



In today’s always-on digital world, even the most advanced systems are vulnerable to unexpected failures. Whether it’s an unhandled exception, a network outage, or a critical database failure, these disruptions don’t just slow you down—they can cost your business time, money, and customer trust. But what if your database didn’t just react to failure, but actively worked to prevent it?
CockroachDB is designed with resilience as a core principle. Its transactionally consistent, distributed architecture, automated failover, and self-healing capabilities ensure that your applications remain available and your data stays consistent—even in the face of the most unpredictable failures. From hardware malfunctions to gray failures, CockroachDB minimizes downtime, mitigates risk, and allows your systems to recover automatically.
In this 3-part series, “Surviving Failures with CockroachDB,” we’ll explore the most common failure scenarios affecting modern applications and databases — and, more importantly, how CockroachDB helps prevent, contain, and recover from them. In this first post, we’ll cover:
Common Application Failures: Handling crashes, resource exhaustion, and configuration issues with resilience.
Common Database Failures: Preventing data corruption, replication issues, and deadlocks.
By the end of this series, you’ll see how CockroachDB empowers businesses to build modern systems that don’t just perform well—they thrive in the face of adversity. Let’s dive in.
Common Application Failure Scenarios
One of the key initiatives we’ve seen coming out of enterprises around the globe is modernization. This can include modernizing your data infrastructure, your application, or moving towards AI. As the first commercially available distributed SQL database, CockroachDB is the trusted backend to a number of heavily trafficked applications.
CockroachDB is engineered to mitigate failure scenarios with built-in fault tolerance, automated recovery, and a distributed architecture that ensures your applications keep running smoothly—even in the face of unexpected failures. Below, we explore some of the most common application failure scenarios and how CockroachDB helps safeguard stability, security, and seamless performance.
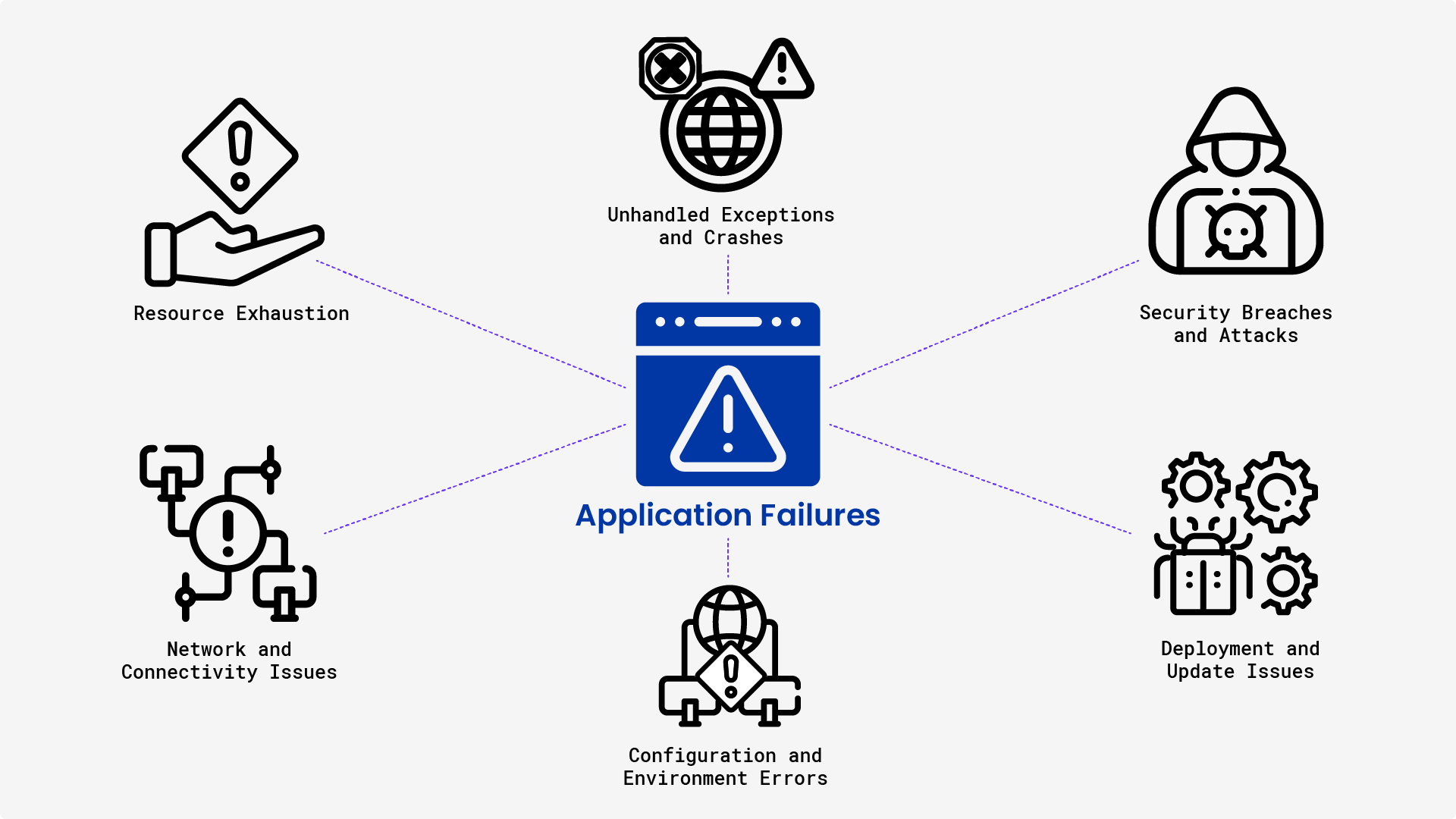
Unhandled Exceptions and Crashes
The Issue: Runtime errors (e.g., null pointer exceptions, segmentation faults) and logic flaws can cause abrupt application crashes.
How CockroachDB Helps:
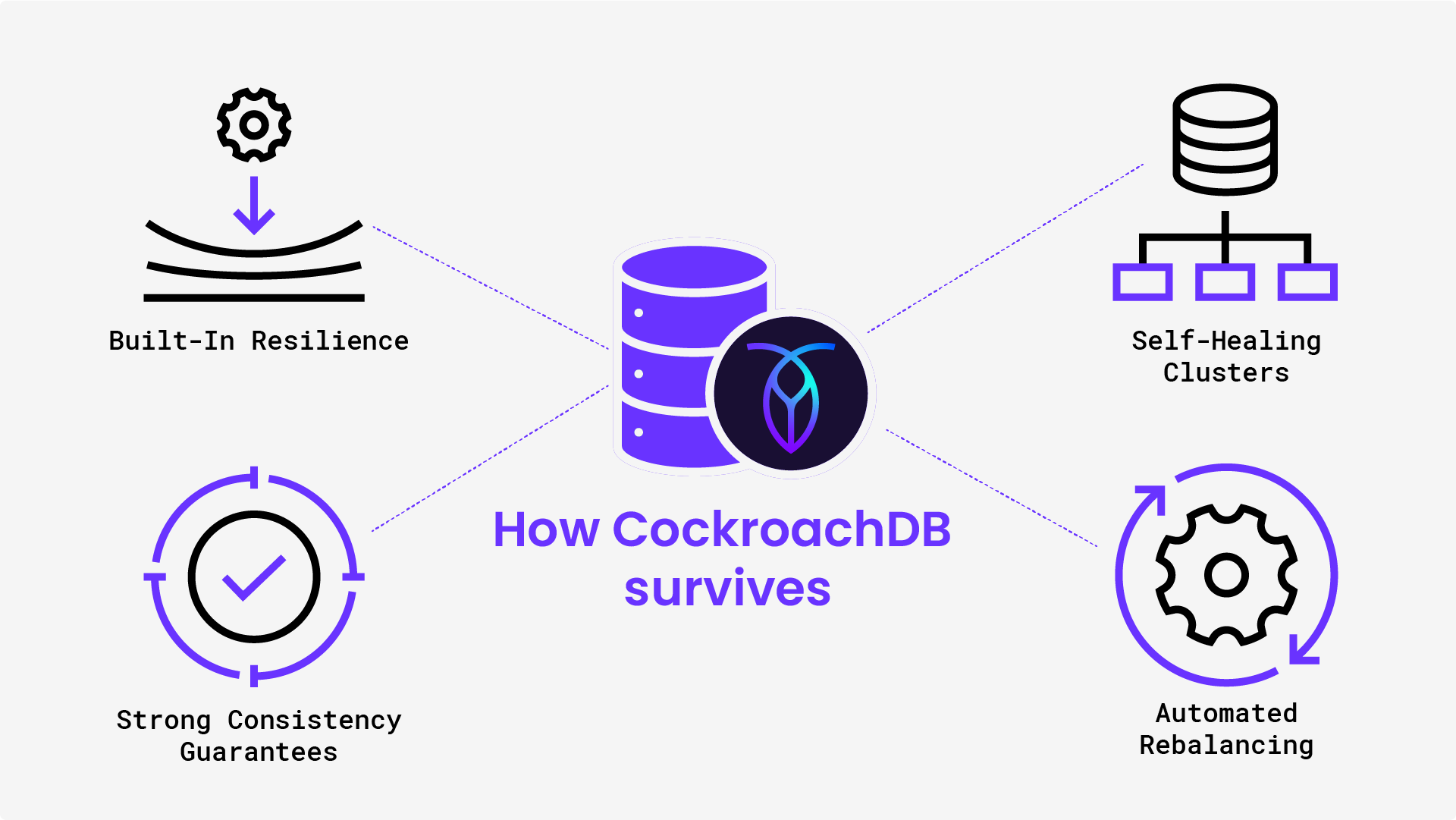
Built-In Resilience: CockroachDB automatically retries transient errors, reducing the impact of unexpected application crashes.
Consistent Data Handling: Strong consistency guarantees ensure that even if an application encounters an error, the underlying data remains reliable and ready for recovery.
Resource Exhaustion
The Issue: Memory leaks, CPU overload, and disk space shortages degrade performance and may lead to system crashes.
How CockroachDB Helps:
Distributed Architecture: Workloads are spread across multiple nodes, allowing CockroachDB to balance high resource usage dynamically.
Monitoring & Self-Healing: Integrated monitoring tools and automated recovery processes help prevent resource depletion by reallocating load before performance degrades.
Network and Connectivity Issues
The Issue: Outages, network partitions, slow responses, and timeouts in external APIs or services can lead to system failures.
How CockroachDB Helps:
Multi-Region Resilience: CockroachDB automatically routes requests to the nearest healthy node, ensuring continued availability.
Consensus Algorithms: Raft-based consensus ensures service continuity, even when individual nodes or network segments become unreachable.
Configuration and Environment Errors
The Issue: Misconfigurations, dependency mismatches, or version incompatibilities can destabilize applications.
How CockroachDB Helps:
Automated Cluster Management: CockroachDB includes tools that enforce best practices and minimize configuration drift across environments.
Seamless Upgrades & Scaling: Changes in one part of the system don’t inadvertently break others, reducing risk during deployments.
Security Breaches and Attacks
The Issue: Data exfiltration and man in the middle (MITM) attacks, can compromise security.
How CockroachDB Helps:
Built-In Security Features: Encryption at rest, TLS for data in transit, and role-based access controls help minimize attack surfaces.
Deployment and Update Issues
The Issue: Faulty releases and update failures can lead to regressions or extended downtime.
How CockroachDB Helps:
Rolling Upgrades: Non-disruptive, incremental updates ensure system reliability without downtime. Systems are designed to be multi-version so that the system remains operational even during an upgrade.
Automated Failover: If an issue arises during deployment, CockroachDB’s failover mechanisms maintain service availability.
Failures are inevitable, but with the right architecture in place, your applications don’t have to go down with them. By leveraging CockroachDB’s distributed, self-healing capabilities, you can build a system that is not just high-performing—but truly resilient in the face of adversity.
RELATED
To learn more about how CockroachDB can help your organizations bridge the gap between traditional and modern data infrastructure, check out our The Architect's Guide to SQL Database Modernization: Your Step-by-Step Roadmap.

Common Database Failure Scenarios
Moving beyond the scope of the application layer, even the most advanced databases and infrastructure are susceptible to failure. From disk crashes to network partitions, these disruptions can cripple traditional databases, leading to downtime, data loss, and expensive recovery efforts. CockroachDB, however, is engineered to withstand such failures with built-in fault tolerance, self-healing capabilities, and intelligent data replication.
In February, there was a major outage at Slack. A root cause analysis suggested that the outage was caused by an the underlying database and its sharded system:
We traced this issue to a maintenance action in one of our database systems, which, combined with a latency defect in our caching system, caused an overload of heavy traffic to the database.
Remediation work involves repairing affected database shards, which are causing feature degradation issues. This has become a diligent process to ensure we’re prioritizing the database replicas with the most impact.
In this section, we’ll explore the most common database failure scenarios like Slack’s and how CockroachDB ensures continuous availability, data integrity, and seamless recovery—even when hardware and networks fail.
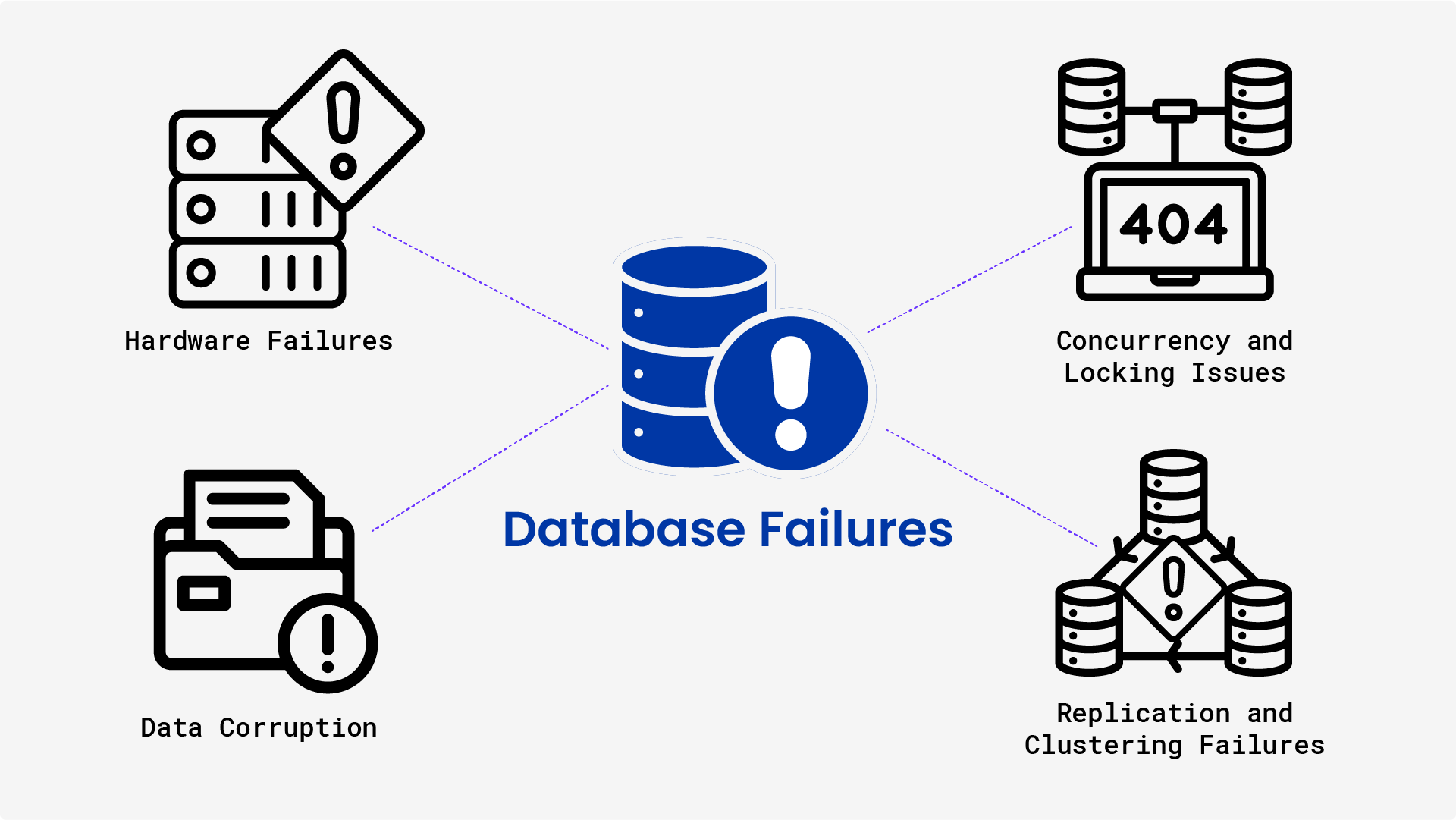
Hardware Failures
The Issue: Disk failures, memory malfunctions, or other hardware issues can result in data loss or an unresponsive database.
How CockroachDB Helps:
Fault Tolerance & Replication: Data is automatically replicated across multiple nodes, ensuring that if one node or disk fails, another seamlessly takes over—so no single hardware failure can bring down the system. Our latest WAL Failover enhancement further reduces the impact of disk failures and stalls, improving overall resilience.
Self-Healing Capabilities: CockroachDB continuously monitors node health and automatically rebalances data when hardware issues are detected.
Data Corruption
The Issue: Faulty writes or unexpected shutdowns can cause data corruption or inconsistencies within the database.
How CockroachDB Helps:
Strong Consistency Guarantees: CockroachDB uses the Raft consensus protocol to ensure that writes are committed only when a majority of replicas agree, significantly reducing corruption risks.
Automatic Consistency Checks: Continuous internal verification detects and corrects inconsistencies before they become critical.
Network Partitioning and Connectivity Issues
The Issue: In distributed systems, network partitions can isolate nodes, leading to split-brain scenarios or data inconsistency.
How CockroachDB Helps:
Designed for Partitions: CockroachDB gracefully handles network partitions, ensuring the system remains consistent and available even if parts of the network become isolated. In Cockroach DB version 25.1 we’ve introduced Leader Leases, a new leasing mechanism that particularly excels at reducing the impact of partial network partitions.
Automatic Request Routing: Queries are dynamically rerouted to healthy nodes, minimizing downtime during connectivity disruptions.
Concurrency and Locking Issues
The Issue: Deadlocks and high lock contention can stall operations and degrade performance.
How CockroachDB Helps:
Distributed Transaction Model: CockroachDB minimizes locking conflicts by using serializable isolation for distributed transactions, ensuring reliability even under high concurrency.
Optimized Concurrency Control: Parallel Commits bridge the gap between pessimistic (PCC) and optimistic (OCC) concurrency control to cut latency of transactions, while keeping resilience benefits. Amazon DSQL only utilizes OCC and snapshot isolation level might result in performance issues for certain workloads that contain hotspots and concurrent writes
Replication and Clustering Failures
The Issue: Delays or failures in data replication can lead to stale reads or partial outages in clustered environments.
How CockroachDB Helps:
Self-Healing Clusters: The system monitors node health and automatically recovers from replication failures, ensuring data remains evenly distributed.
Automated Rebalancing: When nodes fail or are added, CockroachDB automatically redistributes data to maintain optimal performance and availability.
If you don’t believe us, watch this video to see technical evangelist, Rob Reid, try (and fail) to break CockroachDB:
Inevitable failures, preventable catastrophes
Failures are inevitable, but they don’t have to be catastrophic. CockroachDB’s distributed, self-healing architecture ensures that your database remains operational, consistent, and resilient—no matter what challenges arise. Whether it's hardware malfunctions, network failures, or data corruption, CockroachDB is built to recover and adapt, keeping your applications running without disruption. Check back on our blog for the next post in this series, which will cover surviving system-wide failures and cloud service provider outages.
Get started with CockroachDB Cloud today. We’re offering $400 of free credits to help kickstart your CockroachDB journey, or get in touch today to learn more.



