Once you've installed the official CockroachDB Docker image, it's simple to run an insecure multi-node cluster across multiple Docker containers on a single host, using Docker volumes to persist node data.
Before you begin
If you have not already installed the official CockroachDB Docker image, go to Install CockroachDB and follow the instructions under Use Docker.
Step 1. Create a bridge network
Since you'll be running multiple Docker containers on a single host, with one CockroachDB node per container, you need to create what Docker refers to as a bridge network. The bridge network will enable the containers to communicate as a single cluster while keeping them isolated from external networks.
docker network create -d bridge roachnet
We've used roachnet as the network name here and in subsequent steps, but feel free to give your network any name you like.
Step 2. Start the first node
docker run -d \
--name=roach1 \
--hostname=roach1 \
--net=roachnet \
-p 26257:26257 -p 8080:8080 \
-v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure
This command creates a container and starts the first CockroachDB node inside it. Let's look at each part:
docker run: The Docker command to start a new container.-d: This flag runs the container in the background so you can continue the next steps in the same shell.--name: The name for the container. This is optional, but a custom name makes it significantly easier to reference the container in other commands, for example, when opening a Bash session in the container or stopping the container.--hostname: The hostname for the container. You will use this to join other containers/nodes to the cluster.--net: The bridge network for the container to join. See step 1 for more details.-p 26257:26257 -p 8080:8080: These flags map the default port for inter-node and client-node communication (26257) and the default port for HTTP requests to the Admin UI (8080) from the container to the host. This enables inter-container communication and makes it possible to call up the Admin UI from a browser.-v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data": This flag mounts a host directory as a data volume. This means that data and logs for this node will be stored in${PWD}/cockroach-data/roach1on the host and will persist after the container is stopped or deleted. For more details, see Docker's Bind Mounts topic.cockroachdb/cockroach:v1.0.7 start --insecure: The CockroachDB command to start a node in the container in insecure mode.
Step 3. Add nodes to the cluster
At this point, your cluster is live and operational. With just one node, you can already connect a SQL client and start building out your database. In real deployments, however, you'll always want 3 or more nodes to take advantage of CockroachDB's automatic replication, rebalancing, and fault tolerance capabilities.
To simulate a real deployment, scale your cluster by adding two more nodes:
docker run -d \
--name=roach2 \
--hostname=roach2 \
--net=roachnet \
-v "${PWD}/cockroach-data/roach2:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1
docker run -d \
--name=roach3 \
--hostname=roach3 \
--net=roachnet \
-v "${PWD}/cockroach-data/roach3:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1
These commands add two more containers and start CockroachDB nodes inside them, joining them to the first node. There are only a few differences to note from step 2:
-v: This flag mounts a host directory as a data volume. Data and logs for these nodes will be stored in${PWD}/cockroach-data/roach2and${PWD}/cockroach-data/roach3on the host and will persist after the containers are stopped or deleted.--join: This flag joins the new nodes to the cluster, using the first container'shostname. Otherwise, allcockroach startdefaults are accepted. Note that since each node is in a unique container, using identical default ports won’t cause conflicts.
Step 4. Test the cluster
Now that you've scaled to 3 nodes, you can use any node as a SQL gateway to the cluster. To demonstrate this, use the docker exec command to start the built-in SQL shell in the first container:
docker exec -it roach1 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.
Run some basic CockroachDB SQL statements:
CREATE DATABASE bank;
CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);
INSERT INTO bank.accounts VALUES (1, 1000.50);
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
Exit the SQL shell on node 1:
\q
Then start the SQL shell in the second container:
docker exec -it roach2 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.
Now run the same SELECT query:
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
As you can see, node 1 and node 2 behaved identically as SQL gateways.
When you're done, exit the SQL shell on node 2:
\q
Step 5. Monitor the cluster
When you started the first container/node, you mapped the node's default HTTP port 8080 to port 8080 on the host. To check out the Admin UI for your cluster, point your browser to that port on localhost, i.e., http://localhost:8080.
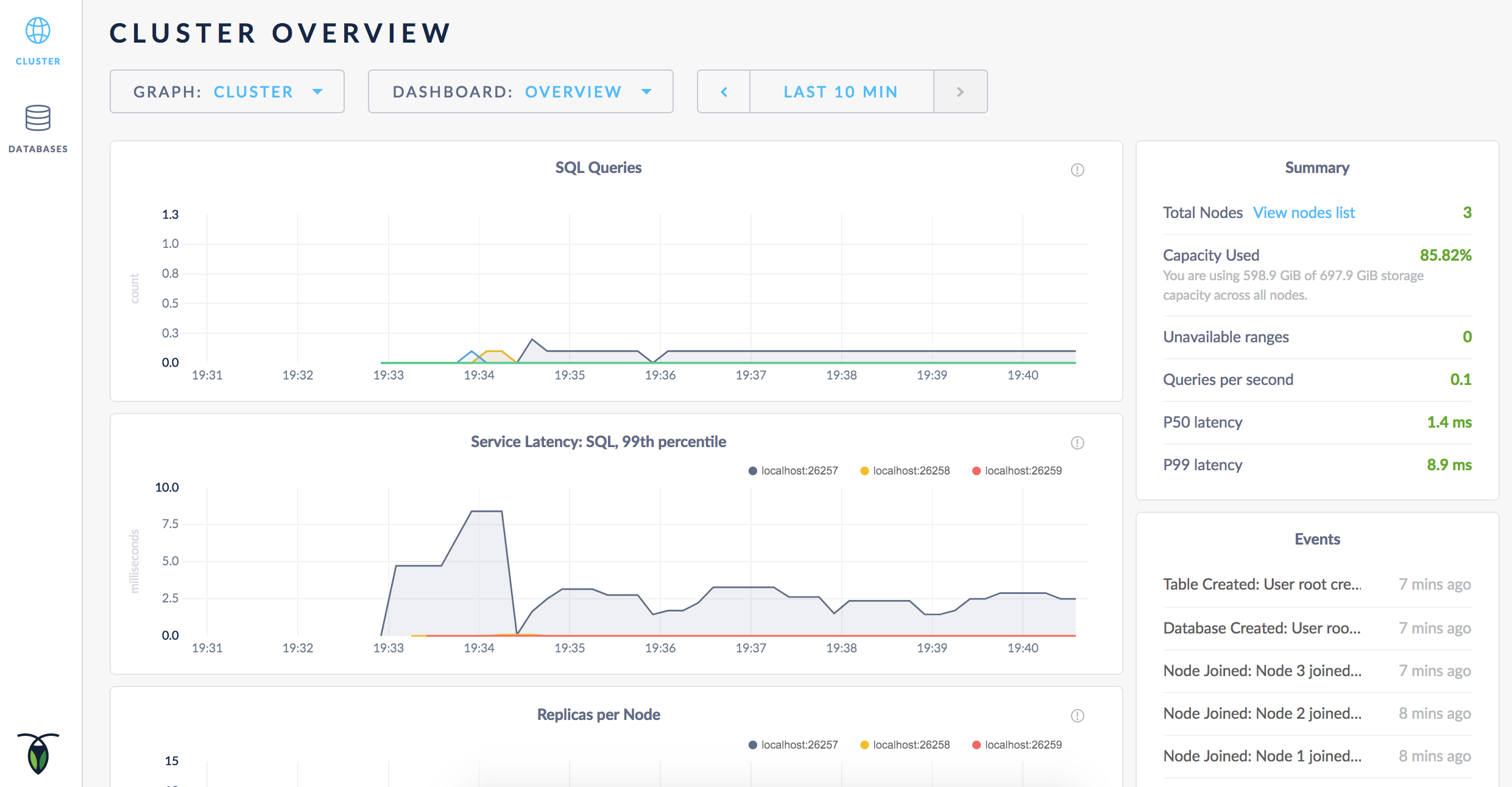
As mentioned earlier, CockroachDB automatically replicates your data behind-the-scenes. To verify that data written in the previous step was replicated successfully, scroll down to the Replicas per Store graph and hover over the line:
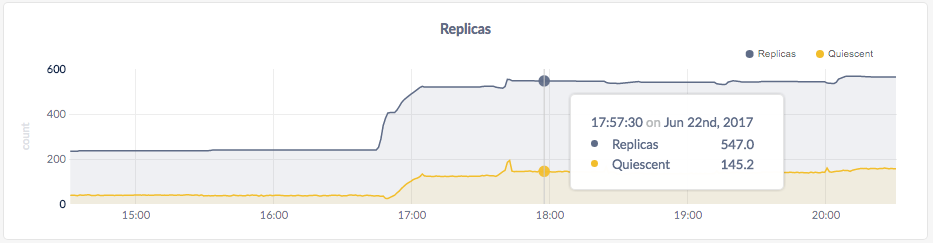
The replica count on each node is identical, indicating that all data in the cluster was replicated 3 times (the default).
Step 6. Stop the cluster
Use the docker stop and docker rm commands to stop and remove the containers (and therefore the cluster):
docker stop roach1 roach2 roach3
docker rm roach1 roach2 roach3
If you do not plan to restart the cluster, you may want to remove the nodes' data stores:
rm -rf cockroach-data
Before you begin
If you have not already installed the official CockroachDB Docker image, go to Install CockroachDB and follow the instructions under Use Docker.
Step 1. Create a bridge network
Since you'll be running multiple Docker containers on a single host, with one CockroachDB node per container, you need to create what Docker refers to as a bridge network. The bridge network will enable the containers to communicate as a single cluster while keeping them isolated from external networks.
docker network create -d bridge roachnet
We've used roachnet as the network name here and in subsequent steps, but feel free to give your network any name you like.
Step 2. Start the first node
docker run -d \
--name=roach1 \
--hostname=roach1 \
--net=roachnet \
-p 26257:26257 -p 8080:8080 \
-v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure
This command creates a container and starts the first CockroachDB node inside it. Let's look at each part:
docker run: The Docker command to start a new container.-d: This flag runs the container in the background so you can continue the next steps in the same shell.--name: The name for the container. This is optional, but a custom name makes it significantly easier to reference the container in other commands, for example, when opening a Bash session in the container or stopping the container.--hostname: The hostname for the container. You will use this to join other containers/nodes to the cluster.--net: The bridge network for the container to join. See step 1 for more details.-p 26257:26257 -p 8080:8080: These flags map the default port for inter-node and client-node communication (26257) and the default port for HTTP requests to the Admin UI (8080) from the container to the host. This enables inter-container communication and makes it possible to call up the Admin UI from a browser.-v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data": This flag mounts a host directory as a data volume. This means that data and logs for this node will be stored in${PWD}/cockroach-data/roach1on the host and will persist after the container is stopped or deleted. For more details, see Docker's Bind Mounts topic.cockroachdb/cockroach:v1.0.7 start --insecure: The CockroachDB command to start a node in the container in insecure mode.
Step 3. Add nodes to the cluster
At this point, your cluster is live and operational. With just one node, you can already connect a SQL client and start building out your database. In real deployments, however, you'll always want 3 or more nodes to take advantage of CockroachDB's automatic replication, rebalancing, and fault tolerance capabilities.
To simulate a real deployment, scale your cluster by adding two more nodes:
docker run -d \
--name=roach2 \
--hostname=roach2 \
--net=roachnet \
-v "${PWD}/cockroach-data/roach2:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1
docker run -d \
--name=roach3 \
--hostname=roach3 \
--net=roachnet \
-v "${PWD}/cockroach-data/roach3:/cockroach/cockroach-data" \
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1
These commands add two more containers and start CockroachDB nodes inside them, joining them to the first node. There are only a few differences to note from step 2:
-v: This flag mounts a host directory as a data volume. Data and logs for these nodes will be stored in${PWD}/cockroach-data/roach2and${PWD}/cockroach-data/roach3on the host and will persist after the containers are stopped or deleted.--join: This flag joins the new nodes to the cluster, using the first container'shostname. Otherwise, allcockroach startdefaults are accepted. Note that since each node is in a unique container, using identical default ports won’t cause conflicts.
Step 4. Test the cluster
Now that you've scaled to 3 nodes, you can use any node as a SQL gateway to the cluster. To demonstrate this, use the docker exec command to start the built-in SQL shell in the first container:
docker exec -it roach1 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.
Run some basic CockroachDB SQL statements:
CREATE DATABASE bank;
CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);
INSERT INTO bank.accounts VALUES (1, 1000.50);
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
Exit the SQL shell on node 1:
\q
Then start the SQL shell in the second container:
docker exec -it roach2 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.
Now run the same SELECT query:
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
As you can see, node 1 and node 2 behaved identically as SQL gateways.
When you're done, exit the SQL shell on node 2:
\q
Step 5. Monitor the cluster
When you started the first container/node, you mapped the node's default HTTP port 8080 to port 8080 on the host. To check out the Admin UI for your cluster, point your browser to that port on localhost, i.e., http://localhost:8080.
As mentioned earlier, CockroachDB automatically replicates your data behind-the-scenes. To verify that data written in the previous step was replicated successfully, scroll down to the Replicas per Store graph and hover over the line:
The replica count on each node is identical, indicating that all data in the cluster was replicated 3 times (the default).
Step 6. Stop the cluster
Use the docker stop and docker rm commands to stop and remove the containers (and therefore the cluster):
docker stop roach1 roach2 roach3
docker rm roach1 roach2 roach3
If you do not plan to restart the cluster, you may want to remove the nodes' data stores:
rm -rf cockroach-data
Before You Begin
If you have not already installed the official CockroachDB Docker image, go to Install CockroachDB and follow the instructions under Use Docker.
Step 1. Create a bridge network
Since you'll be running multiple Docker containers on a single host, with one CockroachDB node per container, you need to create what Docker refers to as a bridge network. The bridge network will enable the containers to communicate as a single cluster while keeping them isolated from external networks.
PS C:\Users\username> docker network create -d bridge roachnetWe've used roachnet as the network name here and in subsequent steps, but feel free to give your network any name you like.
Step 2. Start the first node
<username> in the -v flag with your actual username.PS C:\Users\username> docker run -d `
--name=roach1 `
--hostname=roach1 `
--net=roachnet `
-p 26257:26257 -p 8080:8080 `
-v "//c/Users/<username>/cockroach-data/roach1:/cockroach/cockroach-data" `
cockroachdb/cockroach:v1.0.7 start --insecureThis command creates a container and starts the first CockroachDB node inside it. Let's look at each part:
docker run: The Docker command to start a new container.-d: This flag runs the container in the background so you can continue the next steps in the same shell.--name: The name for the container. This is optional, but a custom name makes it significantly easier to reference the container in other commands, for example, when opening a Bash session in the container or stopping the container.--hostname: The hostname for the container. You will use this to join other containers/nodes to the cluster.--net: The bridge network for the container to join. See step 1 for more details.-p 26257:26257 -p 8080:8080: These flags map the default port for inter-node and client-node communication (26257) and the default port for HTTP requests to the Admin UI (8080) from the container to the host. This enables inter-container communication and makes it possible to call up the Admin UI from a browser.-v "//c/Users/<username>/cockroach-data/roach1:/cockroach/cockroach-data": This flag mounts a host directory as a data volume. This means that data and logs for this node will be stored inUsers/<username>/cockroach-data/roach1on the host and will persist after the container is stopped or deleted. For more details, see Docker's Bind Mounts topic.cockroachdb/cockroach:v1.0.7 start --insecure: The CockroachDB command to start a node in the container in insecure mode.
--cache flag in the start command.Step 3. Add nodes to the cluster
At this point, your cluster is live and operational. With just one node, you can already connect a SQL client and start building out your database. In real deployments, however, you'll always want 3 or more nodes to take advantage of CockroachDB's automatic replication, rebalancing, and fault tolerance capabilities.
To simulate a real deployment, scale your cluster by adding two more nodes:
<username> in the -v flag with your actual username.# Start the second container/node:
PS C:\Users\username> docker run -d `
--name=roach2 `
--hostname=roach2 `
--net=roachnet `
-v "//c/Users/<username>/cockroach-data/roach2:/cockroach/cockroach-data" `
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1
# Start the third container/node:
PS C:\Users\username> docker run -d `
--name=roach3 `
--hostname=roach3 `
--net=roachnet `
-v "//c/Users/<username>/cockroach-data/roach3:/cockroach/cockroach-data" `
cockroachdb/cockroach:v1.0.7 start --insecure --join=roach1These commands add two more containers and start CockroachDB nodes inside them, joining them to the first node. There are only a few differences to note from step 2:
-v: This flag mounts a host directory as a data volume. Data and logs for these nodes will be stored inUsers/<username>/cockroach-data/roach2andUsers/<username>/cockroach-data/roach3on the host and will persist after the containers are stopped or deleted.--join: This flag joins the new nodes to the cluster, using the first container'shostname. Note that since each node is in a unique container, using identical default ports won’t cause conflicts.
Step 4. Test the cluster
Now that you've scaled to 3 nodes, you can use any node as a SQL gateway to the cluster. To demonstrate this, use the docker exec command to start the built-in SQL shell in the first container:
PS C:\Users\username> docker exec -it roach1 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.Run some basic CockroachDB SQL statements:
CREATE DATABASE bank;
CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);
INSERT INTO bank.accounts VALUES (1, 1000.50);
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
Exit the SQL shell on node 1:
\q
Then start the SQL shell in the second container:
PS C:\Users\username> docker exec -it roach2 ./cockroach sql --insecure
# Welcome to the cockroach SQL interface.
# All statements must be terminated by a semicolon.
# To exit: CTRL + D.Now run the same SELECT query:
SELECT * FROM bank.accounts;
+----+---------+
| id | balance |
+----+---------+
| 1 | 1000.5 |
+----+---------+
(1 row)
As you can see, node 1 and node 2 behaved identically as SQL gateways.
When you're done, exit the SQL shell on node 2:
\q
Step 5. Monitor the cluster
When you started the first container/node, you mapped the node's default HTTP port 8080 to port 8080 on the host. To check out the Admin UI for your cluster, point your browser to that port on localhost, i.e., http://localhost:8080.
As mentioned earlier, CockroachDB automatically replicates your data behind-the-scenes. To verify that data written in the previous step was replicated successfully, scroll down to the Replicas per Store graph and hover over the line:
The replica count on each node is identical, indicating that all data in the cluster was replicated 3 times (the default).
Step 6. Stop the cluster
Use the docker stop and docker rm commands to stop and remove the containers (and therefore the cluster):
# Stop the containers:
PS C:\Users\username> docker stop roach1 roach2 roach3
# Remove the containers:
PS C:\Users\username> docker rm roach1 roach2 roach3If you do not plan to restart the cluster, you may want to remove the nodes' data stores:
Remove-Item C:\Users\username> cockroach-data -recurseWhat's Next?
- Learn more about CockroachDB SQL and the built-in SQL client
- Install the client driver for your preferred language
- Build an app with CockroachDB
- Explore core CockroachDB features like automatic replication, rebalancing, and fault tolerance
