Vector Database
We’re in the middle of a massive shift in how we build and interact with software. AI is no longer on the horizon — it’s here. From search and chatbots to recommendation engines and generative tools, intelligent applications are quickly becoming the new standard. And powering many of these experiences under the hood? Vectors.
But storing and searching high-dimensional vector data at scale — especially in real-time and across global deployments — poses unique challenges. Traditional databases weren’t built for this and that’s where vector databases come in.
What is a vector database?
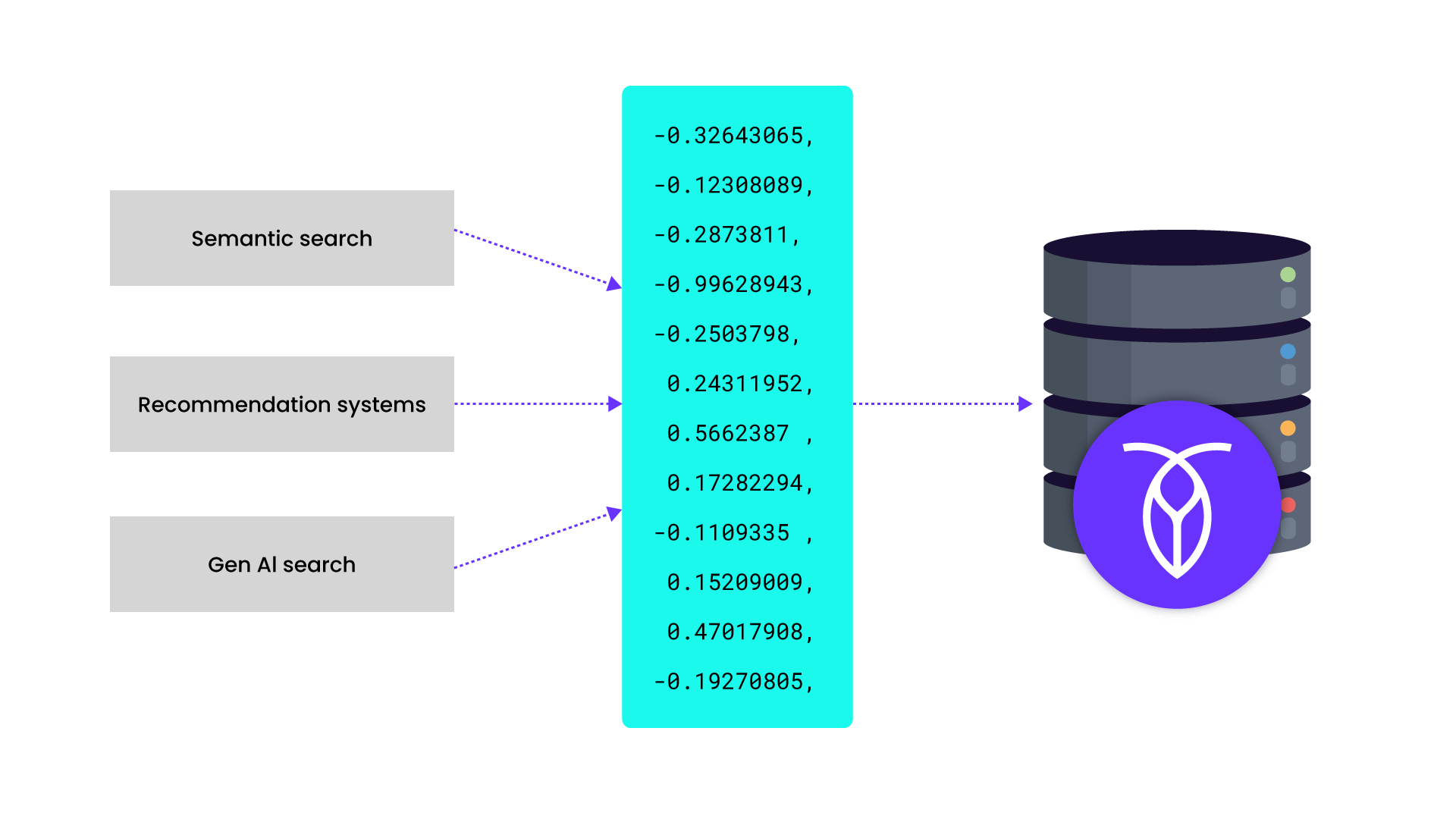
A vector database is a specialized system designed to store, index, and search through vector embeddings — numerical representations of unstructured data such as text, images, video, and audio.
Unlike traditional databases that retrieve data based on exact matches (e.g., WHERE name = 'Alice'), vector databases excel at similarity search. They find the items in your dataset that are most similar to a query, even if the words or data points aren’t an exact match.
In practical terms, that means a user who searches for “classical piano music” might also get results for “baroque keyboard compositions” or “instrumental piano playlists.” The magic is in the math: behind the scenes, these systems are comparing high-dimensional vectors to surface semantically similar content.
What are vector embeddings?
So where do these vectors come from?
Modern AI models — especially large language models (LLMs) and image classifiers — transform raw data into vector embeddings. These embeddings capture semantic relationships. Two similar pieces of content will have vectors that are “close” in a multi-dimensional space.
For example:
A sentence like "Let's meet for lunch." might live near "Want to grab a bite?"
An image of a cat might be close to other animal photos, but far from pictures of buildings
What makes a vector database different?
You might wonder: why can’t we just use PostgreSQL or Oracle?
While general-purpose databases can technically store vector data, they aren't optimized for similarity search or the scale and speed AI workloads demand.
Here’s how vector databases stand apart:
Approximate Nearest Neighbor (ANN) Search: Vector databases typically rely on ANN algorithms like HNSW or PQ to quickly find similar vectors (see our page on vector search to learn more). These trade perfect accuracy for speed—delivering relevant results in milliseconds.
High-Dimensional Indexing: Vectors often have hundreds or thousands of dimensions. Vector databases use optimized structures like trees or graphs to enable fast search at scale.
Real-Time Updates: Unlike many standalone vector indexes (e.g., FAISS), vector databases support dynamic data. You can insert, delete, or update vectors without rebuilding the entire index.
Metadata Filtering: Vector databases often support hybrid queries — filtering by metadata and vector similarity. This lets you do things like “find articles similar to this one, published after 2023, in the healthcare domain.”
Horizontal Scalability: As data grows, vector databases scale out to handle billions of vectors across distributed architectures.
Common use cases for vector databases
Vector databases are the backbone of many AI-powered systems. Here are some common applications:
Semantic search: Delivering more relevant results by understanding the meaning behind user queries.
Product recommendations: Suggesting items similar to those a customer viewed or purchased.
Chatbots & virtual assistants: Enabling long-term memory and contextual understanding in LLM-driven interfaces.
Fraud detection: Identifying patterns in transactions or behaviors that are semantically similar to known fraud or semantically dissimilar to non-fraudulent behavior.
Image, audio, or video retrieval: Searching media libraries based on content similarity instead of exact metadata.
How vector databases work
Let’s walk through a typical workflow.
Embedding generation: Use a model (like OpenAI’s
text-embedding-ada-002) to transform your unstructured data into vectors.Insert into database: Store the vectors in a vector database or a database with vector capabilities, along with optional metadata (e.g., timestamps, categories).
Query time: When a user submits a query, a vector embedding will be generated that represents the query, and that embedding will be used to search the database for similar entries based on their vectors.
Return results: Retrieve associated documents, items, or data points and present them to the user.
Behind the scenes, the system may:
Partition the index using a specific algorithm
Prune irrelevant vector spaces before scoring
Re-rank results with secondary similarity metrics
The result? Sub-second responses across massive datasets — without compromising relevance.
Scaling and deployment considerations
Scaling vector search isn’t trivial. AI-native apps often have high QPS (queries per second) and require millisecond response times — even across billions of records.
Leading vector databases address this with:
Distributed indexing: Vectors are automatically sharded and replicated across nodes.
Serverless options: Storage and compute are decoupled, enabling cost-efficient elastic scaling.
Multi-tenancy: Namespaces or collections support isolated, concurrent workloads.
These features become essential when deploying in production — especially across clouds, regions, or edge locations.
Serverless vector databases: The next evolution
Traditional vector databases often tie storage and compute together, leading to over-provisioning. Newer systems introduce serverless architectures with three core benefits:
Separation of compute and storage: Compute is spun up on demand, saving cost.
Cost efficiency: Only pay for what you use, ideal for variable workloads.
Strong consistency even when scaling: Updates propagate quickly, so new data is searchable in seconds.
This shift is critical for real-time, AI-native workloads like search augmentation or continuous learning systems. This is what modern businesses need: a modern data infrastructure.
CockroachDB: Relational database with vector capabilities
At Cockroach Labs, we believe developers shouldn’t have to choose between transactional correctness and intelligent search. Starting in 24.2 we introduced pgvector-compatible vector search.
It’s vector search, done the Cockroach way: resilient, scalable, and SQL-native.
With CockroachDB, you can:
Geo-partition your vector data for compliance and low latency
Scale across regions without operational complexity
Run complex hybrid queries like:
SELECT * FROM tickets WHERE type = 'password_reset' AND embedding <-> $query_vector < 0.3;
Choosing the right database
There’s no one-size-fits-all answer, but here are some factors to evaluate:
Query performance: Millisecond latency can be critical
Indexing flexibility: Support for IVF, etc.
Freshness: Can it handle real-time data updates
Hybrid filtering: Combine vector search with SQL or metadata
Scalability: Can it scale to billions of vectors?
Integration: Does it easily plug into your existing tech stack?
Final thoughts: Beyond search
Vector databases are more than just a backend for search bars.
They’re powering the next generation of applications that understand. And as AI continues to evolve — from LLM agents to contextual commerce — embedding-rich systems will become foundational infrastructure.
If you’re building for the future, now is the time to get familiar with vector databases. They represent a fundamental shift in how we model, store, and retrieve data in the age of AI.
Vector databases store and search vector embeddings—numerical representations of unstructured data.
They power semantic search, recommendations, chatbots, and other AI-native experiences.
Unlike traditional databases, they support high-dimensional indexing, ANN search, and hybrid filtering at scale.
Newer systems offer serverless architectures for elastic, cost-effective performance.
CockroachDB now supports
pgvector-compatible vector search, bringing together distributed SQL and intelligent search.
Get started with CockroachDB Cloud today. We’re offering $400 of free credits to help kickstart your CockroachDB journey, or get in touch today to learn more.
