

Quest for Meaning 
With our 24.2 release, CockroachDB adds support for the VECTOR data type, along with a set of pgvector compatible functions for doing interesting things like computing similarity between vectors. This article provides a brief overview of some related concepts and introduces a semantic search application to illustrate this new capability in action. These new functionalities demonstrate CockroachDB’s expanding support for AI-driven applications, such as Large Language Models (LLMs).
As a Solution Architect at Cockroach Labs, I collaborate with prospective customers to better understand the challenges they face with their data platforms. One such challenge that we are hearing about more recently is support for AI-powered applications. My own background in text search, coupled with the advent of vector support in CockroachDB 24.2, motivated this article. My hope is that, by reading along here with me, you'll gain an understanding of how CockroachDB can play a role in your own AI app development, whether that includes semantic search or some other novel application.
Semantic search in CockroachDB
What can these vectors represent? While we tend to associate vectors with spatial coordinate systems, such as (x, y, z) for the familiar three-dimensional world we live in, vectors are more general than that, and can be applied to scenarios as diverse as:
Features extracted from an image using, for example, a convolutional neural network (CNN)
Time series; e.g. measurements of CPU utilization on a computer taken at different times
Embeddings generated from a text input by a large language model (LLM)
Audio signals
And many other possibilities ...
What is semantic search? It's the ability to search for matching documents (sentences, paragraphs, etc...) based on how closely the meaning of the text aligns to my request for information (my query). Traditionally, text search has been more about how many of the words within the query match documents in the indexed collection, so the key difference here is that semantic search allows for matches even when the words themselves differ.
The key to this for semantic search is text embeddings. Embeddings map words, phrases, or sentences into different regions of a vector space, where the number of dimensions is much larger than three (typically 384, 768, or more, dimensions). The typical example is that the terms “cat” and “kitten” would occupy the same region in this space, while a word like “burrito” would be located somewhere else, possibly adjacent to “taco.” But there really isn't a way to assign meaning to any specific dimension of the vector. As an example, the vector for “cat” might look something like:
[0.023829686, 0.11193081, -0.008227681, -0.0017988624, 0.019233491, 0.050076663, ...]In the demo that this article is based on, the dimensionality of these vectors is 384, which is due to the fastembed TextEmbedding model I used to generate the embeddings. Above, I mention embeddings for a single word but in practice it's more sensible to embed larger chunks of text. The approach I took in the demo was to chunk text into sentences, since I reasoned that a sentence expresses a particular concept.
What's convenient about representing the text using vectors in this way is that there are very well-vetted techniques for assessing their similarity. The most common of these is probably cosine similarity, which you can visualize as a measure of the overlap between the two vectors. The way this is used in our demo is by incorporating the v1 <=> v2 operator in CockroachDB, for cosine distance. This yields a value between 0 and 1, so the SQL for doing the scoring looks like:
1 WITH q_embed AS
2 (
3 SELECT uri, chunk, embedding
4 FROM semantic.te_ca_view
5 WHERE cluster_id = :cluster_id
6 )
7 SELECT uri, 1 - (embedding <=> (:q_embed)::VECTOR) sim, chunk
8 FROM q_embed
9 ORDER BY sim DESC
10 LIMIT :limit
where the <=> operator appears on line 7 and :q_embed is bound to the embedding vector for the query. Here, the cosine similarity is used for scoring, with the result set ordered by that sim value and limited by the value bound to the :limit parameter.
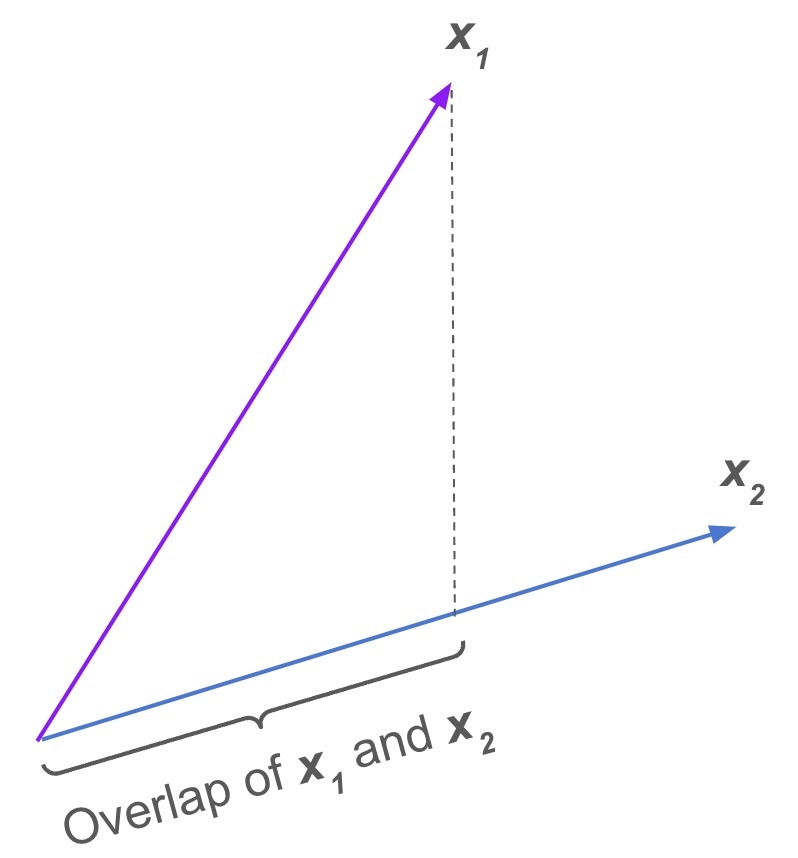
An illustration showing the overlap of vector X¹ onto vector X².
Referring to that SQL query above, you'll notice that it has two parts: a common table expression (CTE) called q_embed which is referenced by the scoring section of the query. The motivation for that approach is that, in its current state, the CockroachDB implementation of pgvector lacks index support, so the goal is to apply a predicate involving an index to reduce the amount of data being scored using the <=> operator. That cluster_id column refers to the ID of the K-Means cluster assigned to that row's vector embedding, and cluster_id is indexed. For the time being, the app provides its own means of indexing these vectors.
Research into efficient approaches to indexing these vectors is currently very active; as the authors of one recent paper put it, “Searching for approximate nearest neighbors (ANN) in the high-dimensional Euclidean space is a pivotal problem.” Cockroach Labs engineers have been actively reviewing the state of research in this area and have identified a few potential approaches that would align with the distributed, resilient, and consistent features inherent in CockroachDB. The initial work looks promising, so I’m looking forward to when we have index support for the VECTOR type. Then we can rework this demo and further improve performance.
K-Means clustering provides a well-tested approach to categorizing a collection of vectors, placing vectors into clusters based on similarity. Our goal is to take the entire set of N vectors and partition it into a set of K clusters, each one with a numeric ID that we can index. The goal is to minimize the number of rows scanned, to N/K on average, when computing the cosine similarity, so the query predicate initially incorporates that indexed cluster_id, then scores only the matching rows. Simultaneously, we must avoid choosing a value of K that is too large as that will cause us to miss relevant rows because they are mapped to different clusters. I found that optimizing this tradeoff required some experimentation. The relevant tuning parameters are specified via environment variables in the demo and are discussed in detail here.
Here is the list of parameters:
N_CLUSTERSTRAIN_FRACTIONKMEANS_MAX_ITER
The instantiation of the Sci-kit Learn K-Means model appears in the demo app as:
kmeans = KMeans(
n_clusters=n_clusters,
random_state=137,
init="k-means++",
n_init=10,
max_iter=kmeans_max_iter,
verbose=kmeans_verbose,
algorithm="elkan"
)
There are a few pre-trained K-Means models referenced in the demo, but the model can be refreshed by running the build_model.sh script in the demo repo against the data currently in the DB. Once that's complete, you must reassign the cluster ID values by running cluster_assign.sh.
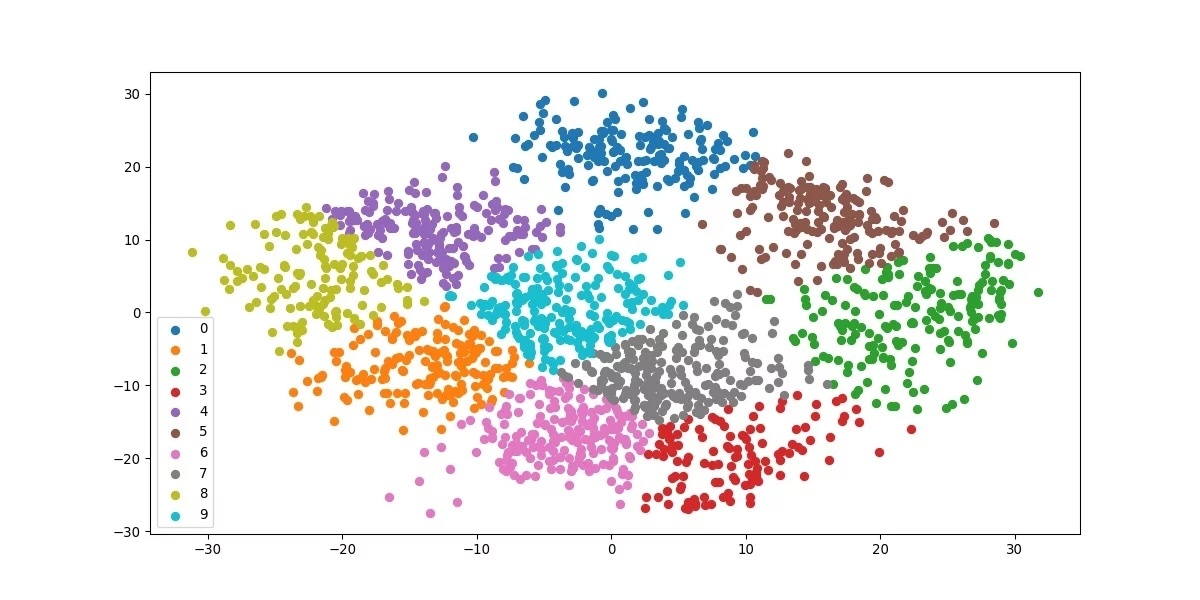
Illustration of K-Means clustering in two dimensions; each cluster is assigned a color.
I should also mention that, when the cluster reassign runs, it is inserting into a new table that will be incorporated into the VIEW used by queries once the process completes. For larger data sets, this becomes quite expensive since the creation of the K-Means model can be memory intensive and the reassignment of the cluster ID values requires a full scan of a potentially large table.
The upshot: This demo is interesting for smaller sized data sets, and I eagerly await the release of index support for the vector data type within CockroachDB for improved performance with larger data sets.
Semantic search in action
To illustrate how the demo app runs a semantic search using CockroachDB's vector support, I'll first refer to the GitHub repo for details of how to start the app and load some sample data. There is a very small data set within the ./data directory of that repo, but it's not difficult to index more text files or index data from a set of URLs. My setup here is running on an M2 MacBook Pro with 16 GB RAM. To get an idea of the data volume, I'll log into my DB and run a couple of count queries:
$ pgcli "postgres://test_role:123abc@127.0.0.1:26258/defaultdb"
Server: PostgreSQL 13.0.0
Version: 4.1.0
Home: http://pgcli.com
defaultdb> select count(distinct uri) from semantic.te_ca_view;
+-------+
| count |
|-------|
| 1614 |
+-------+
SELECT 1
Time: 2.703s (2 seconds), executed in: 2.700s (2 seconds)
defaultdb> select count(*) from semantic.te_ca_view;
+-------+
| count |
|-------|
| 31345 |
+-------+
SELECT 1
Time: 3.167s (3 seconds), executed in: 3.165s (3 seconds)So, there are 1614 distinct text files, yielding a total of 31345 sentences. Not terribly large, but sufficient to illustrate semantic search. Also, the subject of the example query is an electric car company called Lucid, so some additional insight into the data will help:
The data set contains three distinct files related to Lucid
There are 82 sentences arising out of the three Lucid-related files
44 of the indexed sentences contain some form of the word “Lucid” (we ignore case there)
defaultdb> select distinct uri from semantic.te_ca_view where uri ~ 'lucid';
+-------------------------+
| uri |
|-------------------------|
| data/lucid.txt |
| data/lucid_air_cd.txt |
| data/lucid_air_wiki.txt |
+-------------------------+
SELECT 3
Time: 0.058s
defaultdb> select count(*) from semantic.te_ca_view where uri ~ 'lucid';
+-------+
| count |
|-------|
| 82 |
+-------+
SELECT 1
Time: 0.078s
defaultdb> select count(*) from semantic.te_ca_view where chunk ~* 'lucid';
+-------+
| count |
|-------|
| 44 |
+-------+
SELECT 1
Time: 3.524s (3 seconds), executed in: 3.522s (3 seconds)Now for the fun part – I'll run a query for a topic that I know occurs within the index:
$ time ./search_client.sh What are the odds that Lucid becomes insolvent in the near term
[
{
"uri": "data/lucid.txt",
"score": 0.8327272634072758,
"chunk": "So, just how likely is it that Lucid goes bankrupt over the next five years?"
},
{
"uri": "data/lucid.txt",
"score": 0.8113045433811185,
"chunk": "I’d say there’s a 50/50 chance Lucid either goes bankrupt or thrives over the next five years, so this is a stock some investors may want to play cautiously from here."
},
{
"uri": "data/lucid.txt",
"score": 0.7721363117451124,
"chunk": "Let’s dive into the probability Lucid is still around in five years, and what investors may want to make of this stock moving forward."
},
{
"uri": "data/lucid.txt",
"score": 0.7509604171777308,
"chunk": "But given the various recessionary flags we’re seeing in the market, it’s unclear to me if Lucid can survive a prolonged recession (say two or three years) which wipes out consumer demand for higher-priced EVs."
}
]
real 0m0.065s
user 0m0.005s
sys 0m0.010sThat query, going through HTTP to the app, to the DB, and back, took 65 ms. Looking at the app's log file, the SQL query time is logged as about 10.73 ms -- not bad at all:
[10/04/2024 01:22:58 PM waitress-2] Query string: 'What are the odds that Lucid becomes insolvent in the near term'
[10/04/2024 01:22:58 PM waitress-2] Cluster ID: 406
[10/04/2024 01:22:58 PM waitress-2] SQL query time: 10.7269287109375 msMy query, “What are the odds that Lucid becomes insolvent in the near term,” matched several sentences, all from the data/lucid.txt file. The result set is limited to four items due to the export MAX_RESULTS=4 setting in the env.sh file which is sourced by the search_client.sh script, and the top ranked result was a match for the text, “So, just how likely is it that Lucid goes bankrupt over the next five years?”
Based purely on word matches – discarding common words like “are,” “the,” “in” – the term that stands out is Lucid. However, this latter term was present in all four of the matches, so it doesn't provide differentiation across the top results. The table below shows the association between each key query element and the corresponding section within the top search result:
Query | Search Result | Semantically Equivalent? |
What are the odds ... | ... how likely is it ... | ✓ |
... becomes insolvent ... | ... goes bankrupt ... | ✓ |
... in the near term ... | ... over the next five years ... | ✓ |
(Note: I hope that Lucid doesn't go bankrupt. I like electric cars!)
This ability to discover relevant material based on meaning rather than literal word matches is so powerful, and it's enabled by a combination of LLMs, embeddings, and the support for vectors within the database. Beyond that, CockroachDB's innate ability to thrive in adverse environments while ensuring transactional integrity, coupled with its horizontal scalability, has great potential to help you deliver always-on AI-driven experiences. We look forward to hearing about what you're able to build!
Thank you for joining me on this quest for meaning.
Learn more about how CockroachDB makes you AI-ready: Visit here to speak with an expert.
Suggestions for further reading


