

Editor’s Note: Since this post was originally published on The New Stack in 2015, CockroachDB has grown into a $2B evaluation and can publicly claim customers like Bose, SpaceX, Comcast and many others. For an up to date description of how CockroachDB compares to incumbent database products check out this short video:
The goal of CockroachDB is to make data easy. If you could take all the energy wasted wrestling with database shortcomings, and invest that time, money and engineering into making your company stronger and your product better, everyone would be better off.
Databases are the life-blood of every modern business, yet despite nearly 45 years of evolution, developers are left with a small range of options:
RDBMS: Fully featured with transactions and indexes, but are not scalable and fault-tolerant. If your business grows beyond the capacity of a single node, you’ll have to resort to sharding, which is not a good option.
NoSQL: Designed for massive horizontal scale, these systems sacrifice transactions and consistency, and eschew explicit schemas. These are features which increasingly complex applications require.
Hosted Services: These are storage services that require vendor lock-in and are all proprietary. Their functional guarantees are difficult to verify.
The biggest frustration with these options is that if a company succeeds, and especially if it succeeds wildly, it will be extremely expensive to scale, both in financial and engineering resources. None of these solutions are scalable, transactional, and available, which is why we were inspired to build CockroachDB.
CockroachDB is a distributed SQL database built on top of a transactional and consistent key-value store. The primary design goals are support for ACID transactions, horizontal scalability and survivability (hence the name). CockroachDB implements a Raft consensus algorithm for consistency and aims to tolerate disk, machine, rack and even data center failures with minimal disruption and no manual intervention.
So how does CockroachDB work? Let’s start with a look at the architecture.
A Layered Architecture
CockroachDB’s architecture is structured in layers that make complexity an easier task to manage. Each higher level in the architecture treats the lower levels as functional black boxes, while the lower layers remain completely unaware of the higher ones.
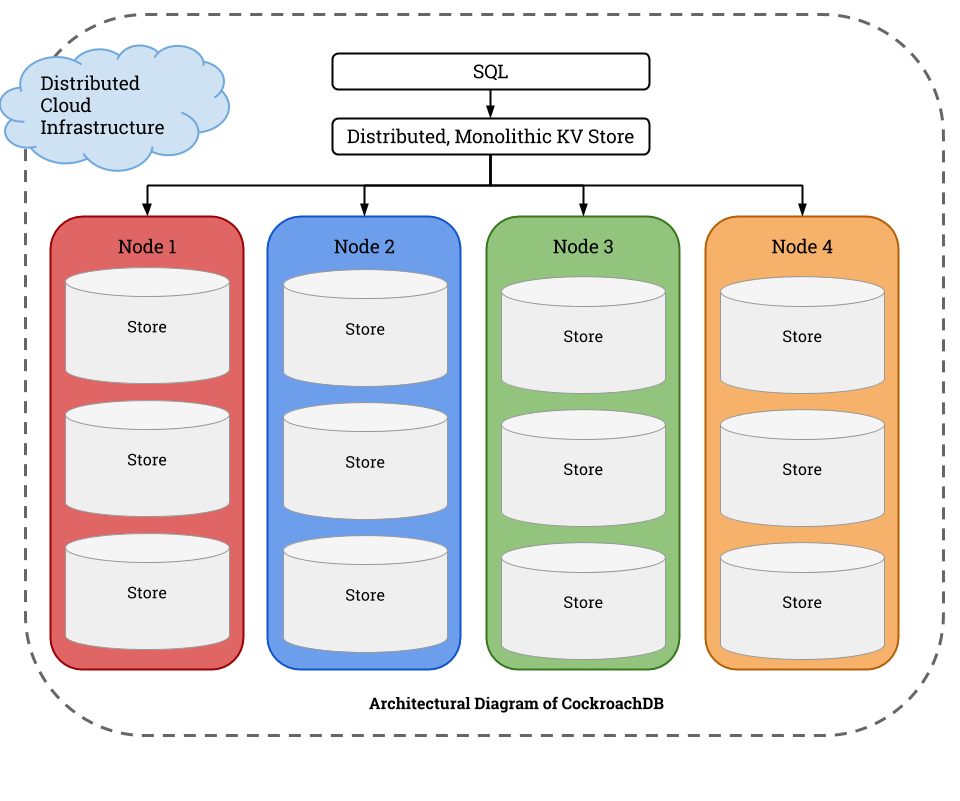
SQL Layer: The highest level of abstraction and a well-established API for developers. Provides familiar relational concepts such as schemas, tables and indexes using a derivative of the Postgres grammar with some modern touches.
Distributed Key:Value Store: We implement our distributed key-value store as a monolithic sorted map, making it easy to develop large tables and indexes (Hbase, BigTable, and Spanner all use similar architectures).
Distributed Transactions: Not necessarily a part of the layered architecture, but a fundamental part of the system. The implementation of distributed transactions suffuse the layers of the architecture: from SQL to stores and ranges.
Nodes: The physical machines, virtual machines, or containers that contain stores. The distributed KV store routes messages to nodes.
Store: Each node contains one or more stores, and each store contains potentially many ranges. Every store is managed with RocksDB, an open source storage engine from Facebook based on Google’s LevelDB.
Range: Every store contains ranges, which are the lowest-level unit of key-value data. Each range covers a contiguous segment of the larger key-space — one at the start of the alphabet, the next in the middle of the alphabet, and so on. Together, they make up the entire monolithic sorted map. The range is where we do synchronous replication, usually three or five way, using the Raft consensus algorithm, a variant of Paxos.
From here, we’ll walk through the design of CockroachDB starting at the lowest level and working our way up to show how it achieves three key properties: Transactionality, Scalability, and Survivability.
Horizontal Scaling
Let’s consider CockroachDB at its lowest level, running on a single machine. Even though the data is logically organized into tables, rows, columns, etc., at the lowest level, individual pieces of data (think of a single column value) are stored on-disk in a sorted key-value map.
CockroachDB starts off with a single, empty range of key-value data encompassing the entire key space. As you put more data into this range, it will eventually reach a threshold size (64MB by default). When that happens, the data splits into two ranges, each of which can be accessed as a separate units, each covering a contiguous segment of the key space. This process continues indefinitely as data is added (see figure below).

The monolithic sorted map in CockroachDB is made up of the sorted set of all ranges — one at the start of the alphabet, the next in the middle of the alphabet, and so on. We opt for small ranges as they’re easily moved between machines when repairing or rebalancing data. As new data flows in, existing ranges will continue to split into new ranges, aiming to keep a relatively consistent range size somewhere between 32MB and 64MB.
When our cluster spans multiple nodes and stores, newly split ranges are rebalanced to stores with more capacity available.

This design gives you a scalable database that can run across many different nodes. To make the database survivable, CockroachDB has to replicate the data.
Replication
By default, each range is replicated on three nodes. Any number can be configured, but three and five are often considered the most useful. Range replicas are intended to be located in disparate datacenters for survivability (e.g. { New York, Virginia, California }, { Ireland, New York, California}, { Ireland, New York, California, Japan, Australia }).

When you have data that is stored across multiple machines, it’s important that the data be consistent across replicas. CockroachDB uses Raft as its consensus protocol. Each range is an independent instance of the Raft protocol, so we have many ranges all independently running Raft. This allows a considerable degree of flexibility, including arbitrary replication configurations for different segments of the key space.
In any group of replicas, one of the nodes will be elected the leader, which then coordinates the decisions for the group. Whenever you want to write something to the database, it goes to the leader to be proposed to the cluster, and is committed as soon as it has been acknowledged by a majority (either by 2 out of 3 or by 3 out of 5 of the replicas).
We actually share this implementation of the Raft protocol with the etcd team, but add another layer for scalability. In CockroachDB, each Range corresponds to a Raft instance, and their number is much higher than that of the physical nodes hosting them. To help scale Raft we built MultiRaft, a layer on top of Raft which groups messages sent by the replicas.
Distributed Transactions
One of the foundations of CockroachDB is strong consistency and full support of distributed ACID transactions. CockroachDB provides distributed transactions using multi-version concurrency control (MVCC). MVCC data is stored and managed on each local storage device with an instance of RocksDB. Mutations to MVCC data are consistently replicated using Raft.
CockroachDB provides snapshot isolation (SI) and serializable snapshot isolation (SSI), allowing externally consistent, lock-free reads and writes, both from a historical snapshot timestamp and from the current wall clock time. SSI is provided as the default isolation level; SSI eliminates some rare anomalies which are present with SI, but suffers worse performance in the event of contention. Clients must consciously decide to trade correctness for performance.
For more information on how CockroachDB approaches transactions, read this blog post.
CockroachDB’s SQL implementation leverages the distributed transactions and strong consistency provided by the monolithic sorted key-value map to consistently encode, store, and retrieve the SQL table data and indexes. The SQL grammar supported is a derivative of PostgreSQL with some modern touches, and supports any Object-Relational Mapping (ORM).
For more information on CockroachDB’s SQL implementation, read this blog post and check out our SQL branch on Github.
Deployment and Management
We built CockroachDB to have a simple deployment that fits well with the container model. Nodes are symmetric and self-organize — there’s no single point of failure, no complicated configuration (in fact, only a handful of command-line options), nor is there a tangle of different roles to be managed. All that’s required is a single binary (easily put into a container) which runs on each node in order to join the cluster and export the local stores for accepting new writes and rebalances.
CockroachDB self-organizes by using a gossip network, which is a peer-to-peer network where nodes communicate with each other. A new node can join the gossip network as long as it can talk to any other node which has already joined. The gossip network continually balances itself to to minimize RPC traffic and the number of hops required to communicate new information to each node in the network. Nodes exchange their network addresses as well as store capacity information. If a node discovers that it has more capacity than the mean of its neighbors, it will start to rebalance the range to the other nodes. Similarly, if a node goes down, the replicas of its constituent ranges will notice its absence and look for another node to which they can re-replicate.
CockroachDB can be run locally on a laptop, corporate dev cluster or private cloud, as well as on any public cloud infrastructure. We’ve developed cockroach-prod which, at the time of this writing, lets you set up a cluster on Amazon Web Services and in Google Cloud Engine. Support for other public cloud infrastructure and additional features are in the works.
What’s Next
At the time this post was originally written CockroachDB was in Alpha. That is, of course, no longer the case. With companies like SpaceX, and Tesla using CockroachDB in production today the next step for CockroachDB is to continue pushing it’s DBaaS offering, CockroachDB Dedicated, into the minds of developers so that they can take advantage of the distributed computing advantages like scale, resilience, and data locality. Aditionally, to further cement itself as the best database for Kubernetes, CockroachDB is polishing the Kubernetes Operator that is available in the open source version of CockroachDB today.


