
Resilient deployments aim for continuity in database operations to protect from data loss and downtime. To maintain resiliency, it is necessary to build deployments with high availability and disaster recovery coverage.
- High availability: Continuously access data without interruption even in the presence of failures or disruptions to maximize uptime.
- Disaster recovery: Recover from a major incident or disaster to minimize downtime and data loss.
To build resilient cluster deployments, CockroachDB provides both built-in replication for high availability and disaster recovery features for coverage during unplanned incidents.
For a practical guide on how CockroachDB replicates, distributes, and rebalances data, refer to the Replication and Rebalancing demo.
Resilience strategy
As you evaluate CockroachDB's disaster recovery features, consider your organization's requirements for the amount of tolerable data loss and the acceptable length of time to recover.
- Recovery Point Objective (RPO): The maximum amount of data loss (measured by time) that an organization can tolerate.
- Recovery Time Objective (RTO): The maximum length of time it should take to restore normal operations following an outage.
For example, when you use backups:
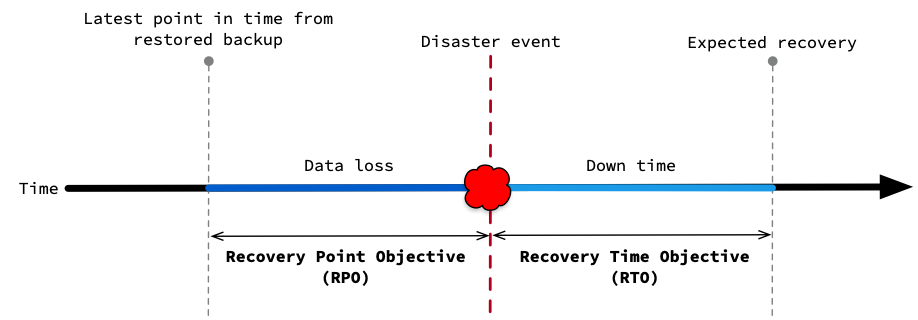
For a comparison of CockroachDB resiliency features, refer to the following sections:
Choose a high availability strategy
CockroachDB uses synchronous, built-in replication to create and distribute copies of data, ensuring consistency across the data copies. The database can tolerate nodes going offline without service interruption, whether in a single-region or multi-region cluster.
| Single-region replication (synchronous) | Multi-region replication (synchronous) | |
|---|---|---|
| RPO | 0 seconds | 0 seconds |
| RTO | Zero RTO Potential increased latency for 1-9 seconds |
Zero RTO Potential increased latency for 1-9 seconds |
| Write latency | Region-local write latency p50 latency < 5ms (for multiple availability zones in us-east1) |
Cross-region write latency p50 latency > 50ms (for a multi-region cluster in us-east1, us-east-2, us-west-1) |
| Recovery | Automatic | Automatic |
| Hardware cost | 1x Networking between availability zones |
1x Networking between datacenters |
| Minimum regions | 1 | 3 |
| Fault tolerance | Zero RPO node, availability zone failures | Zero RPO node, availability zone failures, region failures |
For details on designing your cluster topology for high availability with replication, refer to the Disaster Recovery Planning page.
Choose a disaster recovery strategy
CockroachDB is designed to recover automatically; however, building backups or physical cluster replication into your disaster recovery planning is an important part of a resilient deployment.
| Point in time backup & restore | Physical cluster replication (asynchronous) | |
|---|---|---|
| RPO | >=5 minutes | 10s of seconds |
| RTO | Minutes to hours, depending on data size and number of nodes | Seconds to minutes, depending on cluster size |
| Write latency | No impact | No impact |
| Recovery | Manual restore | Manual failover |
| Hardware cost | 1x + S3-like storage & networking | 2x + networking between datacenters |
| Minimum regions | 1 | 2 |
| Fault tolerance | Not applicable | Zero RPO node, availability zone, region failure with loss up to RPO |
Was this helpful?