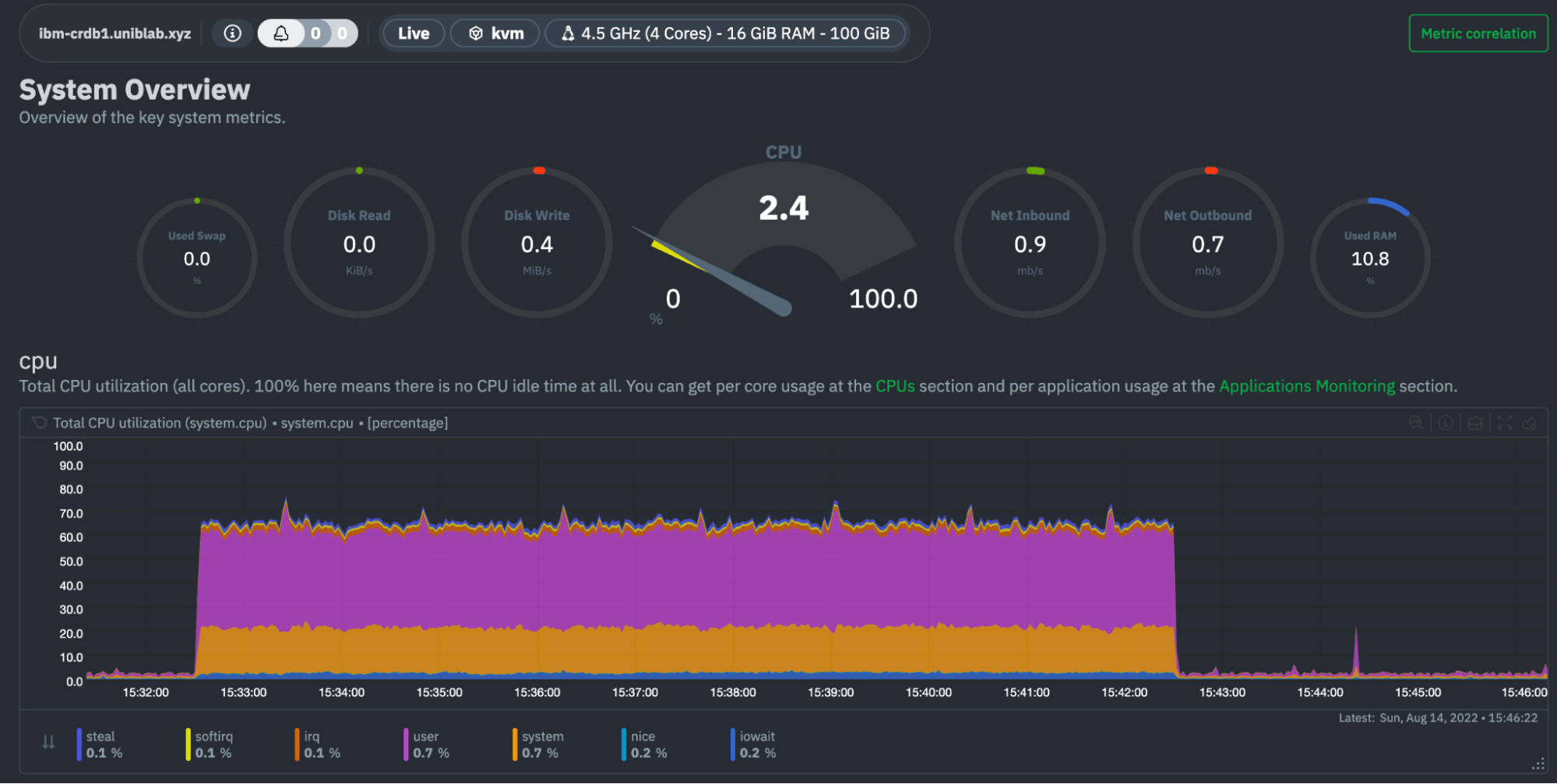
Across the cluster:

The benchmarks run as expected, demonstrating we are able to make a highly heterogeneous cluster work correctly. We’re using three different flavors of Linux, three different kinds of processor architectures, two different cloud providers and an onsite lab, all connected together through a virtualized software defined network. Making a single ACID SQL database.
If this is compelling to you or you’d like to see how CockroachDB could make your deployment more simple just reach out and we’ll set up a demo.


