
Resilient deployments aim for continuity in database operations to protect from data loss and downtime. CockroachDB's built-in Raft replication and fault tolerance provide high availability. However, it is still important to design a disaster recovery plan to recover from unforeseen incidents to minimize downtime and data loss.
As you evaluate CockroachDB's disaster recovery features, consider your organization's requirements for the amount of tolerable data loss and the acceptable length of time to recover.
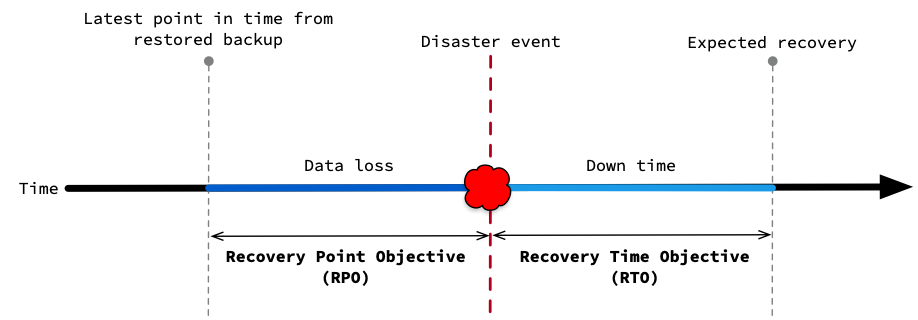
- Recovery Point Objective (RPO): The maximum amount of data loss (measured by time) that an organization can tolerate.
- Recovery Time Objective (RTO): The maximum length of time it should take to restore normal operations following an outage.
When you use backups, RPO and RTO can be visualized as follows:
For an overview of resiliency features in CockroachDB, refer to Data Resilience.
Choose a disaster recovery strategy
CockroachDB is designed to recover automatically; however, building backups or physical cluster replication into your disaster recovery planning protects against unforeseen incidents.
| Point-in-time backup & restore | Physical cluster replication (asynchronous) | |
|---|---|---|
| RPO | >=5 minutes | 10s of seconds |
| RTO | Minutes to hours, depending on data size and number of nodes | Seconds to minutes, depending on cluster size, and time of failover |
| Write latency | No impact | No impact |
| Recovery | Manual restore | Manual failover |
| Fault tolerance | Not applicable | Zero RPO node, availability zone within a cluster, region failures with loss up to RPO in a two-region (or two-datacenter) setup |
| Minimum regions to achieve fault tolerance | 1 | 2 |
