Vector Search
In an age where users expect instant, accurate results across massive datasets, search technology needed to evolve to meet consumer needs. One of the most significant advancements driving this evolution has been vector search. But what exactly is vector search, and how does it differ from the traditional keyword-based approach?
What is Vector Search?
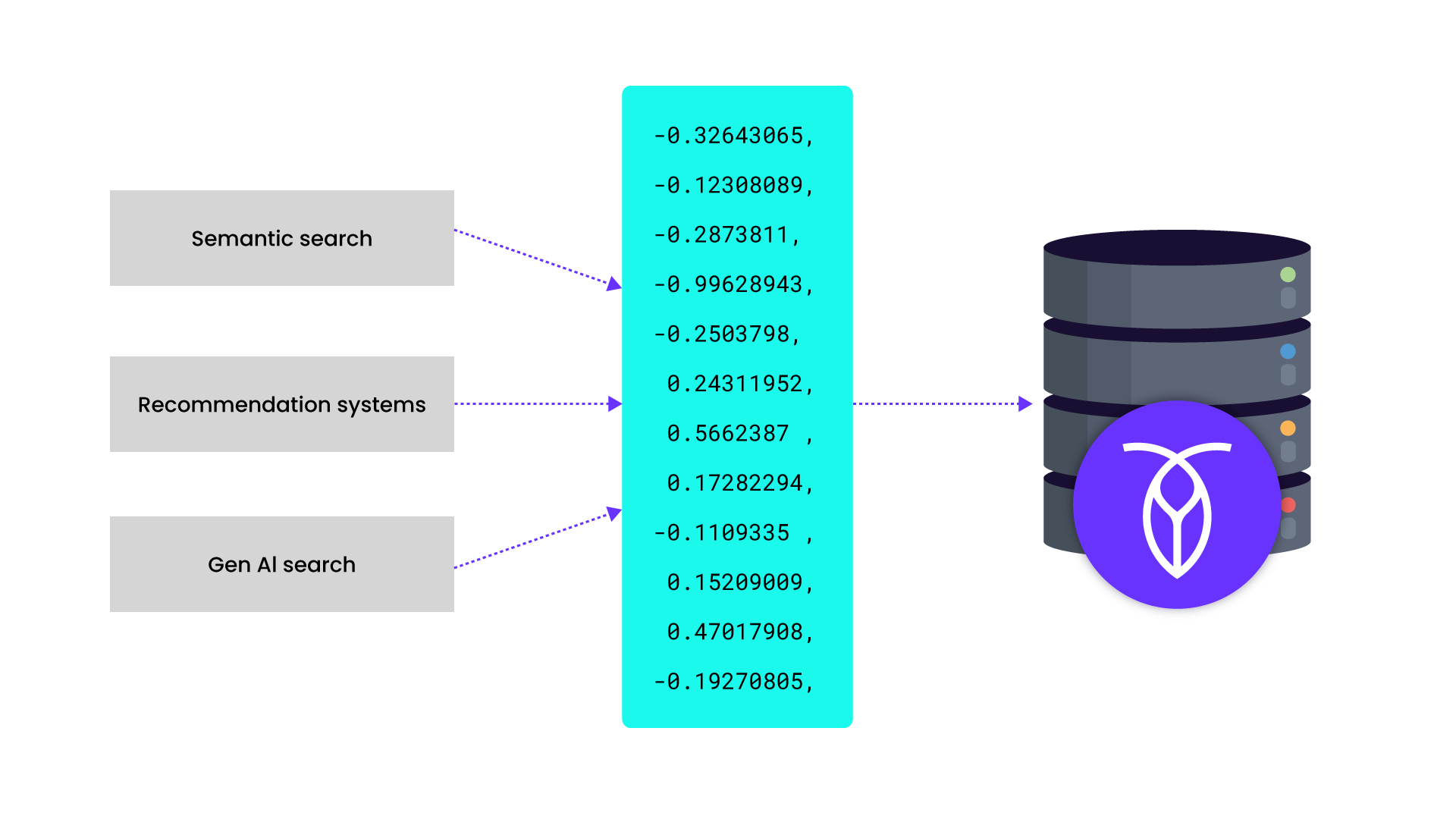
Vector search is a search technique that relies on mathematical representations of data, known as embeddings, rather than exact keyword matching. Where keyword search depends on matching literal terms (strings or substrings) within documents, vector search aims to understand the meaning behind the query.
For example, imagine looking up “soft sci-fi books with a literary writing style." A traditional keyword search might miss relevant results if those exact words aren’t present. A vector search, however, can measure and calculate the semantic meaning behind the search, and return results like Exhalation by Ted Chiang, Station Eleven by Emily St. John Mandel, and Never Let Me Go by Kazuo Ishiguro.
The ability to then navigate an entire corpus of texts using vector data and similarity search opens new doors for applications like recommendation systems, AI assistants, and discovery tools that prioritize relevance and context over surface-level text.
What is a vector?
In the simplest terms, a vector is a numerical representation of an object that can have many different dimensions. For example, let’s take the book Exhalation by Ted Chiang. A simplistic vector representation of the book may contain dimensions for page length (368), year of publication (2019), science fiction (1), short story collection (1), horror (0), self-help (0). So exhalation = [368, 2019, 1, 1, 0, 0] in this case. You can then imagine the book being a point in this 6-dimensional space.
Then if you had a whole library of books that you’ve converted into vectors using the same dimensions, you could analyze how close or far apart two books were.
How vector search works
At the core of vector search lies embeddings: numerical vectors that represent the meaning of text, images, or other data types. These embeddings are generated using machine learning models and large language models (LLMs) like Claude, Gemini or OpenAI’s GPTs. Each piece of data is then mapped into a high-dimensional array (or vector) where similar items are placed closer together.
NOTE: While ChatGPT is now part of common vernacular, ChatGPT is just the chat UI where you can utilize OpenAI’s different LLMs.
To find relevant results, vector search engines use different metrics to determine how close or far apart two documents are. For example, let’s say you’re still searching for books in a library, you can use natural language processing (NLP) to convert every book into a vector based on some number of dimensions. We then assume that if two books are very similar (let’s say Harry Potter & the Sorcerer’s Stone and Harry Potter & The Chamber of Secrets), then their vector representations will also be very close together. But books like War & Peace and Dr. Seuss’ Green Eggs & Ham would be rather far apart based on their vector representations.
Common metrics include:
Cosine similarity: Measures the angle between two vectors, emphasizing direction rather than magnitude.
Euclidean distance: Measures the straight-line distance between two points in vector space.
The result? Instead of asking, "Do these texts match?" vector search asks, "Are these texts close in meaning?"
Benefits of vector search
There are a number of benefits to utilizing vector search:
Semantic Understanding: Captures the underlying meaning of queries and content.
Improved Relevance: Delivers better, more nuanced results, especially for complex or ambiguous queries.
Scalability: Ideal for massive datasets where traditional indexing becomes brittle or inefficient.
Whether you're building a book recommender, AI playlist, legal document analyzer, or customer support chatbot, vector search can enable smarter, faster, and more intuitive interactions.
Use cases and applications of vector search
Vector search is powering innovation across industries:
Recommendation Systems: Suggesting similar products, articles, or videos based on user behavior or preferences.
Improving knowledge base tools: With semantic search, the results returned from customer service tools or internal company tooling can become more relevant and useful.
Retrieval-Augmented Generation (RAG): Enhancing large language models by providing additional data for use in response generation.
For example, in our vector search with pgvector and CockroachDB integration, developers can store, index, and query vector data from within CockroachDB. This makes it easier than ever to build AI-powered apps on a distributed SQL backbone.
Technical implementation of vector search
At its core, you're not just storing vectors—you’re building a system that can quickly compare vectors and return relevant results at scale. Here’s how that comes together in practice:
ANN (Approximate Nearest Neighbor) algorithms
Vector search relies heavily on Approximate Nearest Neighbor (ANN) algorithms to identify the most similar vectors without scanning the entire dataset. ANN makes trade-offs between precision and performance, delivering results that are “good enough” with far greater speed and efficiency than brute-force comparisons.
Two leading algorithms power modern vector systems:
Hierarchical Navigable Small World (HNSW): A graph-based approach that organizes vectors into layers, where higher layers offer rough approximations and lower layers refine results. HNSW is widely adopted because it delivers excellent accuracy at low latency.
Product Quantization (PQ): This technique compresses vectors into compact representations that speed up similarity computations. It’s especially valuable when dealing with billions of vectors, where memory usage becomes a bottleneck.
These algorithms form the backbone of scalable vector search — supporting everything from recommendation engines to LLM-enhanced applications.
Vector indexing techniques
Efficient vector search depends on indexing vectors in a way that minimizes search time while maximizing relevance. Unlike traditional B-tree or hash indexes used in relational databases, vector indexes must accommodate high-dimensional data and tolerate approximate results.
HNSW, for instance, builds a multi-layer graph where nodes represent vectors and edges connect them based on similarity. Traversing this structure narrows the search space dramatically. Other indexing methods, like inverted file indexing (IVF) and IVF-PQ, are also used in high-performance scenarios.
In short, the right index can make or break the performance of your vector system.
Database integration
Embeddings aren’t just for specialized ML platforms. Thanks to tools like pgvector, developers can now store and query vector data inside PostgreSQL-compatible databases, including CockroachDB.
This means no separate infrastructure, no complex data pipelines, and no reinventing the wheel. You write SQL, just as you would for structured data — only now, you can utilize vector data at the same time.
With CockroachDB, vector search gains all of the advantages of a leading distributed SQL database:
Scalability across regions: Data is automatically distributed across nodes, giving you horizontal scale and ultra-low-latency access worldwide.
Resilience built-in: CockroachDB is fault-tolerant by design, ensuring vector workloads remain online even in the face of hardware failures.
Familiar SQL interface: Developers use SQL they already know, with vector-specific syntax, so there’s no steep learning curve.
Whether you're building a personalized recommendation engine or a semantic search platform, CockroachDB makes it easier to deploy, scale, and maintain vector search alongside your operational workloads.
Challenges and considerations of vector search
Vector search brings powerful semantic capabilities, but it also introduces complex trade-offs. From compute requirements to data modeling, successful implementation means thinking beyond accuracy alone. Here are some of the biggest hurdles teams encounter:
Handling high-dimensional data
Vector embeddings can have hundreds or thousands of dimensions, each representing a subtle feature learned by a machine learning model. This richness is what enables semantic search — but it also makes indexing and retrieval far more challenging than working with flat keyword fields.
As dimensions increase, so does the "curse of dimensionality." Distances between vectors become less meaningful, search times grow, and index efficiency can degrade. Selecting the right dimensionality and pruning unnecessary features is crucial to performance.
Balancing speed and accuracy
ANN algorithms are fast—but not always precise. You’re trading off some accuracy for massive gains in throughput. That’s acceptable in most use cases (especially consumer-facing search), but not all. Mission-critical systems, like fraud detection or medical diagnostics, may require deterministic results. In other words, speed is great—until it costs you trust.
Infrastructure and resource requirements
Vector search isn’t “set and forget.” It requires modern infrastructure—especially when you’re working with real-time or large-scale applications.
Key considerations include:
Compute resources for training embeddings: Most models (like GPT, Claude, Gemini) require GPUs or high-performance CPUs to generate high-quality vector representations.
Storage and memory: Vector indexes can consume significant memory, especially when hosting millions of vectors. Efficient indexing and quantization are essential to stay within hardware limits.
Low-latency serving: End users expect fast results. That means your database or search layer must support millisecond response times—even at scale.
CockroachDB helps address these concerns by offloading infrastructure complexity. Its cloud-native, distributed architecture enables seamless scale without manual sharding, and its PostgreSQL compatibility means you can plug in vector search using existing tools and workflows.
Evolving models and schema management
As your ML models improve, so will your embeddings. That creates another challenge: versioning and updating vectors without disrupting the entire system. Vector dimensions may change. Similarity scoring may shift. Indexes may need to be rebuilt.
CockroachDB supports online schema changes, helping you evolve your schema—and your vectors—without downtime. This flexibility is critical when iteration is a core part of your product.
Vector search in today’s technology
As AI and machine learning continue to evolve, vector search is becoming a cornerstone of modern data architectures. We’re already seeing:
Deeper integration with LLMs for more context-aware and personalized experiences
Standardization efforts around formats, frameworks, and APIs
Hybrid search systems combining vector and keyword-based approaches for the best of both worlds
In short, vector search is no longer a fringe capability—it’s foundational for enterprises building intelligent, real-time applications.
To explore how CockroachDB enables native vector search capabilities with resilience and scale, check out our blog post or learn more about pgvector support.
Vector Search FAQ
What is vector search in simple terms?
Vector search is a modern search technique that finds results based on meaning rather than exact keywords. It uses mathematical vectors (called embeddings) to understand the context of queries and match them with semantically similar data.
How does vector search differ from traditional keyword search?
Unlike keyword search, which matches exact words, vector search uses machine learning to map words, phrases, or documents into high-dimensional vectors. It then finds results that are “close” in meaning, even if the exact words don’t match.
What are embeddings in vector search?
Embeddings are numerical representations of text, images, or other data types. These vectors capture the semantic meaning of the data and are used to compare and rank results by similarity rather than keyword overlap.
What are the main benefits of vector search?
The benefits of vector search include semantic understanding of queries, improved relevance for complex questions, and scalability across large datasets.
Where is vector search used today?
Vector search powers many applications, including product and content recommendation engines, chatbots and customer support tools, legal and technical document search and retrieval-augmented generation (RAG) systems.
What is an example of vector search in action?
If you search for “soft sci-fi books with a literary style,” a keyword search might miss relevant results. But a vector search could return books like Exhalation, Station Eleven, or Never Let Me Go—even if they don’t contain those exact words.
What algorithms power vector search?
Common vector search algorithms include HNSW (Hierarchical Navigable Small World), a graph-based search method offering high accuracy with low latency, and PQ (Product Quantization), which compresses vectors to reduce memory usage and improve search speed.
How does vector search work with databases like CockroachDB?
Vector data can be stored and queried within SQL databases using tools like pgvector. In v25.1, CockroachDB introduced pgvector-compatible vector search. With CockroachDB, developers can build AI-powered apps with horizontal scalability, fault tolerance, and a familiar SQL interface.
Is vector search better than keyword search?
Vector search is ideal for understanding natural language and context, while keyword search is better for exact matches or structured data. Many modern systems combine both for optimal performance.
What are the challenges of vector search?
Key challenges include managing high-dimensional data, balancing speed vs. accuracy, infrastructure and compute requirements, and keeping up with evolving ML models and embedding updates.
What is the future of vector search?
Vector search is becoming essential in AI-driven applications. It’s evolving through deeper integration with LLMs, hybrid systems that combine vector and keyword search, and standardization of tools and APIs.
