RTO vs RPO
RTO vs RPO
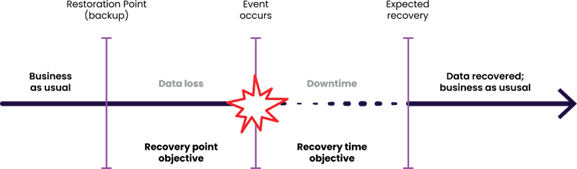
RTO (Recovery Time Objective) and RPO (Recovery Point Objective) are two critical metrics in disaster recovery and business continuity planning. They help you answer two essential questions when an outage or disaster strikes:
How quickly do we need to recover? (RTO)
How much data can we afford to lose? (RPO)
Understanding these objectives allows businesses to design and implement a robust strategy that balances cost, complexity, and risk tolerance. Below, we’ll explore what RTO and RPO mean, how they differ, their role in disaster recovery, and best practices for meeting these objectives. After that, we’ll address frequently asked questions in the FAQ section.
What is RTO?
Recovery Time Objective (RTO) is the maximum acceptable downtime for your systems after an outage or disaster. If operations do not resume within the RTO, the business may experience unacceptable costs, lost revenue, or reputational damage.
Key Characteristics of RTO
Focus on Downtime: RTO measures how quickly you must restore services after a disruption.
Business-Driven: RTO typically aligns with financial or operational thresholds. For instance, an online retailer might have an RTO of one hour for its ordering system, because every hour of downtime equates to lost sales.
Measured in Time Units: RTO is usually expressed in hours or minutes, though some mission-critical systems push it down to seconds.
For example, if your customer database fails at 2:00 PM and your RTO is 2 hours, your goal is to have the system up and running again by 4:00 PM. Missing this deadline means you are out of compliance with your own recovery objective, which comes with potential financial or reputational consequences. In fact, downtime can be extremely costly, with some businesses losing up to $427 per minute for smaller operations and significantly more for larger enterprises. On an hourly basis, industries like healthcare and retail face costs of $636,000 and $1.1 million, respectively. Moreover, companies can lose substantial revenue, with some experiencing losses between $100,000 and over $1 million per outage. Therefore, meeting RTOs is crucial to minimize these financial impacts.
Balancing Cost and Speed
Shorter RTOs typically require redundant systems, automation, and higher availability architectures. While this can minimize the damage of downtime, it also often increases costs. Finding a balance involves:
Weighing the cost of downtime (lost transactions, customer dissatisfaction).
Evaluating the cost of continuous availability (hot standbys, distributed systems, high-speed network connections).
Many modern systems, such as distributed SQL databases (e.g., CockroachDB), help reduce RTO by automatically re-routing traffic if a node or region goes offline, thereby shortening downtime.
What is RPO?
Recovery Point Objective (RPO) is the maximum acceptable amount of data loss when systems are restored. It defines how far back in time your recovery process can “roll back” data to a consistent state.
Key Characteristics of RPO
Focus on Data Loss: RPO addresses how much recent data might be irretrievable following an incident.
Driving Backup Frequency: RPO influences how often data backups or replications must occur to ensure that any lost data falls within acceptable limits.
For example, if your RPO is 15 minutes, you have determined the business can tolerate losing up to 15 minutes of recent transactions. To achieve this, you might rely on near-real-time replication or frequent incremental backups. If a disaster strikes at 3:00 PM, you can confidently restore from a snapshot taken at 2:45 PM, with only 15 minutes of potential data loss.
Zero RPO
A zero RPO means no data loss is acceptable. Often, this requires synchronous replication to multiple sites, ensuring every transaction is committed across multiple locations before it’s considered final. Distributed databases can get close to zero RPO by writing data to multiple replicas, minimizing the risk of data loss.
Balancing Cost and Downtime
While a short Recovery Time Objective (RTO) helps minimize downtime—and the associated revenue loss or reputational damage—it often demands more robust infrastructure, specialized failover mechanisms, and a skilled IT response team. For example:
Infrastructure Costs: Maintaining hot standby systems, redundant servers, and automated failover solutions can be expensive, but these investments significantly reduce potential downtime.
Complexity vs. Speed: Highly available architectures (e.g., distributed databases or clustered applications) may increase operational complexity, yet they can restore services within minutes—or even seconds—when a primary node fails.
Opportunity Costs: Some organizations find that a marginal improvement (e.g., reducing RTO from 30 minutes to near-zero) requires disproportionately higher spending. Weigh this extra cost against the potential revenue loss or compliance penalties incurred if you exceed your RTO.
Risk Mitigation: If your business model depends on continuous operations (e.g., online retail, financial services), the risk of extended outages may far outweigh the cost of additional infrastructure. Conversely, for non-mission-critical workloads, a slightly longer RTO might be acceptable given a lower budget.
Striking the right balance requires collaborating with both technical stakeholders and business leaders to determine how much downtime is tolerable — and what the organization is willing to spend to prevent it.
Difference between RPO and RTO: Explained
Interplay Between the Two
It’s possible to meet one objective but not the other. For example, you could restore a system quickly (meeting RTO) but revert to a backup from hours earlier (failing your RPO). Conversely, you might restore to a perfectly up-to-date data state (RPO met) but require several hours of downtime (RTO not met).
Organizations typically set RTO and RPO targets simultaneously based on risk tolerance, budget, and operational needs
For many business-critical applications, both low RTO and low RPO (i.e., fast recovery and minimal data loss) are required. This can drive adoption of high-availability architectures and continuous data protection solutions.
RPO and RTO in Disaster Recovery and Business Continuity
Visit the Webinar: “The Always-on Dilemma: Disaster Recovery vs. Inherent Resilience”
Peter Mattis, CTO and co-founder at Cockroach Labs joins Rob Reid, Technical Evangelist, to discuss ways to build inherently resilient systems coupled with defense in depth strategies.
Disaster Recovery (DR) focuses on the technical aspects of restoring IT systems after a disruption, while Business Continuity (BC) considers the wider organizational response to maintain essential functions. RPO and RTO are cornerstones in both realms:
Defining Tolerable Disruption
RTO sets the maximum downtime for critical operations before severe damage occurs (e.g., lost revenue, regulatory penalties).
RPO sets the maximum data loss your organization can handle without damaging credibility or violating compliance rules.
Influencing Technology Choices
If your RPO is near-zero, you might opt for real-time replication and distributed databases that write data to multiple nodes.
If your RTO is extremely short, you may implement auto-failover, hot standbys, or container-based microservices that can redeploy quickly.
Supporting Compliance
Regulatory standards in sectors like finance and healthcare often mandate certain recovery capabilities.
Internal SLAs or external contracts can specify RTO and RPO targets as measurable obligations.
Driving Investment
The lower (stricter) your RTO and RPO, the more you typically invest in infrastructure, replication, offsite backups, and skilled personnel.
Some businesses opt for multi-region or multi-cloud setups to ensure resilience. For instance, CockroachDB’s multi-region capabilities allow data to be replicated closer to users and automatically fail over.
Real-World Example: E-commerce Platform
RTO: 30 minutes. Beyond this point, lost sales and frustrated customers become unacceptable.
RPO: 5 minutes. Because orders, payments, and customer data are vital, losing more than five minutes of transactional data could cause confusion over inventory, financial records, and shipping addresses.
To achieve these goals, the company might employ a distributed SQL database for near-real-time data replication and maintain hot standby servers that can take over almost instantly. The investment in servers, networking, and automation is offset by the reduction in lost sales if a primary server goes down.
Related
Architect your zero downtime strategy with CockroachDB: The Definitive Guide.
Best Practices for Optimizing RPO and RTO
Achieving minimal data loss and fast recovery requires a combination of smart planning, technical solutions, and ongoing maintenance. Below are proven best practices to help your business optimize RPO and RTO.
1. Conduct a Business Impact Analysis (BIA)
A BIA identifies critical business processes, quantifies potential losses, and determines acceptable downtime. This helps you:
Prioritize Systems: Not all applications are equally critical.
Set Realistic Targets: Define RTO and RPO values based on the real-world impact of downtime or data loss.
2. Tier Your Applications
Categorize applications into tiers. For example:
Tier 1: Mission-critical systems (e.g., customer-facing payments).
Tier 2: Important systems (e.g., internal reporting, HR).
Tier 3: Non-critical or infrequently used systems.
Assign stricter RTO and RPO to Tier 1 applications while allowing more relaxed targets for lower tiers. This approach ensures you allocate resources appropriately rather than over-investing across the board.
3. Choose the Right Data Protection Strategy
Data backup and replication strategies must align with your RPO:
Frequent Snapshots or Continuous Backups: If you require a very low RPO, schedule backups frequently.
Cloud and Offsite Storage: Keep backups offsite or in the cloud for protection against local disasters.
Encryption and Integrity Checks: Ensure backups are both secure and verified to prevent restoration failures.
4. Leverage High Availability (HA) Architectures
To minimize RTO, invest in resilient architectures that reduce or eliminate downtime:
Distributed Systems: A multi-region, distributed SQL database can automatically redirect queries if one node fails, often delivering near-continuous availability.
Clustering and Failover: Automated failover to a hot or warm standby can restore operations within seconds or minutes.
Containerization and Orchestration: Tools like Kubernetes simplify redeploying services on healthy nodes, cutting recovery times.
5. Automate and Document Recovery Procedures
Manual processes can slow you down during an emergency:
Automated Failover Scripts: Trigger an immediate failover to a standby instance.
Infrastructure-as-Code: Provision new servers quickly using scripted configurations.
Comprehensive Documentation: Keep runbooks current and store them in an accessible, fail-safe location.
6. Test Regularly
Testing is an essential part of an enterprise discovery recovery plan to confirm you can meet your stated objectives:
Disaster Recovery Drills: Simulate real outages or data loss scenarios.
Restore from Backups: Verify backups are valid and that your recovery time meets RTO.
Measure and Refine: Compare actual recovery metrics with your targets, then adjust resources or processes as needed.
7. Continuously Review and Update
Business requirements, infrastructure, and threats can change:
Track System Growth: Larger data volumes may slow backup procedures.
Adopt New Technologies: For instance, if a new distributed storage service improves replication speeds, you might achieve tighter RPO.
Revisit BIA: Ensure your objectives still align with new business lines, regulations, or market demands.
By following these best practices, your organization can systematically reduce downtime (RTO) and limit data loss (RPO), giving you a resilient foundation that supports continuous operations—even under adverse conditions.
RTO vs. RPO FAQ
Below are common questions related to RTO, RPO, and their optimization.
How do we determine the right RTO and RPO for our business?
Start with a Business Impact Analysis (BIA) to understand how downtime or data loss affects each department. Quantify potential revenue impact and compliance risks. Engage both technical teams and business stakeholders to decide on maximum tolerable downtime (RTO) and data loss (RPO). Balance the cost of downtime/data loss against the cost of building more resilient systems.
Can we achieve zero RTO or zero RPO?
Zero RTO means no perceived downtime at all. In practice, you’d need highly available architectures with automatic failover to ensure continuous service.
Zero RPO means no data loss whatsoever. This typically requires synchronous replication to multiple locations so that every write is confirmed in real time.
Modern distributed SQL databases (like CockroachDB) approach near-zero RPO and RTO due to our architecture. Most businesses aim for low or near-zero metrics where justified.
How can we reduce our RTO and RPO?
For RTO (faster recovery): Use automated failover, maintain standbys, and script your recovery processes.
For RPO (less data loss): Increase backup frequency or adopt continuous replication to a standby. If your backups currently happen once a day, consider hourly or near-real-time snapshots.
Improving network bandwidth, verifying backup integrity, and ensuring offsite replication are additional ways to tighten both RTO and RPO.
Why is RTO testing and RPO testing important, and how often should we test?
RTO and RPO testing is crucial because theoretical objectives might not hold up under real conditions. By regularly testing:
You verify backups and failover processes work as intended.
You uncover hidden dependencies or bottlenecks.
Your team gains familiarity with emergency procedures, reducing mistakes during an actual outage.
Annual testing is common, though critical systems might warrant semi-annual or quarterly drills. Always reassess your results to see if they meet your RTO and RPO targets.
How do RTO and RPO relate to our SLA or compliance obligations?
Some regulations require specific recovery capabilities (e.g., within X hours for financial records). You may incorporate RTO and RPO into internal SLAs to set performance benchmarks for your IT department. Externally, customers might demand certain uptime or data protection guarantees. Documenting (and meeting) your RTO/RPO objectives helps maintain compliance, avoid fines, and build customer trust.
Should we tier our services for different RTO and RPO objectives?
Yes. It’s common to tier services based on criticality:
Tier 1: Minimal downtime and data loss (e.g., 15-minute RTO, near-zero RPO).
Tier 2: Moderate tolerance (e.g., 2–4 hours RTO, 1-hour RPO).
Tier 3: Extended downtime acceptable (e.g., 24 hours RTO, 12-hour RPO).
This ensures you invest heavily where it matters most. Testing each tier separately also helps refine your overall continuity plan.
Where should backups be stored to meet a good RPO?
Store backups offsite or in geographically separated cloud regions. On-premises backups alone may fail in regional disasters like floods or fires. Using a distributed backup service or multi-cloud approach further protects data. Regularly confirm that backups are valid and restorable, since corrupt or incomplete backups won’t meet any RPO goals.
Can distributed databases help with both RTO and RPO?
Yes. Distributed SQL solutions—such as CockroachDB—replicate data across multiple nodes (and often multiple regions). This approach:
Minimizes downtime (improving RTO) by automatically failing over if one node goes offline.
Reduces data loss (improving RPO) by maintaining near-real-time replicas that keep data current.
Such architectures are particularly valuable for organizations with global user bases or strict uptime/data integrity requirements.