


With CockroachDB release 24.3 we are introducing write-ahead log (WAL) failover, a solution for transient disk stalls commonly seen in cloud storage. During a disk stall, the underlying storage is not available, adding application latency. While we can’t prevent disk stalls, WAL failover helps minimize their impact on CockroachDB instances.
I’m super excited about this feature, mostly because there are pretty pictures involved to simply demonstrate the powerful and meaningful impact this feature brings to customers.
Let’s take a look at how WAL failover works.
What is the write-ahead log (WAL)?
The write-ahead log (WAL) is a copy of the memtable and used to ensure its durability in case of failure. The replication layer issues updates to the storage engine and stores the updates on disk. The freshest updates are stored in the WAL in the disk. Each WAL has a one-to-one correspondence with a memtable; the two are kept in sync, and updates from the WAL and memtable are written to Sorted String Tables (SSTs) periodically as part of the storage engine's normal operation.
What are disk stalls?
A disk stall can be caused by hardware failure, busy disks, or IOPS rate limitation. Cloud providers also deliberately over-provision block storage devices and then throttle IOPS, which exhibits as disk stall to the upper layer applications. While stalled, users are unable to access the WAL, adding application latency.
The challenge is that while a disk stall could be due to a complete hardware failure, it is more likely a transient stall. If it’s a hardware failure, we want to take the node out of the cluster and let the cluster heal. But if it’s a transient disk stall we want to simply mitigate the latency introduced by the stall.
Transient disk stalls are common. They often last on the order of a few seconds but have been seen to last 20+ seconds. They are hard to troubleshoot too because they’re so transient.
In the field, we have observed that stalls occur most frequently while writing to the WAL. Here’s an example from our labs showing how common disk stalls are. This chart shows the number of times a disk stalls for longer than 100ms, the default value that WAL Failover kicks in:

The impact of implementing WAL failover
WAL failover uses a secondary disk as a fail-to for the write-ahead log so that when the primary disk stalls, failover to the secondary occurs and solves the problem of write latency in the presence of a disk stall.
WAL failover happens at a configurable interval, defaulting to 100ms. When failover occurs there isn’t any disruption to access the data ranges homed on the stalled disk (for writes; reads that do not find data in the block or page cache will still stall).
Without failover, the default is to wait 20s for the node to crash before redistributing data and making it accessible again unless the stall clears sooner, in which case things continue as usual. Though Raft provides a self-healing protocol for redistributing data upon a failure, it’s not the kind of process you want to trigger for transient disk stalls at the millisecond time-scale because of the overhead involved in renegotiating Raft leaders and redistributing data ranges. With the default value of 20s we’re trying to balance latency against protocol overhead. With WAL failover we get to maximize for both.
Let’s take a look at what happened in our lab when we turned on WAL failover:
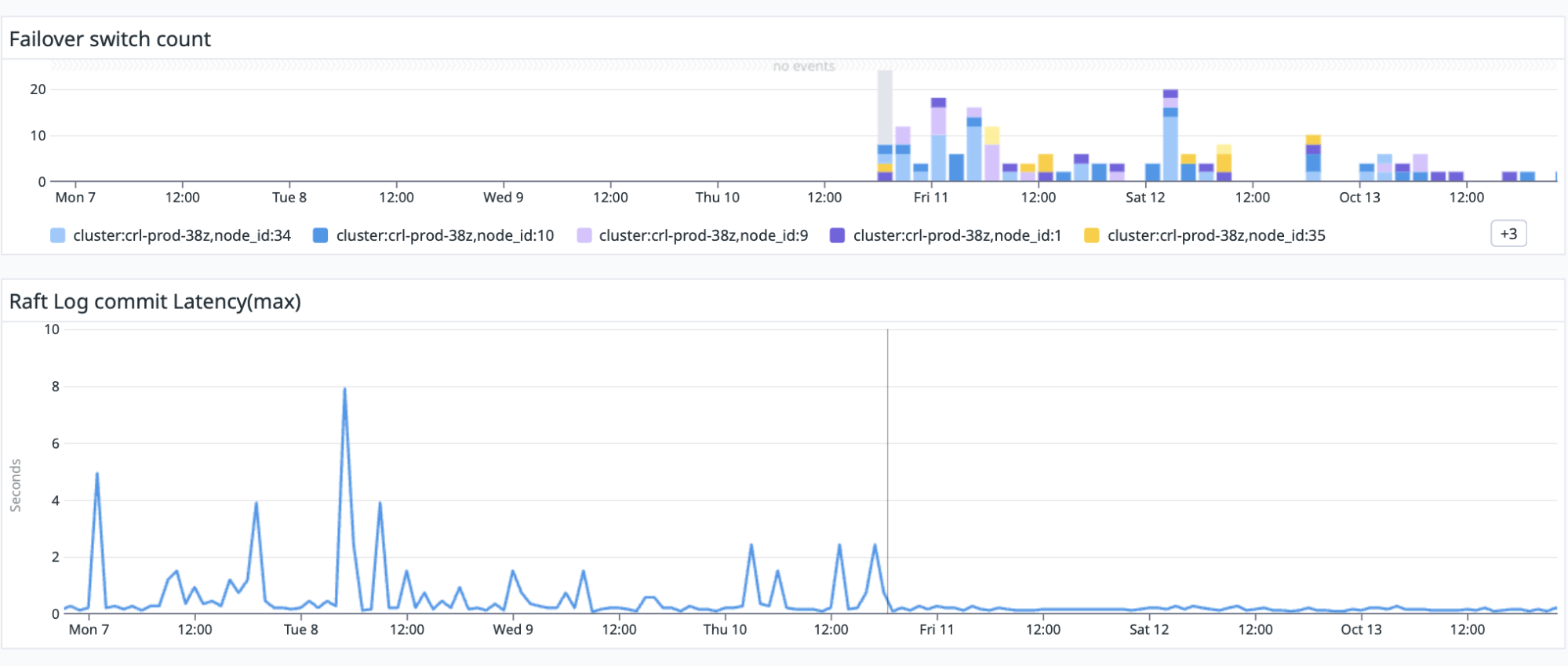
I told you these pictures tell a great story! Look at the latency impact on the bottom chart. Once WAL failover was implemented latency stopped spiking to ‘seconds’ and stayed pretty steady at the ~200ms mark.
The top half of the above chart shows how often WAL failover kicked in. The number of stalls is non-trivial.
Failing hardware
One interesting tidbit that I learned when digging into how this works…we still want to know if the disk is failing so that we can take the node out of the cluster. If the original disk stall doesn’t clear in the max_sync_duration (default 20s, recommended 40s when using WAL failover) we still declare the node as unavailable and remove it from the cluster.
What we’re achieving with WAL failover is lowering latency for random “architectural stalls” (those generally related to the way cloud storage is designed to be over-provisioned and then throttled), without hiding underlying hardware problems.
Of course, WAL failover isn’t just for cloud storage users.
When to use WAL failover
WAL failover is highly recommended for any deployment on AWS, Azure, or GCP that uses network storage devices, for example EBS on AWS, Disk Storage for Azure, and Networked Persistent Disks for GCP.
It’s recommended for any deployment on AWS, Azure, or GCP that uses local SSD, or for on-premise installations where disk stalls are occurring (as observed by maximum wal.fsync.latency > 100 ms) and you have the ability to add a disk on each node.
Watch this demo to learn more
WAL failover is another deep feature that enables CockroachDB to stay on top of the resilience game, while delivering the most advanced multi-cloud distributed SQL database in the market.
To learn more about WAL failover, check out this demo video:


